This is the draft website for Programming Historian lessons under review. Do not link to these pages.
For the published site, go to https://programminghistorian.org
Contenidos
- Introducción
- Introducción rápida al aprendizaje automático
- Guía sobre la visión artificial utilizando aprendizaje profundo
- Conclusión Parte 1
- Apéndice : Un experimento no científico que evalúa el aprendizaje por transferencia
- Notas finales
Introducción
Mientras la mayoría de historiadores estarían de acuerdo que la representación (moderna) está formada por medios multimodales, como por ejemplo medios como los periódicos, televisión o internet,que combinan varios modos, el área de humanidades digitales e historia digital quedan dominadas por medios textuales y por la gran variedad de métodos válidos para su análisis1. Los historiadores modernos han sido frecuentemente tratados por ser negligentes con las formas no textuales de representación, y los humanistas digitales en particular, se han dedicado a explorar fuentes textuales. Muchos han utilizado el Reconocimiento óptico de caracteres (ROC); una tecnología que permite la lectura de textos digitalizados, junto con técnicas del stemming del campo del Procesamiento de Lenguaje Natural (PLN), para analizar los contenidos y el contexto del lenguaje en documentos grandes. La combinación de estos dos ha formado la innovación metodológica del área de la historia digital: la habilidad de “leer a distancia” grandes cuerpos y descubrir patrones a gran escala2.
En los últimos 10 años, el campo de la visión artificial -la cual busca alcanzar un alto nivel de comprensión de imágenes usando técnicas computacionales-, ha evolucionado rápidamente. Por ejemplo, los modelos de visión artificial pueden localizar e identificar gente, animales y miles de objetos incluidos en imágenes con alta precisión. Este avance tecnológico promete hacer lo mismo para el reconocimiento de imágenes que la combinación de técnicas ROC/PLN ha hecho por los textos. En términos sencillos, la visión artificial abre la puerta para el análisis a gran escala de archivos digitales que no han sido explorados hasta el momento: los millones de imágenes en libros digitalizados, periódicos, revistas y documentos históricos. De esta manera, las investigaciones de una disciplina como la historia serán capaces de explorar el lado visual del giro digital de la investigación histórica.3
Estas dos lecciones presentan ejemplos de como las técnicas de visión artificial pueden ser aplicadas para analizar grandes volúmenes de información histórica visual de manera novedosa y cómo entrenar modelos propios de la visión artificial. Así mismo, identificará los contenidos de imágenes y las clasificará de acuerdo a una categoría —dos tareas enfocadas en características visuales— de técnicas de visión artificial que también pueden ser usadas para visualizar la similitud o diferencias estilísticas entre imágenes.
Se debe resaltar, que las técnicas de visión artificial les da a los investigadores un set de cambios teóricos y metodológicos. Primero, cualquier aplicación de técnicas de visión artificial a corpus históricos deben iniciarse desde la formulación cuidadosa de una pregunta histórica y, como resultado, incluir una discusión de la escala. En resumen: ¿por qué es importante que respondamos a la pregunta y por qué las técnicas de visión artificial son necesarias para responderla?
Segundo, tomando en cuenta los debates de los sesgos en el campo del aprendizaje automático45, el cual trabaja la cuestión de los prejuicios en el aprendizaje automático, los historiadores deben ser conscientes del hecho que las técnicas de visión artificial pueden arrojar luces sobre ciertas partes del corpus visual, pero también podrían pasar por alto identificar, desclasificar, clasificar erróneamente o incluso oscurecer otras partes.
Como historiadores, somos conscientes de que estudiamos el pasado desde nuestro propio tiempo, y por lo tanto cualquier aplicación de técnicas de visión artificial deben incluir una discusión de posibles “sesgos históricos”. Debido a que la mayoría de modelos de visión artificial son entrenados con datos contemporáneos, corremos el riesgo de proyectar el tiempo específico de sesgos de estos datos en archivos históricos. Explorar completamente la pregunta del sesgo está fuera del alcance de estas dos lecciones, pero esto es algo que debemos tener presente.
Objetivos de la lección
Las dos lecciones tienen los siguientes objetivos:
- Proporcionar una introducción al Aprendizaje Profundo de los métodos de visión artificial para la investigación en humanidades. El Aprendizaje Profundo es una rama del aprendizaje automático (algo que discutiremos con mas detalle en las lecciones)
- Dar una visión general de los pasos implicados en el entrenamiento de un modelo de aprendizaje profundo -Discutir algunas de las especificaciones del uso del aprendizaje profundo / visión artificial para la investigación en humanidades
- Ayudarte a decidir si el aprendizaje profundo puede ser una herramienta útil para ti.
Estas dos lecciones no tienen como objetivos:
- Reproducir otras introducciones genéricas del aprendizaje profundo, aunque cubre algunas temáticas
- Cubrir cada detalle del aprendizaje profundo y de la visión artificial, debido a que son temas amplios y no es posible cubrirlos aquí.
Habilidades sugeridas
-
Para seguir estas lecciones te recomendamos tener conocimientos básicos de Python u otro lenguaje de programación . Específicamente entender como usar las variables, indexar y tener familiaridad usando métodos de librerías externas.
-
Uso básico de Jupyter Notebooks para correr el código en un notebook. Si desconoces los notebooks, puedes encontrar en la lección introductoria de Programming Historian Introduction to Jupyter Notebooks un recurso útil.
-
Hay un uso de las librerías externas de Python en esta lección pero no es necesario conocimiento previo de este lenguaje porque los pasos de para usar estas librerías serán explicados cuando sean utilizados.
Organización de la Lección
Sugerimos que te aproximes a las dos lecciones en dos etapas:
- Primero, leer los materiales de esta página para familiarizarse con los conceptos clave y el flujo de trabajo general para entrenar un modelo de visión artificial
- Segundo, correr el código en Jupyter Notebook para cada lección de Kaggle (ver mas adelante)
En estas dos lecciones usaremos el aprendizaje profundo para aproximarnos a la visión artificial. El proceso de configurar un ambiente para hacer aprendizaje profundo se ha vuelto fácil pero aún puede ser complejo. Tratamos de mantener la configuración lo mas simple posible y recomendamos una ruta rápida para empezar a correr el código de la lección.
