This is the draft website for Programming Historian lessons under review. Do not link to these pages.
For the published site, go to https://programminghistorian.org
Contents
- Introdução
- Configuração e conjunto de dados
- Entendendo as Redes Neurais
- Criando seu próprio modelo
- Conclusão
- Referências
- Notas finais
Introdução
Nos últimos anos, o aprendizado de máquina transformou a visão computacional e impactou uma infinidade de setores e disciplinas. Essas inovações permitiram que os estudiosos conduzissem explorações em larga escala de conjuntos de dados culturais que anteriormente exigiam interpretação manual, mas também traziam seu próprio conjunto de desafios. O viés é desenfreado e muitas técnicas de aprendizado de máquina prejudicam desproporcionalmente mulheres e comunidades negras. Estudiosos de humanidades com experiência em questões de identidade e poder podem servir como baluartes importantes contra a crescente desigualdade digital. No entanto, o alto nível de estatística e conhecimento de ciência da computação necessários para compreender os algoritmos de aprendizado de máquina resultou em análises críticas que muitas vezes falham em olhar para dentro da ‘caixa preta’.
Esta lição fornece uma introdução amigável para iniciantes às redes neurais convolucionais, que, juntamente com os transformadores, são modelos de aprendizado de máquina usados com frequência para classificação de imagens. As redes neurais desenvolvem suas próprias formas idiossincráticas de ver e muitas vezes não conseguem separar os recursos da maneira que poderíamos esperar. Compreender como essas redes operam nos fornece uma maneira de explorar suas limitações quando programadas para identificar imagens que não foram treinadas para reconhecer.
Neste tutorial, vamos treinar uma rede neural convolucional para classificar pinturas. Como historiadores, podemos usar esses modelos para analisar quais tópicos se repetem com mais frequência ao longo do tempo ou automatizar a criação de metadados para um banco de dados. Em contraste com outros recursos que se concentram no desenvolvimento do modelo mais preciso, o objetivo desta lição é mais modesto. Destina-se àqueles que desejam obter uma compreensão da terminologia básica e composição de redes neurais para que possam expandir seus conhecimentos posteriormente, em vez daqueles que procuram criar modelos de nível de produção desde o início.
Público e requisitos
As redes neurais são um tópico fascinante e fiz o possível para simplificar minha explicação sobre elas. Embora isso remova algumas nuances, também nos permite entender mais facilmente o conceito geral e como as redes neurais operam. No entanto, devido à complexidade do problema, este tutorial fornece mais informações básicas do que outros tutoriais focados em codificação avançada.
Estaremos usando a Teachable Machine do Google para treinar nosso modelo - não se preocupe se você não souber o que é “treinar” um modelo agora. O Teachable Machine contém uma interface de arrastar e soltar que permite que mesmo aqueles sem experiência em codificação treinem um modelo. Embora o modelo padrão que criamos no Teachable Machine seja direcionado para nossos dados de treinamento, ele será suficiente para fins pedagógicos e tornará aparentes as limitações do aprendizado de máquina.
A segunda metade do tutorial pegará a rede neural que treinamos no Teachable Machine e a incorporará em um site ao vivo. Para acompanhar esta seção, você precisará ter alguma familiaridade com a codificação de JavaScript. Estaremos usando a biblioteca JavaScript ml5.js construída sobre Tensorflow.js. Esta biblioteca se inspira no Processing (em inglês) e no p5.js, criados pela The Processing Foundation, cujo objetivo é “promover a alfabetização de software nas artes visuais e a alfabetização visual nos campos relacionados à tecnologia - e tornar esses campos acessíveis a diversas comunidades”.[1^] Para aqueles que precisam de uma atualização de JavaScript, o FreeCodeCamp tem excelentes tutoriais interativos gratuitos. Eu também recomendo o livro de Jon DuckettJavaScript e jQuery: desenvolvimento front-end interativo1. Se nenhum desses recursos for do seu agrado, existem centenas de tutoriais e vídeos adicionais que você pode acessar online por meio de uma pesquisa rápida.
Junto com o JavaScript, você deve ter alguma familiaridade com as ferramentas de desenvolvedor do seu navegador e saber como carregar o console do JavaScript. Se precisar de ajuda, há instruções disponíveis para Chrome, Firefox, Edge e Safari. Muitos navegadores limitam o acesso a ficheiros locais por meio de JavaScript por motivos de segurança. Conseqüentemente, você provavelmente precisará iniciar um servidor ativo em sua máquina. Eu recomendo que você use uma extensão para seu editor de código, como Live Server (em inglês) para Visual Studio Code (em inglês) ou execute um servidor por meio do Python.
Esperançosamente, a escolha das ferramentas neste tutorial permitirá que você se concentre nos conceitos mais amplos que envolvem redes neurais sem se preocupar tanto com a codificação. Vale a pena mencionar, no entanto, que Python e R são muito mais populares no nível de produção, e muito do trabalho de ponta em aprendizado de máquina depende dessas duas linguagens em vez do conjunto de ferramentas mostrado neste tutorial. Se você estiver interessado em expandir seu conhecimento sobre redes neurais, consulte os excelentes artigos do Programming Historian (em inglês) em Computer Vision for the Humanities (em inglês) e Interrogating a National Narrative with Recurrent Neural Networks (em inglês).
Configuração e conjunto de dados
Para começar, crie uma nova pasta chamada projects. Esta pasta conterá todos os ficheiros e imagens relevantes. Para treinar a rede neural na Teachable Machine do Google, você precisará de uma coleção de imagens rotuladas, pois a maioria das redes neurais é voltada para o que é conhecido como “aprendizado supervisionado”.
O aprendizado de máquina pode ser dividido em duas formas: aprendizado supervisionado e não supervisionado. O aprendizado supervisionado envolve dados que já estão rotulados. O aprendizado não supervisionado, por outro lado, envolve a identificação de padrões e o agrupamento de dados semelhantes. Você pode ter visto o uso de alguns algoritmos de aprendizado de máquina não supervisionados, como K-Means Clustering (em inglês) e Latent Dirichlet Allocation (em inglês) na pesquisa de humanidades digitais.
Para este tutorial, faremos o download de um conjunto de dados de pinturas da ArtUK, que fornece acesso a obras que atendem aos requisitos do Reino Unido para “propriedade pública”. Aproximadamente, 80% da arte de propriedade pública do Reino Unido não está em exibição. A ArtUK combate isso fornecendo ao público em geral acesso a esses materiais.