Notebooks
Las dos lecciones de Programming Historian están disponibles en Jupyter Notebook. Recomendamos ejecutar el código a través de los notebooks adjuntos, los cuales funcionan bien para la exploración que utilizaremos.
Ejecución de los notebooks
Puedes utilizar los notebooks de la lección de varias maneras. Te recomendamos utilizar las instrucciones de configuración en la “nube” en lugar de configurar localmente. Esto es por las siguientes razones:
- El proceso de configuración para utilizar aprendizaje profundo en un entorno en la nube puede ser mucho más sencillo que configurar localmente. Muchos portátiles y computadores personales no disponen de este tipo de hardware y el proceso de instalación de los controladores de software necesarios puede ser demandante.
- El código de esta lección se ejecutará mucho más rápido cuando se cuente con un tipo específico de Unidad de Procesamiento Gráfico (GPU). Esto permitirá trabajar de forma interactiva con los modelos y los resultados.
- Las GPUs son más eficientes energéticamente para algunas tareas comparadas con las Unidades Centrales de Procesamiento (CPU), incluyendo el tipo de tareas que trabajaremos en estas dos lecciones.
Kaggle
Kaggle es un sitio web que contiene conjuntos de datos, organiza competencias de ciencia de datos y presenta varios recursos de aprendizaje. Kaggle también aloja notebooks de Jupyter, incluyendo notebooks con acceso a GPUs.
Para ejecutar el código de la lección en Kaggle necesitarás:
- Crear una cuenta en Kaggle (tendrás que proporcionar un número de teléfono), o iniciar sesión si ya tienes cuenta.
- Ir a https://www.kaggle.com/code/davanstrien/progamming-historian-deep-learning-pt1. Los datos utilizados en esta lección se encuentran en estos notebooks.
- Haz clic en el botón “Editar/Edit” para crear una copia del notebook.
- Establece la “Opción de acelerador/Accelerator option” en “GPU”. Encontrarás esta opción en la sección “Configuración/Settings”. Kaggle cambia ocasionalmente el tipo de GPU disponible. Seleccionar una única GPU será suficiente para esta lección.
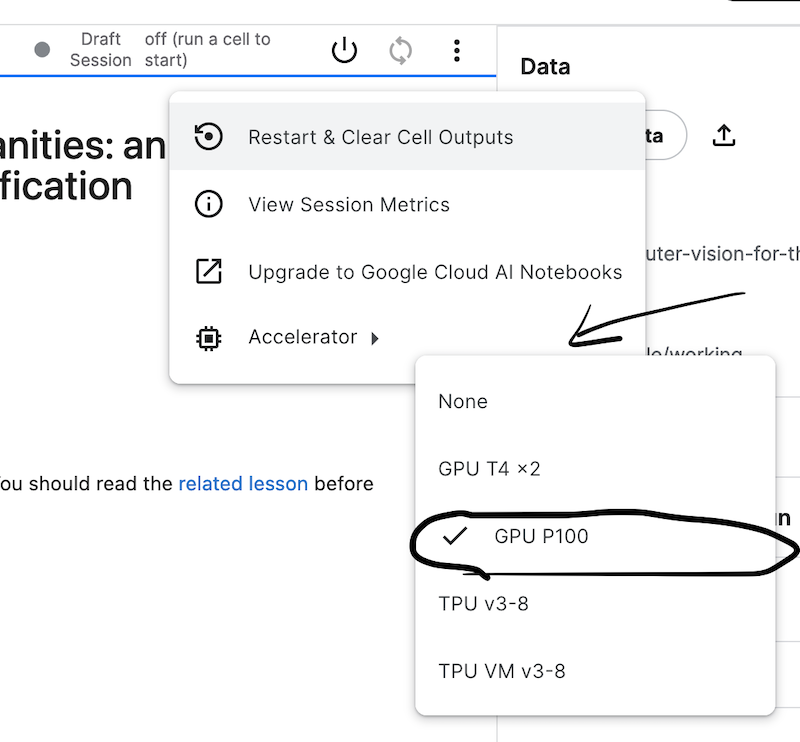
Figura 1: Menú de configuración de los cuadernos en Kaggle
- La interfaz de los notebooks en Kaggle te será familiar si has usado Jupyter notebooks anteriormente. Para ejecutar una celda que contenga código, haz clic en el botón con la flecha hacia la derecha o, si la celda está seleccionada, utiliza “Mayús + Intro / Shift + Enter”.
- Recuerda cerrar la sesión cuando hayas terminado de trabajar con los notebooks. Puedes hacer esto, accediendo al menú desplegable “Ejecutar/Run” situado en la parte superior del notebook de Kaggle.
Kaggle tiene más documentación acerca el uso de sus notebooks, así como guías sobre el uso eficiente de la GPU.
Configuración local
Si no quieres utilizar las instrucciones de configuración en la nube, puedes seguir las instrucciones para configurar esta lección localmente.
Introducción rápida al aprendizaje automático
Antes de continuar con el primer ejemplo práctico, es útil revisar brevemente lo que significa el “aprendizaje automático”. El objetivo del aprendizaje automático es permitir que los computadores “aprendan” de los datos en vez de ser programados explícitamente para hacer algo. Por ejemplo, si queremos filtrar el correo spam, hay diferentes maneras de hacerlo. Una de ellas puede ser leer ejemplos de correos electrónicos “spam” y “no spam” para ver si podemos identificar señales que indiquen que un correo es spam. Podríamos, por ejemplo, encontrar palabras clave que nos indiquen que un email es spam. Entonces podríamos escribir un programa que haga algo como esto para cada correo electrónico recibido:
count number spam_words in email:
if number spam_words >= 10:
email = spam
En cambio, un método de aprendizaje automático entrenaría un algoritmo de aprendizaje automático con ejemplos etiquetados de correos electrónicos que son “spam” o “no son spam”. Este algoritmo podría, tras una exposición repetida de ejemplos, “aprender” patrones que indicarían el tipo de correo. Este es un ejemplo de “aprendizaje supervisado”, un proceso en el cual un algoritmo es expuesto a datos etiquetados, y es en lo que se centrará esta lección. Existen diferentes enfoques para gestionar este proceso de entrenamiento, algunos de los cuales se cubrirán en estas dos lecciones. Otro tipo de aprendizaje automático que no requiere ejemplos etiquetados es el “aprendizaje no supervisado”.