O site ArtUK permite que você visualize as obras de arte por tópico e usaremos esses tópicos para treinar nosso classificador de imagens. Você pode baixar um.ziparquivo contendo as imagens aqui. Salve o ficheiro .zip em sua pasta projects e descompacte-o. Dentro, você encontrará uma pasta chamada “dataset” com duas pastas adicionais: training e testing. Depois de baixar todos os ficheiros, vá em frente e inicie um servidor ativo na pasta projects. Na maioria dos casos, você pode visualizar o servidor usando o endereço de host local de “http://127.0.0.1”.
Entendendo as Redes Neurais
Como exatamente os neurônios artificiais funcionam? Em vez de mergulhar diretamente no treinamento deles, é útil primeiro obter uma compreensão mais ampla de sua infraestrutura.
Digamos que estamos interessados em uma tarefa simples, como determinar se uma imagem é a figura de um quadrado ou triângulo. Se você fez algum tipo de codificação, saberá que a maioria dos programas resolve isso processando uma sequência de etapas. Loops e instruções (como for, while e if) permitem que nosso programa tenha ramificações que simulem o pensamento lógico. No caso de determinar se uma imagem contém uma forma, podemos codificar nosso programa para contar o número de lados e exibir “quadrado” se encontrar quatro, ou “triângulo” se encontrar três. A distinção entre objetos geométricos pode parecer uma tarefa relativamente simples, mas requer que um programador não apenas defina as características de uma forma, mas também implemente a lógica que discerne essas características. Isso se torna cada vez mais difícil à medida que nos deparamos com cenários em que as distinções entre as imagens são mais complexas. Por exemplo, observe as seguintes imagens:

Figura 1. Uma foto de um gato

Figura 2. Uma foto de um cachorro
Como humanos, podemos facilmente determinar qual deles é um cachorro e qual é um gato. No entanto, delinear as diferenças exatas é um desafio. Acontece que os humanos geralmente são muito melhores em lidar com as nuances da visão do que os computadores. E se conseguíssemos que um computador processasse imagens da mesma forma que nossos cérebros? Essa pergunta e percepção formam a base dos neurônios artificiais.
Como o nome indica, os neurônios artificiais se inspiram nos neurônios do cérebro. O seguinte é um diagrama simplificado2 de como funcionam um neurônio biológico e artificial:
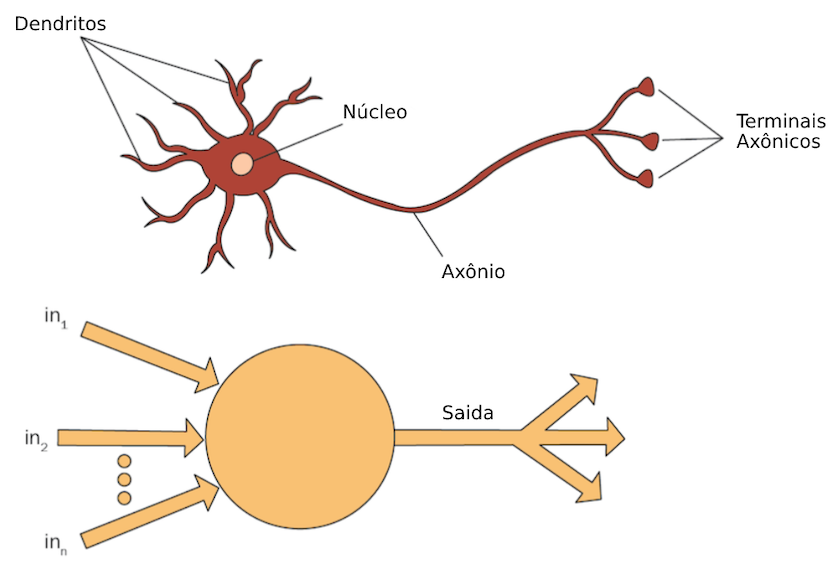
Figura 3. Diagrama de um neurônio biológico e um artificial.
Os neurônios biológicos têm dendritos, que são apêndices semelhantes a ramificações que recebem entradas elétricas de outros neurônios e as enviam para o corpo celular. Se estimulado o suficiente, o corpo celular enviará sinais pelo axônio para os terminais axônicos, que os enviarão a outros neurônios.
De que maneiras um neurônio artificial imita um biológico? Em 1943, Warren MuCulloch e Walter Pitts lançaram as bases para a criação de neurônios artificiais em seu artigo “A Logical Calculus of Ideas Immanent in Nervous Activity”.3 Em contraste com os neurônios biológicos que recebem sua eletricidade de outros neurônios, eles postularam que um neurônio artificial recebe um número arbitrário de valores numéricos. Em seguida, ele envia sua soma para outro neurônio. Isso, no entanto, apresenta um problema: se o neurônio emite automaticamente essas somas, todos os neurônios disparam simultaneamente, e não quando suficientemente estimulados. Para combater isso, os neurônios artificiais determinam se a soma das entradas que recebem excede um limite específico antes de emitir os resultados. Pense nisso como um copo que pode conter uma certa quantidade de líquido antes de começar a transbordar. Da mesma forma, um neurônio pode absorver eletricidade, mas apenas “disparar” quando atinge uma massa crítica. A maneira exata que esse limiar envia para outros neurônios é determinada por meio de funções de ativação, que veremos com mais profundidade na próxima seção.
Deve-se notar que os neurônios biológicos são entidades muito mais complexas do que os neurônios artificiais. Andrew Glassner resume o abismo entre os dois em Deep Learning a Visual Approach observando:
Os “neurônios” que usamos no aprendizado de máquina são inspirados em neurônios reais da mesma forma que um desenho de boneco é inspirado em um corpo humano. Há uma semelhança, mas apenas no sentido mais geral. Quase todos os detalhes se perdem ao longo do caminho e ficamos com algo que é mais um lembrete do original do que uma cópia simplificada.4
O que é importante entender não é a relação exata entre neurônios artificiais e biológicos, mas a linguagem espacial e as metáforas usadas na literatura que podem tornar muito mais fácil descobrir o que exatamente está acontecendo em uma rede neural básica.
Uma rede neural básica
Uma rede neural é simplesmente uma teia de neurônios artificiais interconectados. Aqueles que examinaremos aqui são ‘feed-forward’, o que significa que os dados passam por eles apenas em uma direção. Estes são particularmente populares para concluir tarefas de classificação. Em contraste, as redes neurais recorrentes têm loops nos quais os dados de uma parte da rede neural são passados de volta para outra. Embora geralmente sejam desenhados da esquerda para a direita, é mais fácil pensar em uma rede neural como uma série de etapas em que cada neurônio faz algum tipo de cálculo. Eles quase sempre consistem em uma camada de entrada, uma série de camadas ocultas e uma camada de saída.
Como o nome indica, a camada de entrada contém as entradas para os dados a serem analisados. Independentemente da forma original dos dados, eles devem primeiro ser convertidos em uma representação numérica para percorrer a rede. Vamos considerar como os neurônios convertem imagens digitais em números. As imagens digitais são compostas por uma série de pixels. Podemos representar essas imagens numericamente como matrizes multidimensionais com dimensões representando altura, largura e o número de canais. Os canais correspondem à profundidade de cor de cada pixel. Por exemplo, a profundidade de cor de uma imagem em tons de cinza terá um único valor representando a intensidade da luz, enquanto uma imagem colorida terá uma série de valores para vermelho, verde e azul.
Da camada de entrada, a rede neural geralmente passa os dados para uma série de “camadas ocultas”. As camadas ocultas são aquelas após a camada de entrada e antes da camada de saída. Dependendo do tipo de rede, o número de camadas ocultas e suas funções variam. Qualquer rede com mais de uma camada oculta é chamada de “rede neural profunda”.
Na maioria das camadas ocultas, a rede neural pega os valores das camadas anteriores, faz um cálculo matemático sobre eles (geralmente soma) e multiplica a soma por um ‘peso’ específico antes de enviá-lo aos neurônios na próxima camada. Cada neurônio então pega sua entrada e a transforma em uma única saída – normalmente somando os valores.
Como os neurônios nas camadas ocultas ajudam a resolver problemas matemáticos e tarefas de classificação? Vamos a um exemplo simples. Vamos supor que estamos interessados em resolver a seguinte equação: x+y=7.5. Neste cenário, sabemos que a saída deve ser 7,5, mas não conhecemos as entradas. Podemos começar simplesmente adivinhando números como 3 e 2. Colocá-los em nossa equação nos dá uma resposta de 5. No entanto, sabemos que precisamos obter uma resposta de 7,5, então uma das coisas que podemos fazer é multiplicar o entradas por um número. Podemos começar multiplicando nossos palpites originais por 2. A quantidade que multiplicamos cada número é conhecida como peso: (3x2)+(2x2)=10. Agora superamos nossa produção, então precisamos ajustar os pesos para baixo. Uma rede neural usa o valor de “erro” para ajustar os pesos de nossa rede de acordo, em um processo chamado “retropropagação”. Vamos tentar 1.5: (3x1.5)+(2x1.5)=7.5. Agora temos o resultado correto, apesar de não conhecermos as entradas originais e simplesmente escolhermos dois valores aleatórios. É exatamente assim que uma rede neural funciona!
Uma coisa a notar é que a saída de um neurônio para a próxima camada raramente é o valor originalmente calculado. Em vez disso, ele é enviado para uma função de ativação para evitar o colapso da rede. Lembre-se de que uma função de ativação em um neurônio biológico tem um limite que impede que todos os neurônios disparem ao mesmo tempo. Você pode pensar no colapso da rede como a remoção de qualquer redundância nos neurônios. Por exemplo, se um neurônio adiciona dois valores de entrada diferentes e os envia para outro neurônio que, por sua vez, adiciona a saída do primeiro neurônio, podemos reduzir o número de neurônios programando o primeiro para realizar todo o cálculo. Embora isso possa parecer mais eficiente, diminui a flexibilidade de nossa rede.
A função de ativação em um neurônio artificial interrompe o colapso da rede introduzindo a não linearidade. Existem vários tipos de funções de ativação. As funções não lineares mais simples são as “funções degrau”. Nessas funções, um determinado limite (às vezes um grupo de limites) é escolhido e os valores à esquerda do limite geram um único valor, enquanto os valores à direita do limite fornecem vários valores. As funções de ativação mais populares são variações da unidade linear retificada (ReLU). Em sua forma mais simples, uma função de ativação ReLU produz 0 valores menores que zero e o próprio valor de entrada se for maior que zero.
As funções de ativação são particularmente importantes na camada final, pois restringem a saída dentro de um determinado intervalo. Se você estiver familiarizado com a regressão logística, talvez esteja familiarizado com a função sigmóide que é usada na classificação binária. Podemos usar essa mesma função como uma função de ativação para uma rede neural para restringir nossos valores definidos como 0 ou 1. No entanto, como normalmente temos mais de duas categorias, as funções ArgMax e SoftMax são mais comuns. O primeiro gera a categoria com a probabilidade máxima para 1 e o restante para zero. Este último fornece valores para cada categoria entre 0 e 1 com o valor mais alto indicando a classificação mais provável e o valor mais baixo indicando a classificação menos provável.
Redes Neurais Convolucionais
Espero que agora você tenha um bom entendimento de como funciona uma rede neural básica. As redes neurais convolucionais se baseiam nessa mesma base. Essas redes são particularmente boas na detecção de recursos de imagem e obtêm seu nome de suas “camadas convolucionais”.
Pense no que compõe uma imagem. Se você já fez uma aula de desenho, pode ter aprendido a dividir um esboço em formas simples, como círculos e quadrados. Mais tarde, você pegou essas formas e desenhou imagens mais complexas sobre elas. Uma rede neural convolucional faz essencialmente a mesma coisa. À medida que empilhamos camadas de convolução umas sobre as outras, cada uma aprende a identificar diferentes partes de uma forma cada vez mais complexa. A primeira camada detecta recursos básicos, como cantos e arestas. As camadas intermediárias detectam formas e as segmentam em partes de objetos. As últimas camadas serão capazes de reconhecer os próprios objetos, antes de enviá-los para a camada de saída para classificação. Para obter mais informações sobre como funcionam as camadas de uma rede de convolução, recomendo a excelente postagem no blog de Erik Reppel Visualizando partes de redes neurais convolucionais usando Keras e Cats.5
O que exatamente é uma convolução? Basicamente, uma convolução é uma função matemática que resulta na convergência de dois conjuntos de informações. Se você usou filtros, como desfoques, em aplicativos comuns de edição de imagens, você usou convoluções. As convoluções para imagens funcionam usando um filtro (também conhecido como kernel) que consiste em uma grade de números; geralmente 3x3 ou 5x5, e movendo-o sobre cada pixel da imagem. À medida que o filtro se move, os valores em cada pixel sobreposto são multiplicados pelos valores no filtro. Por fim, os valores de todos os números na grade são somados para criar uma única saída.