Existen ventajas y desventajas en el aprendizaje automático. Algunas ventajas en nuestro ejemplo del correo electrónico incluyen no tener que identificar manualmente qué indica si un correo electrónico es spam o no. Esto es útil cuando las señales pueden ser sutiles o difíciles de detectar. Si las características de los mensajes de spam cambiaran en el futuro, no necesitarías reescribir todo el programa, sino que podrías reentrenar el modelo con nuevos ejemplos. Algunas desventajas incluye el requerimiento para ejemplos etiquetados, ya que su creación puede llevar mucho tiempo. Una de las principales limitaciones de los algoritmos de aprendizaje automático es que puede ser difícil entender cómo han tomado una decisión, por ejemplo, por qué un correo electrónico ha sido etiquetado como spam o no. Las implicaciones de esto varían dependiendo de que tanto “poder” se le da al algoritmo en un sistema. Por ejemplo, el impacto negativo de un algoritmo que toma decisiones automatizadas sobre una solicitud de préstamo será mucho mayor que el de un algoritmo que hace una recomendación poco útil sobre una película de un servicio de streaming.
Entrenamiento de un modelo de clasificación de imágenes
Ahora que tenemos un panorama general del aprendizaje automático, pasaremos a nuestro primer ejemplo usando el aprendizaje profundo para la visión artificial. En este ejemplo, construiremos un clasificador de imágenes que asigna imágenes a una de las dos categorías basadas en datos de entrenamiento etiquetados.
Los Datos: Clasificación de imágenes de periódicos históricos
En estas dos lecciones, trabajaremos con un conjunto de datos derivado del “Newspaper Navigator”. Este conjunto de datos consta de contenido visual extraído de 16.358.041 páginas de periódicos históricos digitalizados extraídos de la colección Chronicling America de la Biblioteca del Congreso.
Un modelo de visión artificial asignó a estas imágenes una de siete categorías, incluyendo fotografías y anuncios. Los datos de Newspaper Navigator se crearon utilizando un modelo de aprendizaje profundo de detección de objetos. Este modelo se entrenó con anotaciones de páginas de Chronicling America de la época de la Primera Guerra Mundial, incluidas anotaciones hechas por voluntarios como parte del proyecto de crowdsourcing Beyond Words[6].
Si deseas obtener más información sobre cómo se creó este conjunto de datos, puedes leer el artículo de la revista que describe este trabajo o consultar el repositorio de GitHub que contiene el código y los datos de entrenamiento. Nosotros no vamos a replicar este modelo. En su lugar, utilizaremos el resultado de este modelo como punto de partida para crear los datos que utilizaremos en este tutorial. Entendiendo que los datos del Newspaper Navigator son predichos por un modelo de aprendizaje automático, estos tendrán errores y por ahora, aceptaremos que los datos con los que trabajamos son imperfectos. Un cierto grado de imperfección y error suele ser el precio que debemos pagar si queremos trabajar con colecciones “a escala” utilizando métodos computacionales.
Clasificación de anuncios de periódicos
Para nuestra primera aplicación de aprendizaje profundo, nos concentraremos en clasificar imágenes predecidas como anuncios (recuerda que estos datos se basan en predicciones y tendrán algunos errores). Específicamente, trabajaremos con una muestra de imágenes de anuncios que abarcan los años 1880-5.
Detección de anuncios que contienen ilustraciones
Si observas las imágenes de los anuncios, observarás que algunos de ellos contienen solo texto, mientras que otros contienen algún tipo de ilustración.
Un anuncio con una ilustración6:

Figura 2: Un ejemplo de anuncio ilustrado
Un anuncio sin ilustración7:

Figura 3: Ejemplo de anuncio sólo texto
Nuestro clasificador será entrenado para predecir a cual categoría pertenece la imagen de un anuncio. Podríamos utilizarlo para ayudar a automatizar la búsqueda de anuncios con imágenes para su posterior análisis “manual”. Alternativamente, podemos utilizar este clasificador directamente para cuantificar cuántos anuncios contienen ilustraciones en un determinado año y descubrir si este número ha cambiado con el tiempo, junto con la influencia de otros factores como el lugar de publicación. El uso previsto del modelo influirá en las etiquetas con las que decidas entrenarlo y en el modo en que decidas evaluar si un modelo funciona lo suficientemente bien. Profundizaremos en estos temas a lo largo de estas dos lecciones.
Una introducción a la biblioteca fastai
fastai es una biblioteca de Python para el aprendizaje profundo “que proporciona a los profesionales altos niveles de componentes que pueden proporcionar rápida y fácilmente resultados de estados de última generación en dominios estándar de aprendizaje profundo, y proporciona a los investigadores bajos niveles de componentes que pueden mezclarse y combinarse para construir nuevos enfoques”[9]. La biblioteca ha sido desarrollada por fast.ai (ten en cuenta el punto), una organización de investigación que busca hacer más accesible el aprendizaje profundo. Además de la biblioteca fastai, fast.ai también organiza cursos gratuitos y lleva a cabo investigaciones.
Hay varias razones por las que se eligió fastai para este tutorial:
- Se centra en hacer accesible el aprendizaje profundo, particularmente a través del diseño de la API de la librería.
- Facilita el uso de técnicas que no requieren una gran cantidad de datos o recursos computacionales.
- Muchas de las mejores prácticas se implementan como “valores predeterminados”, ayudando a obtener buenos resultados.
- Hay diferentes niveles en los que se puede interactuar con la biblioteca, dependiendo de cuánto se necesiten cambiar los detalles del nivel inferior.
- La biblioteca está basada en PyTorch, lo que hace relativamente sencillo utilizar el código existente. Aunque este tutorial se centra en fastai, muchas de las técnicas mostradas son también aplicables a otros frameworks.
Creación de un clasificador de imágenes en fastai
La siguiente sección describirá los pasos necesarios para crear y entrenar un modelo de clasificación que permita predecir si un anuncio es sólo de texto o también contiene una ilustración. Brevemente, los pasos serán: 1. Cargar los datos 2. Crear un modelo 3. Entrenar el modelo
Estos pasos serán cubiertos rápidamente; no te preocupes si sientes que no estás siguiendo todo en esta sección, la lección mostrará lo que está sucediendo con más detalles cuando lleguemos a la sección del flujo de trabajo de un problema de visión artificial.