Como a rede neural pega os valores de cada grade e os adiciona, os valores dados à próxima camada são menores que a imagem original. Essa nova matriz de números é chamada de “mapa de recursos” e torna o treinamento da rede neural menos intensivo computacionalmente. Uma função de ativação, como ReLU, também é comumente usada para transformar todos os valores negativos em zero.
Finalmente, uma “camada de pooling” é utilizada. Uma camada de agrupamento funciona de maneira semelhante a uma camada convolucional, pois usa uma grade; geralmente 2x2 e o passa sobre cada valor no mapa de recursos. Em contraste com a camada de convolução, no entanto, a camada de agrupamento simplesmente pega o valor máximo ou médio (dependendo de qual rede neural convolucional você está usando) dos números na grade. Isso cria um mapa de recursos menor. Juntos, as convoluções e o agrupamento permitem que as redes neurais realizem a classificação de imagens mesmo que o arranjo espacial dos pixels seja diferente e sem a necessidade de fazer tantos cálculos.
Transfer Learning e Redes Neurais Convolucionais
Agora, vamos começar a usar a Teachable Machine do Google para treinar nosso modelo. Teachable Machine fornece uma interface simples que podemos usar sem ter que nos preocupar inicialmente com código. Ao carregá-lo, você descobrirá que tem a opção de treinar três tipos diferentes de modelos. Para este tutorial, criaremos o que a Teachable Machine chama de “modelo de imagem padrão”.
Treinar um classificador de imagens do zero pode ser difícil. Precisaríamos fornecer várias imagens junto com seus rótulos correspondentes. Em vez disso, a Teachable Machine depende do aprendizado por transferência.
O aprendizado de transferência se expande em um modelo que já foi treinado em um grupo separado de imagens. A Teachable Machine conta com a MobileNet como base para seu aprendizado por transferência. MobileNet é uma rede neural leve projetada para rodar em pequenos dispositivos com baixa latência. Seus tempos de treinamento são relativamente rápidos e podemos começar com menos imagens. Claro, o MobileNet não foi treinado nas imagens que nos interessam, então como exatamente podemos usá-lo? É aqui que o aprendizado de transferência entra em ação.
Você pode pensar no aprendizado por transferência como um processo de modificação da camada final de um modelo preexistente para discernir as “características” de nossas imagens. A princípio, esses recursos são mapeados para as categorias nas quais o MobileNet foi treinado, mas por meio do aprendizado de transferência, podemos substituir esse mapeamento para refletir nossas próprias categorias. Assim, podemos contar com as camadas anteriores para fazer a maior parte do trabalho pesado &mdashdetectar recursos e formas básicas&mdash enquanto ainda temos o benefício de usar as camadas finais para reconhecer objetos específicos e executar a classificação.
Criando seu próprio modelo
Na página inicial da Teachable Machine, vá em frente e clique no botão “Get Started”(em inglês) (tradução: Iniciar). Em seguida, clique em “Image Project”(em inglês) (tradução: Projeto de imagem) e selecione “Standard image model.”(em inglês) (tradução: Modelo de imagem padrão).
Agora, podemos começar a carregar amostras de imagens para cada classe. Você descobrirá que pode “Upload” (em inglês) (tradução: Carregar) imagens ou usar sua webcam para criar novas. Faremos o upload de todas as imagens de cada uma de nossas categorias para a pasta de treinamento.
Em “Class 1”(em inglês) (tradução: Aula 1), clique em “Choose images from your files, or drag & drop here.” (em inglês) (tradução: Escolher imagens de seus ficheiros ou arraste e solte aqui). Selecione a pasta “aircraft” (em inglês) (tradução: eoronaves) de dentro da pasta “training” (em inglês) do conjunto de dados e arraste-a para a janela Teachable Machine. Clique no ícone de lápis ao lado de “Class 1” (em inglês) (tradução: Classe 1) e altere o nome para “aeronaves”.
Repita esse processo para as outras pastas no conjunto de dados. Após a segunda vez, você precisará clicar em “+ Add a class” (em inglês) (tradução: + Adicionar uma classe) para cada nova pasta.
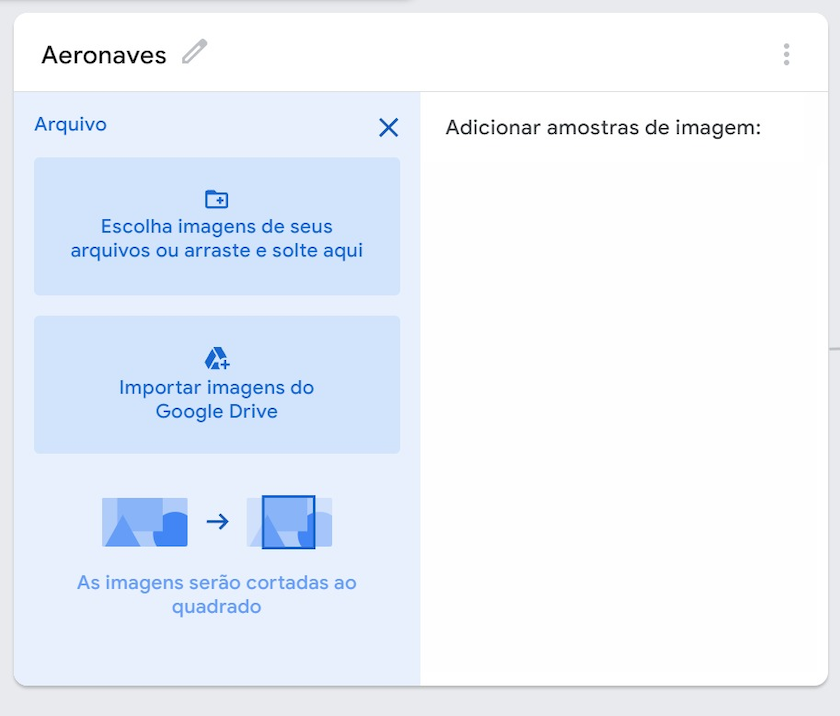
Figura 4. Adicionando classes ao Google Teachable Machine.
Depois de terminar de carregar as imagens, você pode ajustar vários parâmetros de como o modelo deve ser treinado clicando em “Advanced” (em inglês) (tradução: Avançado) em “Training” (em inglês) (tradução: Treinamento). Aqui você verá opções para épocas, tamanho do lote e taxa de aprendizado.
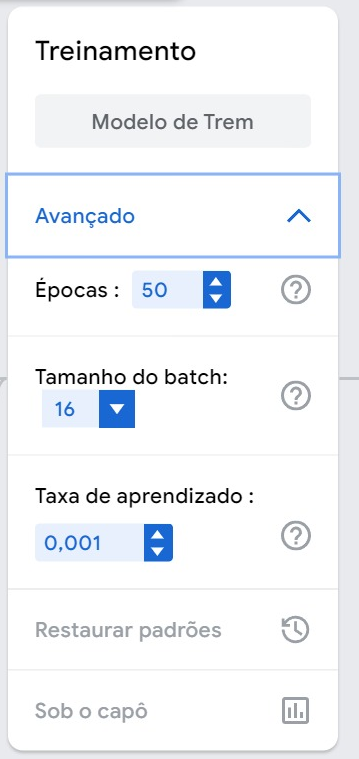
Figura 5. Configurações avançadas no Google Teachable Machine.
Uma época refere-se ao número de vezes que cada imagem é alimentada através da rede neural durante o treinamento. Como cada imagem é alimentada várias vezes, não precisamos de um grande número de imagens de amostra. Você pode estar se perguntando por que simplesmente não definimos a época ridiculamente alta para que nosso modelo trabalhe com o conjunto de dados um número maior de vezes. O principal motivo é o “overfitting” (em inglês).
Overfitting (em inglês) é quando nossa rede neural se torna realmente proficiente em trabalhar com nosso conjunto de treinamento, mas falha em novos dados. Isso é resultado da Compensação viés-variância. Se um modelo tiver um viés alto, ele terá um bom desempenho em nosso conjunto de dados de treinamento, mas não tão bem em um novo. Por outro lado, se tiver alta variância, pode não funcionar tão bem em nossos dados de treinamento, mas pode ter mais flexibilidade quando se trata de novos dados. Como determinar a relação exata entre variância e viés é um tópico complexo. Um método comum é salvar um pouco dos dados originais dividindo-os em um conjunto de “teste”. Em vez de usar esses dados para construir o modelo original, o conjunto de teste é usado para fornecer resumos estatísticos de como o modelo funcionará com novos dados. A Teachable Machine faz isso ‘under the hood’ (em inglês) (tradução: sob o capô), mas quando você constrói modelos mais elaborados, você mesmo precisará determinar quanto dos dados originais deve ser preservado.
O tamanho do lote refere-se ao número de imagens usadas para treinamento por iteração. Se você tiver 80 imagens e um tamanho de lote de 16, isso significa que serão necessárias 5 iterações para formar uma época. Uma das principais vantagens de usar um tamanho de lote menor é que ele é muito mais eficiente na memória. Como estamos atualizando o modelo após cada lote, a rede tende a ser treinada mais rapidamente. No entanto, os tamanhos dos lotes influenciam na generalização e convergência do nosso modelo, portanto, precisamos ter cuidado com essa configuração.
A taxa de aprendizado refere-se a quanto devemos mudar nosso modelo com base no erro estimado. Isso afeta o desempenho da sua rede neural.
Vamos manter as configurações padrão por enquanto. Clique no botão “Train” (em inglês) (tradução: Treinar) para começar a treinar seu modelo.
Observe que imediatamente após o término do treinamento, a Teachable Machine começará a testar o feed de vídeo da sua webcam. Você precisa selecionar “Ficheiro” no menu suspenso ao lado de Entrada em vez de Webcam para interromper isso.
Uma barra exibirá o progresso. Certifique-se de não fechar o navegador ou alternar as guias durante esse período. O pop-up exibido abaixo irá lembrá-lo disso.

Figura 6. Pop-up mostrando para não alternar guias
Após a conclusão do treinamento, você desejará testar seu modelo. Existem várias medidas que podemos usar para determinar o quão bem um modelo funciona. Se você clicar em “Under the hood” (em inglês) (tradução: sob capô) nas configurações avançadas, a perda e a precisão por época serão exibidas. Quanto mais próxima a perda estiver de 0 e a precisão de 1, melhor nosso modelo entenderá nossas imagens.
Um dos benefícios da Teachable Machine é que podemos começar imediatamente a testar nosso modelo. A entrada padrão para novas imagens é usar sua webcam para que possamos alterá-la para ficheiro. Vá em frente e carregue uma das imagens na pasta testing e veja os resultados. Normalmente, gostaríamos de testar nosso modelo com muitas imagens ao mesmo tempo, mas o Teachable Machine nos permite testar apenas uma imagem por vez. Na pasta testing, há dez imagens para testar a classificação. Vá em frente e compare como você mesmo os classificaria com a saída Teachable Machine fornecida.
Exportar o modelo
Vamos exportar e baixar nosso modelo para ver como podemos reutilizá-lo em novas circunstâncias. Clique no botão “Export Model” e você verá três opções: Tensorflow.js, Tensorflow e Tensorflow Light. Tensorflow é uma biblioteca desenvolvida pelo Google focada em aprendizado de máquina e inteligência artificial. Escolheremos Tensorflow.js, que é simplesmente uma implementação JavaScript da biblioteca. Ml5.js e p5.js , que usaremos posteriormente para incorporar nosso modelo em nosso site, dependem do Tensorflow.js em um nível inferior.
Depois de selecionar Tensorflow.js, você receberá um ficheiro .zip contendo três ficheiros:
model.jsoncontendo dados sobre as diferentes camadas para a própria rede neuralweights.bincontendo informações sobre os pesos para cada um dos neurôniosmetadata.jsoncontendo informações sobre qual versão do Tensorflow está sendo usada para a rede junto com os rótulos de classe
Descompacte esta pasta e coloque os ficheiros dentro da sua pasta projects:
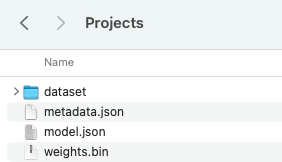
Figura 7. Pasta de projetos com ficheiros Tensorflow.js
Importar o modelo com ml5.js
O Teachable Machine é um ótimo recurso para se familiarizar com o funcionamento mais amplo das redes neurais e do aprendizado de máquina. No entanto, é limitado no que pode fazer. Por exemplo, talvez queiramos criar algum tipo de gráfico que exiba informações sobre a classificação. Ou talvez desejemos permitir que outros usem nosso modelo para classificação. Para isso, precisaremos importar nosso modelo para um sistema que permita mais flexibilidade. Embora existam muitas ferramentas possíveis para escolher, para este tutorial usaremos ml5.js e p5.js.