Lo primero que haremos es importar los módulos necesarios de la librería fastai. En este caso, importamos vision.all ya que estamos trabajando en una tarea de visión artificial.8
from fastai.vision.all import *
También importaremos Matplotlib, una librería para crear visualizaciones en Python. Le pediremos a Matplotlib que utilice un estilo diferente utilizando el método style.use.
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('seaborn')
Carga de los datos
Hay varias formas de cargar los datos utilizando la librería fastai. Los datos de los anuncios consisten en una carpeta que contiene los archivos de imagen, y un archivo CSV que contiene una columna con las rutas de las imágenes, además de la etiqueta asociada:
| file | label | |—|—| | kyu_joplin_ver01_data_sn84037890_00175045338_1900060601_0108_007_6_97.jpg | text-only |
Existen varias formas de cargar este tipo de datos utilizando fastai. En este ejemplo utilizaremos ImageDataLoaders.from_csv. Como su nombre indica, el método from_csv de ImagDataLoaders carga los datos desde un archivo CSV. Tenemos que decirle a fastai algunas cosas sobre cómo cargar los datos para utilizar este método:
- La ruta a la carpeta donde están almacenadas las imágenes y el archivo CSV
- Las columnas del archivo CSV que contienen las etiquetas
- Un ‘item transform’ Resize() para redimensionar todas las imágenes a un tamaño estándar
Crearemos una variable ad_data que se utilizará para guardar los parámetros de cómo cargar estos datos:
ad_data = ImageDataLoaders.from_csv(
path="ads_data/", # root path to csv file and image directory
csv_fname="ads_upsampled.csv/", # the name of our csv file
folder="images/", # the folder where our images are stored
fn_col="file", # the file column in our csv
label_col="label", # the label column in our csv
item_tfms=Resize(224, ResizeMethod.Squish), # resize imagesby squishing so they are 224x224 pixels
seed=42, # set a fixed seed to make results more reproducible
)
Es importante asegurarse de que los datos se han cargado correctamente. Una forma de comprobarlo rápidamente es utilizar el método show_batch() en nuestros datos. Esto mostrará las imágenes y las etiquetas asociadas de una muestra de nuestros datos. Los ejemplos que obtengas serán ligeramente diferentes a los de aquí.
ad_data.show_batch()

Figura 4: La salida de show_batch
Esta es una forma útil de comprobar que las etiquetas y los datos se han cargado correctamente. Aquí puedes ver que las etiquetas (text-only e illustration) se han asociado correctamente con la forma en que queremos clasificar estas imágenes.
Creación del modelo
Ahora que fastai sabe cómo cargar los datos, el siguiente paso es crear un modelo con ellos. Para crear un modelo adecuado de visión artificial utilizaremos la función vision_learner. Esta función creará una ‘Red Neuronal Convolucional’, un tipo de modelo de aprendizaje profundo utilizado a menudo para aplicaciones de visión artificial. Para usar esta función necesitas pasar (como mínimo):
- Los datos que el modelo utilizará como datos de entrenamiento
- El tipo de modelo que deseas utilizar
Esto ya es suficiente para crear un modelo de visión artificial en fastai, pero puedes también querer pasar algunas métricas para realizar un seguimiento durante el entrenamiento. Esto te permite tener una mejor idea de qué tan bien tu modelo está realizando la tarea en la que lo estás entrenando. En este ejemplo, utilizaremos accuracy como métrica.
Creemos este modelo y asignémoslo a una nueva variable learn:
learn = cnn_learner(
ad_data, # the data the model will be trained on
resnet18, # the type of model we want to use
metrics=accuracy, # the metrics to track
)
Entrenamiento del modelo
Aunque hemos creado un modelo vision_learner, no hemos entrenado el modelo todavía. Esto se hace utilizando el método de ajuste fit. El entrenamiento es el proceso que le permite al modelo de visión artificial “aprender” como predecir las etiquetas correctas para los datos. Hay diferentes maneras de entrenar (ajustar) este modelo. Para empezar, utilizaremos el método fine_tune. En este ejemplo, lo único que pasaremos al método fine_tune es el número de épocas/epochs para entrenar. Cada pasada por el conjunto de datos es un ‘epoch’. La cantidad de tiempo que el modelo toma para entrenar dependerá de dónde se está ejecutando este código y los recursos disponibles. De nuevo, cubriremos los detalles de todos estos componentes más adelante.
learn.fine_tune(5)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.971876 | 0.344096 | 0.860000 | 00:06 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.429913 | 0.394812 | 0.840000 | 00:05 |
| 1 | 0.271772 | 0.436350 | 0.853333 | 00:05 |
| 2 | 0.170500 | 0.261906 | 0.913333 | 00:05 |
| 3 | 0.125547 | 0.093313 | 0.946667 | 00:05 |
| 4 | 0.107586 | 0.044885 | 0.980000 | 00:05 |
Cuando ejecutes este método, verás una barra de progreso que muestra cuánto tiempo se ha entrenando el modelo y el tiempo restante estimado. También verás una tabla que muestra alguna otra información sobre el modelo, como nuestra métrica de precisión rastreada. Puedes ver que en este ejemplo obtuvimos una precisión superior al 90%. Cuando ejecutes el código tú mismo, la puntuación que obtengas puede ser ligeramente diferente.
Resultados
Mientras que las técnicas de aprendizaje profundo son percibidas por necesitar grandes cantidades de datos y de una gran capacidad informática, nuestro ejemplo muestra que para muchas aplicaciones basta con bases de datos más pequeñas. Aunque en este ejemplo podríamos haber utilizado otros enfoques, el objetivo no era mostrar la mejor solución con este particular conjunto de datos, sino dar una idea de lo que es posible hacer con un número limitado de ejemplos etiquetados.
Guía sobre la visión artificial utilizando aprendizaje profundo
Ahora que tenemos una visión general del proceso vamos a entrar en más detalles sobre cómo funciona este proceso.