Ml5.js é uma biblioteca JavaScript construída sobre Tensorflow.js. Conforme mencionado anteriormente, as bibliotecas de aprendizado de máquina geralmente exigem que os usuários tenham um conhecimento significativo de programação e/ou estatística. Para a maioria das bibliotecas de rede neural, você deve especificar propriedades para cada camada da rede neural, como suas entradas, saídas e funções de ativação. O Ml5.js cuida disso para você, tornando mais fácil para os iniciantes começarem.
Para começar, vamos criar alguns ficheiros em nossa pasta projects. Dentro da pasta, criaremos uma index.html página que chamará o restante de nossas bibliotecas JavaScript. Isso nos permite examinar a saída do modelo sem ter que olhar diretamente para o console do desenvolvedor do navegador — embora façamos isso também. Também precisamos criar um ficheiro chamado sketch.js no mesmo diretório que index.html.
Na discussão abaixo, adicionaremos o conteúdo deste ficheiro passo a passo. Se você se perder a qualquer momento, você pode baixar o código completo aqui .
Por fim, pegaremos uma imagem da pasta testing e a colocaremos na pasta raiz do nosso projeto para garantir que nosso código esteja funcionando. Você pode usar qualquer imagem que quiser, mas vou usar a primeira para este exemplo. Sua pasta projects agora deve estar assim:
Figura 8. Pasta Projetos com ‘script.js’, ‘index.html’ e imagem de teste
Basearemos o código do nosso ficheiro index.html no modelo clichê oficial ml5.js. Este modelo está vinculado às bibliotecas ml5.js e p5.js mais recentes. Embora ml5.js não exija p5.js, a maioria dos exemplos usa ambos porque a combinação nos permite codificar rapidamente uma interface para interagir com o modelo. Teremos a maior parte do código para nossa rede neural em um ficheiro JavaScript separado chamado sketch.js, e nosso modelo clichê será vinculado a esse script.
<!DOCTYPE html>
<html lang="en">
<head>
<title>Getting Started with ml5.js</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- p5 -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/1.0.0/p5.min.js"></script>
<!-- ml5 -->
<script src="https://unpkg.com/ml5@latest/dist/ml5.min.js"></script>
<script src="sketch.js"></script>
</head>
<body>
</body>
</html>
Fora deste modelo, não temos nenhum código adicional em nosso ficheiro index.html. Em vez disso, temos um link para sketch.js. Observe que muitas convenções p5.js e ml5.js se baseiam em terminologia artística, e é aí que faremos a maior parte de nossa codificação. Mude seu editor para sketch.js.
Garantiremos que tudo esteja funcionando corretamente imprimindo a versão atual do ml5.js no console. Em sketch.js, copie ou digite o seguinte:
//enviar a versão atual do ml5 para o console
console.log('ml5 version:', ml5.version);
Você já deve ter iniciado um servidor ativo durante o estágio de configuração. Caso contrário, você deve iniciá-lo agora na pasta projects. Carregue index.html em seu navegador da Web &mdash lembre-se de que index.html é apenas um modelo de placa de caldeira com link para sketch.js &mdash e verifique o console do desenvolvedor para obter a saída. Enquanto a saída para a versão atual for exibida, você não deverá encontrar nenhum problema.
Observe que a saída para ml5.js consiste em um grande número de emojis e favicons que geralmente falham ao carregar.
Como estamos usando o p5.js, vale a pena dedicar alguns minutos para examinar algumas de suas peculiaridades. P5.js é uma interpretação de Processamento em JavaScript. Tanto o p5.js quanto o Processing atendem a artistas digitais, especialmente aqueles interessados em criar arte generativa . Você descobrirá que utilizar a terminologia artística é uma convenção comum entre os programadores de p5.js e ml5.js. É por isso que nomeamos nosso ficheiro JavaScript sketch.js.
As duas funções principais em p5.js que se baseiam nessa tradição são as funções setup() e draw(). A função setup() é executada automaticamente quando o programa é executado. Vamos usá-lo para criar uma tela quadrada em branco com 500x500 pixels usando a função createCanvas(). Também moveremos nosso código que gera a versão atual de ml5.js para o console.
function setup() {
// Saída da versão atual do ml5 para o console
console.log('ml5 version:', ml5.version);
// Crie uma tela quadrada em branco com 500px por 500px
createCanvas(500,500);
}
Ao executar o comando acima, você terá criado a tela, mas, por estar definida como branca, talvez não consiga diferenciá-la do resto da página. Para facilitar a visualização dos limites de nossa tela, usaremos a função background() e passaremos o valor hexadecimal para preto.
function setup() {
// Saída da versão atual do ml5 para o console
console.log('ml5 version:', ml5.version);
// Crie uma tela quadrada em branco com 500px por 500px
createCanvas(500,500);
// Defina o plano de fundo da tela para preto com base no código hexadecimal
background('#000000');
}
Se você carregar index.html novamente, verá que agora temos uma tela preta de 500x500 pixels.
Em seguida, carregaremos o modelo real. No passado, isso era comumente feito usando uma função de retorno de chamada para lidar com a natureza assíncrona do JavaScript. Se você não estiver familiarizado com JavaScript, isso pode ser uma fonte de confusão. Basicamente, o JavaScript lê o código de cima para baixo, mas não para para concluir nenhuma parte do código, a menos que seja necessário. Isso pode levar a problemas ao executar tarefas como carregar um modelo, porque o JavaScript pode começar a chamar o modelo antes de terminar de carregar. As funções de retorno de chamada fornecem uma maneira de contornar isso, pois não são chamadas em JavaScript até que outro código já tenha sido concluído.
Para lidar com erros comuns no carregamento de imagens, modelos e complexidade de callbacks, o p5.js introduziu uma nova função preload(). Este é um recurso poderoso do p5.js que nos permite ter certeza de que as imagens e os modelos foram carregados antes que a função setup() seja chamada.
Vamos colocar a chamada para carregar nosso modelo na função preload() e atribuí-la a uma variável global. Embora a função preload() nos permita evitar callbacks em certas situações, provavelmente ainda queremos algum feedback para quando o modelo for carregado com sucesso. Para isso, criaremos uma nova função chamada teachableMachineModelLoaded() que enviará uma mensagem para o console. Você só precisa chamar o ficheiro model.json para que isso funcione. O Ml5.js procurará automaticamente na mesma pasta o ficheiro que contém os pesos e metadados.
// Variável para manter o modelo de aprendizado de máquina
let classifier;
// Carregue model.json e configure-o para nossa variável. Faça callback para a função teachableMachineModelLoaded para saída quando o carregamento estiver completo.
function preload() {
classifier = ml5.imageClassifier('model.json', teachableMachineModelLoaded);
}
// Callback para garantir quando o modelo foi completamente carregado
function teachableMachineModelLoaded() {
console.log('Teachable Machine Model carregado com sucesso!');
}
Agora que carregamos o modelo, precisamos adicionar nossa imagem de teste. A primeira coisa que faremos é carregar nossa imagem usando a função loadImage() p5.js. A função loadImage() usa um caminho para a imagem como um parâmetro e retorna um objeto p5.Image, que fornece algumas funções adicionais para manipular imagens em comparação com o JavaScript simples. Podemos colocar esta chamada na função preload(). Você pode escolher qualquer uma das imagens de teste ou sua própria imagem para experimentar. Basta colocá-los na mesma pasta do código. Para os fins deste tutorial, vamos apenas carregar testing0.jpg, que é uma imagem de uma aeronave.
let classifier;
let testImage;
function preload() {
classifier = ml5.imageClassifier('model.json', teachableMachineModelLoaded);
// Carregue a imagem da mesma pasta. Observe que você pode alterar isso para qualquer imagem que desejar.
testImage=loadImage("testing0.jpg");
console.log("Successfully Loaded Test Image");
}
Agora podemos usar a função image() p5.js para desenhar a imagem na tela. São necessários três argumentos. O primeiro é o nome da variável que contém a imagem. Neste caso, é a variável testImage. Os próximos dois são as coordenadas x e y para onde colocar a imagem. Vamos colocá-lo no centro da nossa tela. Uma maneira fácil de fazer isso é por meio das variáveis “height” e “width” que contêm as dimensões da tela. O P5.js os disponibiliza automaticamente e podemos dividir por dois para centralizar a imagem.
Faremos esta chamada dentro da função draw(), que é chamada imediatamente depois setup() e é onde colocaremos a maior parte do nosso código.
function draw() {
// Coloque a imagem no centro dividindo a largura e a altura da tela por dois.
image(testImage, width/2, height/2);
}
Se você observar a imagem, verá que ela não está perfeitamente centralizada na tela. Esta é uma das peculiaridades de trabalhar com p5.js. Ele coloca a imagem na tela usando o canto superior esquerdo como ponto de ancoragem. Podemos chamar a função imageMode() e passar o argumento “CENTER” para alterar como o p5.js determina onde colocar as imagens. Essa configuração permanecerá em vigor até que você decida alterá-la.
Se você executar o seguinte, verá que agora temos nossa imagem no centro da tela.
function draw() {
// Centralize o ponto de ancoragem da imagem para ser o centro da imagem
imageMode(CENTER);
image(testImage, width/2, height/2);
}
A função draw() é exclusiva para p5.js e loops com base na taxa de quadros. Novamente, isso se deve ao p5.js ser originalmente voltado para artistas. Repetir constantemente o material dentro do draw() facilita a criação de animações. Quando você publica a imagem na tela, o p5.js está, na verdade, executando continuamente o código e colocando uma nova imagem em cima da antiga. Para parar isso, podemos chamar a função noLoop().
function draw() {
// Parar o loop de código no sorteio
noLoop();
// Coloque o ponto de ancoragem da imagem no centro da imagem
imageMode(CENTER);
// Imagem de saída para o centro da tela
image(testImage, width/2, height/2);
}
Agora estamos prontos para avaliar nosso modelo. Chamaremos a função classify() do nosso objeto classificador. Requer um único argumento contendo o objeto que estamos interessados em classificar junto com um callback. Usaremos getResults() como nossa função de retorno de chamada. ml5.js enviará automaticamente dois argumentos para a função contendo informações sobre erros e/ou resultados. Vamos enviar esses resultados para o console:
function draw() {
noLoop();
imageMode(CENTER);
image(testImage, width/2, height/2);
// Chame a função de classificação para obter resultados. Use a função de retorno de chamada chamada getResults para processar os resultados
classifier.classify(testImage, getResults);
}
function getResults(error, results) {
// Se houver um erro na classificação, envie para o console. Caso contrário, envie os resultados para o console.
if (error) {
console.error(error);
} else {
console.log(results);
}
}
Se tudo correu bem, você deve ver os resultados da classificação no console como um objeto JavaScript. Vamos dar uma olhada mais de perto na saída. Observe que os números exatos obtidos podem variar. Esta é a saída da primeira imagem:
(5) [{...}, {...}, {...}, {...}]
0: {label: 'Aircraft', confidence: 0.6536924242973328}
1: {label: 'Boat', confidence: 0.3462243676185608}
2: {label: 'House', confidence: 0.000002019638486672193}
4: {label: 'Horse Racing', confidence: 1.42969639682633e-7}
length: 5
[[Prototype]]: Array(0)
Se você olhar dentro do objeto JavaScript (na maioria dos navegadores, isso é feito clicando no símbolo de seta ao lado do nome do objeto), você verá a saída para a imagem testing0.jpg listar todas as classes possíveis por probabilidade e confiança. Vemos que results[0] contém o resultado mais provável com o rótulo listado em results[0].label. Há também uma pontuação de confiança em results[0]. A confiança fornece um valor percentual que indica quão certo nosso modelo é do primeiro rótulo.