El flujo de trabajo de un problema de visión artificial supervisado
Esta sección iniciará con algunos de los pasos implicados en el proceso de creación de un modelo de visión artificial basado en el aprendizaje profundo. Este proceso implica una serie de pasos, algunos de los cuales están directamente relacionados con el entrenamiento de modelos. Una ilustración general de un proceso de aprendizaje automático supervisado podría tener este aspecto:

Figura 5: Ilustración general de un proceso de aprendizaje automático supervisado
Podemos ver que hay bastantes pasos antes y después de la fase de entrenamiento del modelo del flujo de trabajo. Antes de empezar a entrenar un modelo, necesitamos datos. En esta lección, los datos de la imagen ya han sido preparados, por lo que no necesitas preocuparte por este paso. Sin embargo, cuando pases a utilizar la visión por artificial para tus propias preguntas de investigación, es poco probable que exista un conjunto de datos para tu caso exacto. Como resultado, tendrás que crearlos tu mismo. El proceso de acceso a los datos variará en función del tipo de imágenes con las que estés interesado trabajar y de dónde se encuentren. Algunas colecciones patrimoniales ponen a disposición del público colecciones masivas de imágenes, mientras otras sólo permiten acceder a las imágenes a través de un “visor”. La creciente adopción de la norma IIIF también está simplificando el proceso de trabajar con imágenes conservadas por distintas instituciones.
Una vez que se dispone de una colección de imágenes con las que trabajar, el siguiente paso (si se utiliza el aprendizaje supervisado) será crear algunas etiquetas para estos datos y entrenar el modelo. Este proceso se explica con más detalle a continuación. Una vez se ha entrenado el modelo, obtendremos algunas predicciones. Estas predicciones se “puntúan” utilizando una serie de métricas potenciales, algunas de las cuales exploraremos con más detalle en la segunda parte de la lección de esta lección.
Una vez que un modelo ha alcanzado una puntuación satisfactoria, sus resultados pueden utilizarse para una serie de actividades “interpretativas”. Una vez tenemos las predicciones de un modelo de aprendizaje profundo, existen diferentes opciones sobre qué hacer con ellas. Nuestras predicciones podrían informar directamente decisiones automatizadas (por ejemplo, dónde se van a mostrar las imágenes dentro de una colección web), pero es más probable que esas predicciones sean leídas por un humano para su posterior análisis. Este será particularmente el caso, si el uso previsto es explorar fenómenos históricos.
Entrenamiento del modelo
Si nos enfocamos en el aprendizaje profundo del flujo de trabajo, ¿cómo es el proceso de entrenamiento?

Figura 6: El bucle de entrenamiento del aprendizaje profundo
Un resumen general del loop de entrenamiento para el aprendizaje supervisado consiste en: empezar con algunas imágenes y etiquetas, hacer alguna preparación para que la entrada sea adecuada para un modelo de aprendizaje profundo, pasar los datos a través del modelo, hacer predicciones para las etiquetas, calcular lo equivocadas que son las predicciones, actualizar el modelo con el objetivo de generar mejores predicciones la próxima vez. Este proceso se repite varias veces. Durante este loop se obtienen métricas que le permiten a la persona que entrena el modelo, evaluar su rendimiento. Obviamente, esto es un resumen general. Veamos cada paso del loop uno por uno. A pesar que la siguiente sección mostrará estos pasos usando código, no te preocupes demasiado si no lo comprendes todo al principio.
Datos de entrada
Tenemos imágenes y etiquetas como datos de entrada. Aunque el aprendizaje profundo se inspira en como funciona la cognición humana, la forma como un computador ‘ve’ es muy distinta a la de un ser humano. Todos los modelos de aprendizaje profundo toman números como datos de entrada. Las imágenes se almacenan en el computador como una matriz de valores de píxeles, siendo un proceso relativamente sencillo para los modelos de visión artificial. Junto a estas imágenes, tenemos una etiqueta o etiquetas asociadas a cada imagen. De nuevo, éstas se representan como números dentro del modelo.
¿Cuántos datos?
A menudo se cree que se necesitan grandes cantidades de datos para entrenar un modelo de aprendizaje profundo útil, pero no siempre es así. Supongamos que si estás intentando utilizar el aprendizaje profundo para resolver un problema, tienes suficientes datos para justificar que no utilices un enfoque manual. El verdadero problema es la cantidad de datos etiquetados que tienes. No es posible dar una respuesta definitiva a la pregunta “¿cuántos datos?”, ya que la cantidad de datos de entrenamiento necesarios depende de una amplia gama de factores. Hay varias cosas que se pueden hacer para reducir la cantidad de datos de entrenamiento necesarios, algunas de las cuales trataremos en esta lección. Lo mejor será crear unos datos de entrenamiento iniciales y ver qué tal funciona el modelo con ellos. Esto te dará una idea de si es posible o no abordar un problema. Además, el proceso de anotar los datos es valioso en sí mismo. Para una tarea de clasificación sencilla, puede que sea posible empezar a evaluar si vale la pena desarrollar un modelo con cientos de ejemplos etiquetados (aunque a menudo necesitarás más para entrenar un modelo sólido).
Preparación de segmentos
Generalmente no es posible pasar todos nuestros datos al modelo de una sola vez al utilizar el aprendizaje profundo. Por el contrario, los datos se dividen en segmentos. Cuando se utiliza una GPU, los datos se cargan en la memoria de la GPU por segmentos. El tamaño de este segmento puede influir en el proceso de entrenamiento, pero es comúnmente determinado por los recursos computacionales disponibles. La razón por la que utilizamos una GPU para entrenar nuestro modelo es que casi siempre será más rápido entrenar un modelo en una GPU que en una CPU debido a su capacidad para realizar muchos cálculos en paralelo. Antes que podamos crear un segmento y cargarlo en la GPU, normalmente tenemos que asegurarnos de que todas las imágenes tienen el mismo tamaño. Esto permite a la GPU ejecutar las operaciones efectivamente. Una vez preparado un segmento, podríamos hacer algunas transformaciones adicionales en nuestras imágenes para reducir la cantidad de datos de entrenamiento necesarios.