Podemos enviar esses valores para nossa tela usando a função text() em nossa chamada getResults(), que recebe como argumentos nosso texto e as coordenadas x, y para onde queremos colocá-lo. Colocarei o texto logo abaixo da própria imagem. Também precisaremos chamar algumas funções que detalham como queremos que nosso texto seja exibido. Especificamente, usaremos fill() um valor hexadecimal para o texto colorido, textSize() para o tamanho e textAlign() para usar o centro de nossa fonte como ponto de ancoragem. Por fim, arredondaremos a confiança para duas casas decimais usando a função toFixed().
function draw() {
noLoop();
imageMode(CENTER);
image(testImage, width/2, height/2);
classifier.classify(testImage, getResults);
}
function getResults(error, results) {
if (error) {
console.error(error);
} else {
// Set the color of the text to white
fill('#FFFFFF');
// Set the size of the text to 30
textSize(30);
// Set the anchor point of the text to the center
textAlign(CENTER)
// Place text on canvas below image with most likely classification and confidence score
text("Confidence " + (results[0].confidence*100).toFixed(2) + "%", width/2, height/2+165)
text("Most Likely " + results[0].label, width/2 , height/2+200);
// Output most likely classification and confidence score to console
console.log("Most likely " + results[0].label);
console.log("Confidence " + (results[0].confidence*100).toFixed(2) + "%",);
console.log(results);
}
}
Execute o código acima para ver o resultado do que a imagem representa junto com uma pontuação de confiança. Se o código for executado com êxito, você deverá ver o seguinte resultado (embora observe que sua pontuação de confiança provavelmente será diferente):

Figura 9. Exemplo de resultado.
Conclusão
Esta lição forneceu uma introdução ao funcionamento das redes neurais e explicou como você pode usá-las para realizar a classificação de imagens. Mantive propositalmente o código e os exemplos simples, mas encorajo você a expandir o código que usou aqui. Por exemplo, você pode adicionar loops que instruem um modelo a percorrer uma pasta de imagens e gerar os resultados em um ficheiro CSV que contém tópicos ou gráficos dos temas de corpora maiores. Você também pode investigar as limitações da rede neural para identificar áreas onde ela não funciona. Por exemplo, o que acontece quando você carrega uma pintura abstrata ou algo que não é uma pintura? Explorar esses pontos fracos pode levar à inspiração não apenas para trabalhos acadêmicos, mas também criativos.
Uma coisa a ter em mente é que nosso modelo é tendencioso em relação aos nossos dados de treinamento. Em outras palavras, embora possa ser útil para categorizar as imagens ArtUK, pode não funcionar tão bem quando se trata de novos dados.
Referências
Embora Teachable Machine e ml5.js forneçam um bom ponto de partida, essa simplicidade vem com uma perda de flexibilidade. Como mencionado anteriormente, você provavelmente desejará mudar para Python ou R para fazer aprendizado de máquina em nível de produção. Eu recomendo os tutoriais do Programming Historian’s (em inglês) em Visão Computacional para Humanidades e Interrogando uma Narrativa Nacional com Redes Neurais Recorrentes. Ambos incluem links para recursos adicionais que o ajudarão a expandir seu conhecimento.
Se você estiver interessado em desenvolver um conhecimento mais amplo sobre ml5.js ou aprender mais sobre os conceitos que sustentam as redes neurais, também recomendo o seguinte:
-
3Blue1Brown tem alguns vídeos maravilhosos que se aprofundam na matemática das redes neurais. 3Blue1Brown, redes neurais, https://www.3blue1brown.com/topics/neural-networks (em inglês).
-
Dan Shiffman fornece uma boa visão geral do uso de ml5.js e p5.js para aprendizado de máquina em seu canal do YouTube. The Coding Train, Beginner’s Guide to Machine Learning in JavaScript with ml5.js, YouTube video, 1:30, 4 de março de 2022, https://youtu.be/26uABexmOX4 (em inglês).
-
Ele também tem uma série de vídeos sobre a construção de uma rede neural a partir do zero que abrange os fundamentos matemáticos do aprendizado de máquina. The Coding Train, 10.1: Introduction to Neural Networks - The Nature of Code, vídeo do YouTube, 7:31, 26 de junho de 2017, https://youtu.be/XJ7HLz9VYz0 (em inglês).
-
A referência oficial do ml5.js fornece uma visão geral abrangente de como realizar a classificação de imagens juntamente com outras tarefas de aprendizado de máquina. Ml5.js, Referência, https://learn.ml5js.org/#/reference/index (em inglês).
-
O livro de Tariq Rashid, Make Your Own Neural Network, fornece uma introdução excelente e clara para os interessados em desenvolver conhecimento sobre aprendizado de máquina. Tariq Rashid. Faça sua própria rede neural. Plataforma de publicação independente CreateSpace, 2016.
-
O documentário interativo de Tijmen Schep é uma excelente introdução aos perigos do aprendizado de máquina e da IA. Tijmen Schep, quão normal eu sou?, https://www.hownormalami.eu/ (em inglês).
-
O livro de Jeremy Howard e Sylvain Gugger Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD fornece uma ótima introdução ao aprendizado de máquina. Embora utilize Python, os exemplos são diretos o suficiente para a maioria dos iniciantes seguirem e são relativamente simples de recriar em outras linguagens. Jeremy Howard e Sylvain Gugger. Aprendizado profundo para codificadores com fastai e PyTorch: aplicativos de IA sem doutorado. O’Reilly Media, Inc., 2020.
-
Eles também têm uma série de vídeos gratuitos que cobrem grande parte do material do livro. freeCodeCamp.org, Practical Deep Learning for Coders - Full Course from fast.ai and Jeremy Howard, YouTube video series, 2020, https://youtu.be/0oyCUWLL_fU (em inglês).
-
Grokking Deep Learning de Andrew Task é um livro maravilhoso que fornece uma introdução suave a alguns dos conceitos matemáticos mais avançados em aprendizado de máquina. André Tarefa. Grokking Deep Learning. Manning Publicações, 2019.
-
David Dao faz a curadoria de uma lista atual de algumas das maneiras perigosas pelas quais a IA tem sido utilizada e perpetua a desigualdade. David Dao, Awful AI, https://github.com/daviddao/awful-ai (em inglês).
Notas finais
-
Jon Duckett, JavaScript and jQuery: Interactive Front End Development, (Wiley, 2014). ↩
-
Karthikeyan NG, Arun Padmanabhan, Matt R. Cole, Mobile Artificial Intelligence Projects, (Packt Publishing. 2019). ↩
-
McCulloch, W.S., Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics 5, 115–133 (1943). https://doi.org/10.1007/BF02478259 ↩
-
Andrew Glassner, Deep Learning a Visual Approach, (No Starch Press, 2021), 315. ↩
-
Erik Reppel, “Visualizing parts of Convolutional Neural Networks using Keras and Cats”, Hackernoon, acessado em 23 de dezembro de 2022, https://hackernoon.com/visualizing-parts-of-convolutional-neural-networks-using-keras-and-cats-5cc01b214e59. ↩