Creación de un modelo
Una vez que hemos preparado los datos para ser cargados de uno en uno, los pasamos a nuestro modelo. Ya vimos un ejemplo de modelo en nuestro primer ejemplo resnet18. La arquitectura de un modelo de aprendizaje profundo define cómo se pasan los datos y las etiquetas a través de un modelo. En estas dos lecciones, nos concentraremos en un tipo específico de aprendizaje profundo que utiliza ‘Redes Neuronales Convolucionales’ (CNN).
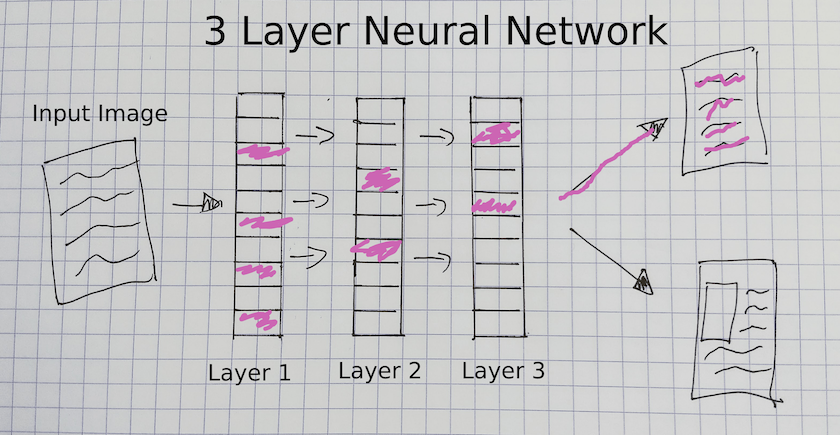
Figura 7: Una red neuronal de tres capas
Este diagrama ofrece una visión general de los distintos componentes de un modelo CNN. En este tipo de modelo, una imagen pasa por varias capas antes de predecir una etiqueta de salida para la imagen (“solo texto” en este diagrama). Las capas de este modelo se actualizan durante el entrenamiento para que “aprendan” qué características de una imagen predicen una etiqueta en particular. Por ejemplo, la CNN que hemos entrenado sobre los anuncios actualizará los parámetros conocidos como “pesos/weights” de cada capa, lo que produce una representación de la imagen que es útil para predecir si un anuncio tiene una ilustración o no.
Tensorflow playground es una herramienta útil para ayudar a desarrollar una intuición sobre cómo estas capas capturan diferentes características de los datos de entrada, y cómo estas características, pueden usarse para clasificar los datos de entrada de diferentes maneras. El poder de las CNN y del aprendizaje profundo proviene de la capacidad de estas capas para codificar patrones muy complicados de los datos.[11] Sin embargo, a menudo puede ser un reto actualizar los pesos de manera efectiva.
¿Utilizar un modelo existente?
Al considerar cómo crear nuestro modelo, tenemos varias opciones sobre qué hacer. Una opción es utilizar un modelo existente que ya haya sido entrenado para una tarea concreta. Por ejemplo, puedes utilizar el modelo YOLO. Este modelo ha sido entrenado para predecir los cuadros delimitadores de distintos tipos de objetos en una imagen. Aunque éste podría ser un punto de partida válido, este enfoque tiene una serie de limitaciones a la hora de trabajar con material histórico, o para cuestiones de humanidades en general. En primer lugar, los datos con los que se han entrenado estos modelos pueden ser muy diferentes de los que utilizas. Esto puede impactar al rendimiento del modelo en sus datos y dar lugar a sesgos hacia las imágenes en los datos que son parecidos a los datos de entrenamiento. Otro problema es que si se utiliza un modelo existente sin ninguna modificación, sólo se pueden identificar las etiquetas con las que se entrenó el modelo original.
Aunque es posible definir directamente un modelo CNN definiendo las capas que se desean incluir en la arquitectura del modelo, normalmente no se empieza por ahí. Es mejor empezar con una arquitectura del modelo existente. El desarrollo de nuevas arquitecturas de modelos es un área activa de investigación, en la que los modelos demuestran ser adecuados para una serie de tareas y datos. A menudo, estos modelos son implementados en marcos de aprendizaje automático. Por ejemplo, la biblioteca Hugging Face Transformers implementa muchas de las arquitecturas de modelos más populares.
A menudo, queremos un balance entre empezar de cero y aprovechar los modelos existentes. En estas doslecciones, mostramos un enfoque que utiliza arquitecturas de modelos existentes y modifica ligeramente el modelo para permitirle predecir nuevas etiquetas. Este modelo luego es entrenado con nuevos datos para que se adapte mejor a la tarea que queremos que realice. Se trata de una técnica conocida como “aprendizaje por transferencia”, que se explorará en la sección de Apéndices de esta lección.
Entrenamiento
Una vez el modelo se ha creado y los datos preparados, inicia el proceso de entrenamiento. Veamos los pasos del entrenamiento:
- A un modelo se le pasan datos y etiquetas, un segmento cada vez. Cada vez que se pasa un conjunto de datos completo por un modelo se denomina “epoch” (época). El número de epochs utilizadas para entrenar un modelo es una de las variables que tendrás que controlar.
- El modelo realiza predicciones para estas etiquetas basándose en las entradas dadas, utilizando un conjunto de pesos internos. En este modelo CNN, los pesos están contenidos dentro de las capas de la CNN.
- El modelo calcula que tan equivocadas son las predicciones, comparándolas con las predicciones de las etiquetas reales. Una “función de pérdida” se utiliza para calcular que tan “equivocado” estaba el modelo en sus predicciones.
- El modelo cambia los parámetros internos para intentar hacerlo mejor la próxima vez. La función de pérdida del paso anterior devuelve un “valor de pérdida”, a menudo denominado como “pérdida”, la cual es usada por el modelo para actualizar los pesos. Una “tasa de aprendizaje” es usada para determinar cuánto debe actualizarse un modelo en función de la pérdida calculada. Ésta es otra de las variables importantes que pueden ser manipuladas durante el proceso de entrenamiento. En la En la segunda parte de la lección, veremos una forma poderosa para tratar de identificar una tasa de aprendizaje adecuada para tu modelo.
Validación de datos
Cuando entrenamos un modelo de aprendizaje profundo, normalmente lo hacemos para realizar predicciones sobre nuevos datos que no se ven que no contienen etiquetas. Por ejemplo, es posible que queramos utilizar nuestro clasificador de anuncios en todas las imágenes de un periodo de tiempo concreto para contar cuántos anuncios de cada tipo (ilustrados o no) aparecen en este corpus. Por lo tanto, no queremos un modelo que sólo aprenda a clasificar bien los datos de entrenamiento que se le muestran. En consecuencia, casi siempre utilizamos algún tipo de “datos de validación”. Son datos que se utilizan para comprobar que los pesos que un modelo está aprendiendo en los datos de entrenamiento también se aplican a los nuevos datos. En el entrenamiento, los datos de validación sólo se utilizan para “probar” las predicciones del modelo. El modelo no los utiliza directamente para actualizar los pesos. Esto ayuda a garantizar que no terminemos “sobreajustando” nuestro modelo.
El “sobreajuste” se refiere cuando un modelo se vuelve exitoso haciendo predicciones sobre los datos de entrenamiento, pero estas predicciones no se generalizan más allá de los datos de entrenamiento. En efecto, el modelo está “recordando” los datos de entrenamiento mas que de aprender características más generales para hacer predicciones correctas sobre nuevos datos. Un conjunto de validación evita que esto ocurra, permitiendo ver lo bien que funciona el modelo con datos de los que no ha aprendido. A veces, se hace una división adicional de los datos que se utilizan para hacer predicciones sólo al final del entrenamiento de un modelo. Esto se conoce a menudo como conjunto de prueba. Un conjunto de prueba se utiliza para validar el rendimiento del modelo en competencias de ciencia de datos, como las organizadas en Kaggle, y para validar el rendimiento de los modelos creados por socios externos. Esto ayuda a garantizar la solidez de un modelo en situaciones donde la validación de los datos ha sido deliberada o accidentalmente utilizada para “jugar” con el funcionamiento de un modelo.
Aprendizaje por transferencia
Para nuestro primer clasificador de anuncios, utilizamos el método fine_tune() en nuestro learner durante el entrenamiento. ¿Qué hace esto? Habrás visto que la barra de progreso mostraba dos partes. El primer epoch estaba entrenando las capas finales del modelo, después las capas inferiores del modelo también se entrenaban. Esta es una forma en la que podemos hacer aprendizaje por transferencia en fastai. La importancia del aprendizaje por transferencia ya se ha tratado en las secciones anteriores. Como recordatorio, el aprendizaje por transferencia utiliza los “pesos” que un modelo ha aprendido previamente sobre otra tarea en una nueva tarea. En el caso de la clasificación de imágenes, esto generalmente significa que un modelo ha sido entrenado en un conjunto de datos mas grande. Con frecuencia, este conjunto de datos de entrenamiento previo es ImageNet.
ImageNet es una gran base de datos de imágenes muy utilizada en la investigación de visión artificial. ImageNet contiene actualmente “14.197.122” imágenes con más de 20.000 etiquetas diferentes. Este conjunto de datos se utiliza como punto de referencia para que los investigadores en visión artificial comparen sus enfoques. Las cuestiones éticas relacionadas con las etiquetas y la producción de ImageNet se exploran en The Politics of Images in Machine Learning Training Sets, de Crawford y Paglen4
¿Por qué es útil el aprendizaje por transferencia?
Como hemos visto, el aprendizaje por transferencia funciona utilizando un modelo entrenado en una tarea para realizar otra nueva tarea. En nuestro ejemplo, utilizamos un modelo entrenado en ImageNet para clasificar imágenes de periódicos digitalizados del siglo XIX. Puede parecer extraño que el aprendizaje por transferencia funcione en este caso, ya que las imágenes con las que estamos entrenando nuestro modelo son muy diferentes a las imágenes de ImageNet. Aunque ImageNet tiene una categoría para periódicos, en su mayoría se trata de imágenes de periódicos en el contexto de entornos cotidianos, en lugar de imágenes recortadas de las páginas de los periódicos. Entonces, ¿por qué sigue siendo útil utilizar un modelo entrenado en ImageNet para una tarea que tiene etiquetas e imágenes diferentes a las de ImageNet?
Cuando vimos el diagrama de un modelo CNN vimos que está formado por diferentes capas. Estas capas crean representaciones de la imagen de entrada que recogen características particulares de una imagen para predecir una etiqueta. ¿Cuáles son esas características? Pueden ser características “básicas”, como formas simples. O pueden ser características visuales más complejas, como los rasgos faciales. Se han desarrollado varias técnicas para ayudar a visualizar las distintas capas de una red neuronal. Estas técnicas han descubierto que las primeras capas de una red neuronal tienden a aprender características más “básicas”, por ejemplo, aprenden a detectar formas básicas como círculos o líneas, mientras que las capas más avanzadas de la red contienen filtros que codifican características visuales más complejas, como los ojos. Muchas de estas características captan propiedades visuales útiles para muchas tareas. Empezar con un modelo que ya es capaz de detectar características en las imágenes ayudará a detectar características que son importantes para la nueva tarea, ya que es probable que estas nuevas características sean variantes de las características que el modelo ya conoce en lugar de otras nuevas.
Cuando se crea un modelo en la biblioteca fastai utilizando el método vision_learner, se utiliza una arquitectura existente como “cuerpo” del modelo. Las capas más profundas añadidas se conocen como la “cabeza” del modelo. El cuerpo utiliza por defecto los pesos (parámetros) aprendidos a través del entrenamiento en ImageNet. La parte de la “cabeza” toma la salida del cuerpo como entrada antes de pasar a una capa final que se crea para ajustarse a los datos de entrenamiento que se pasan al vision_learner. El método fine_tune primero entrena sólo la parte de la cabeza del modelo, es decir, las últimas capas del modelo, antes de “descongelar” las capas inferiores. Cuando estas capas están “descongeladas”, los pesos del modelo se actualizan a través del proceso mencionado anteriormente en el “entrenamiento”. También podemos controlar de forma más activa cuánto entrenamos las distintas capas del modelo, algo que veremos a medida que avancemos en el proceso completo del entrenamiento de un modelo de aprendizaje profundo.
Experimentos sugeridos
Es importante hacerse una idea de lo que ocurre cuando se introducen cambios en el proceso de formación. Sugerimos hacer una copia del notebook de las lecciones y ver qué pasa si se introducen cambios. Aquí algunas sugerencias:
- Cambiar el tamaño de las imágenes de entrada definidas en el elemento
Resizetransform en elImageDataLoaders. - Cambiar el modelo utilizado en
vision_learnerderesnet18aresnet34. - Cambiar las ‘métricas’ definidas en
vision_learner. Algunas métricas incluidas en fastai se pueden encontrar en la documentación. - Cambiar el número de ‘epochs’ usados en el método
fine_tune. Si algo se ‘rompe’, ¡no te preocupes! Puedes volver al notebook original para recuperar una versión funcional del código. En la siguiente parte de la lección, los componentes de un proceso de aprendizaje profundo serán cubiertos con más detalle. Investigar qué ocurre cuando se realizan cambios será una parte importante para aprender a entrenar un modelo de visión artificial.
Conclusión Parte 1
En esta lección: - Presentamos una visión general de alto nivel de la distinción entre los enfoques basados en reglas y los basados en aprendizaje automático para abordar un problema. - Mostramos un ejemplo básico de cómo utilizar fastai para crear un clasificador de imágenes con relativamente poco tiempo y pocos datos de entrenamiento. - Presentamos una visión general de los pasos de un proceso de aprendizaje profundo y se identificaron los puntos de este proceso en los que los académicos de humanidades deben prestar especial atención. - Hicimos un experimento rudimentario para comprobar si el aprendizaje por transferencia es útil para nuestro clasificador de visión por artificial.
En la siguiente parte de la lección, nos basaremos en estos puntos y profundizaremos en ellos con mas detalle.
Apéndice : Un experimento no científico que evalúa el aprendizaje por transferencia
El uso del aprendizaje profundo en el contexto del trabajo con datos patrimoniales no se ha investigado ampliamente. Por lo tanto, resulta útil “experimentar” y validar si una técnica es particular es efectiva. Por ejemplo, veamos si el aprendizaje por transferencia resulta útil para entrenar un modelo que clasifique los anuncios de periódicos del siglo XIX en dos categorías: los que contienen imágenes y los que no. Para esto, crearemos un nuevo learner con los mismos parámetros que antes, pero con el indicador de preentrenamiento pretained en False. Este indicador indica a fastai que no utilizará el aprendizaje por transferencia. Almacenaremos esto en una variable learn_random_start.
learn_random_start = cnn_learner(ad_data, resnet18, metrics=accuracy, pretrained=False)
Ahora que hemos creado un nuevo aprendiz, utilizaremos el mismo método de fine_tune que antes y entrenaremos el mismo número de epochs que la última vez.
learn_random_start.fine_tune(5)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.303890 | 0.879514 | 0.460000 | 00:04 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.845569 | 0.776279 | 0.526667 | 00:05 |
| 1 | 0.608474 | 0.792034 | 0.560000 | 00:05 |
| 2 | 0.418646 | 0.319108 | 0.853333 | 00:05 |
| 3 | 0.317584 | 0.233518 | 0.893333 | 00:05 |
| 4 | 0.250490 | 0.202580 | 0.906667 | 00:05 |
La mejor puntuación de precisión que conseguimos cuando iniciamos con los pesos aleatoriamente es de ~90%. En comparación, si volvemos a nuestro modelo original, que está almacenado en una variable learn, y utilizamos el método validate(), obtenemos la métrica (en este caso la precisión) calculada sobre el conjunto de validación:
learn.validate()
(#2) [0.04488467052578926,0.9800000190734863]
Vemos que hay una diferencia bastante grande entre el rendimiento de los dos modelos. Mantuvimos todo igual excepto el indicador preentrenado pretained, que pusimos en falso False. Este indicador determina si el modelo parte de las ponderaciones aprendidas durante el entrenamiento en ImageNet o si parte de ponderaciones “aleatorias”.9 Esto no demuestra de forma concluyente que el aprendizaje por transferencia funcione, pero nos sugiere un valor predeterminado razonable.
Notas finales
-
Romein, C. Annemieke, Max Kemman, Julie M. Birkholz, James Baker, Michel De Gruijter, Albert Meroño‐Peñuela, Thorsten Ries, Ruben Ros, and Stefania Scagliola. ‘State of the Field: Digital History’. History 105, no. 365 (2020): 291–312. https://doi.org/10.1111/1468-229X.12969. ↩
-
Moretti, Franco. Distant Reading. Illustrated Edition. London ; New York: Verso Books, 2013. ↩
-
Wevers, Melvin, and Thomas Smits. ‘The Visual Digital Turn: Using Neural Networks to Study Historical Images’. Digital Scholarship in the Humanities 35, no. 1 (1 April 2020): 194–207. https://doi.org/10.1093/llc/fqy085. ↩
-
Crawford, K., Paglen, T., 2019. Excavating AI: The Politics of Training Sets for Machine Learning. https://www.excavating.ai (accessed 2.17.20). ↩ ↩2
-
Jo, Eun Seo, and Timnit Gebru. ‘Lessons from Archives: Strategies for Collecting Sociocultural Data in Machine Learning’. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, 306–316. FAT* ’20. New York, NY, USA: Association for Computing Machinery, 2020. https://doi.org/10.1145/3351095.3372829. ↩
-
Arizona republican. [volume] (Phoenix, Ariz.) 1890-1930, March 29, 1895, Page 7, Image 7. Image provided by Arizona State Library, Archives and Public Records; Phoenix, AZ. https://chroniclingamerica.loc.gov/lccn/sn84020558/1895-03-29/ed-1/seq-7/. ↩
-
The Indianapolis journal. [volume] (Indianapolis [Ind.]) 1867-1904, February 06, 1890, Page 8, Image 8. Image provided by Indiana State Library. https://chroniclingamerica.loc.gov/lccn/sn82015679/1890-02-06/ed-1/seq-8/. ↩
-
El uso de ‘star imports’ es generalmente desaconsejado en Python. Sin embargo, fastai utiliza
__all__para proporcionar una lista de paquetes que deben ser importados cuando se utiliza star import. Este enfoque es útil para el trabajo exploratorio, pero es posible que desee cambiar sus importaciones para ser más explícito. ↩ -
Esta inicialización no es realmente aleatoria en el marco fastai, y en su lugar utiliza la inicialización Kaiming. ↩