This is the draft website for Programming Historian lessons under review. Do not link to these pages.
For the published site, go to https://programminghistorian.org
Contents
- Objetivos da lição
- Estrutura da lição
- Leitura escalável, uma porta de entrada para recém-chegados aos métodos digitais
- A leitura escalável
- Dados e pré-requisitos
- Passo 1: Explorar cronologicamente o conjunto de dados
- Passo 2: Explorar o conjunto de dados criando categorias analíticas binárias
- Passo 3: Seleção reproduzível e sistemática de dados para close reading
- Exemplo de uma seleção reproduzível e sistemática de dados para close reading: dados do Twitter
- Criar um conjunto de dados dos 20 tweets com mais likes (de contas verificadas e não verificadas)
- Inspecionar a nossa nova dafaframe
- Exportar o novo conjunto de dados como um ficheiro JSON
- Criar um novo conjunto de dados do top 20 de tweets com mais likes (apenas de contas não verificadas)
- Inspecionar a nossa nova dataframe (apenas para contas não verificadas)
- Exportar o novo conjunto de dados como ficheiro JSON
- Exemplo de uma seleção reproduzível e sistemática de dados para close reading: dados do Twitter
- Conclusão: avançar com close reading
- Dicas para trabalhar com dados do Twitter
- Referências
Objetivos da lição
Esta lição permitirá aos leitores:
-
Configurar um fluxo de trabalho em que se utilize uma leitura exploratória e distante como contexto para orientar a seleção de dados individuais para close reading (em português, leitura próxima)
-
Empregar analises exploratórias para encontrar padrões em dados estruturados
-
Aplicar e combinar funções de filtro e arranjo em R (se não tiver ou tiver pouco conhecimento em R, recomendamos que veja a lição Noções básicas de R com dados tabulares).
Estrutura da lição
Nesta lição, apresentamos um fluxo de trabalho para leitura escalável de dados estruturados, combinando a interpretação detalhada de dados individuais e a análise estatística de todo o conjunto de dados. A lição está dividida em dois caminhos paralelos:
-
Um caminho geral, que sugere uma forma de trabalhar analiticamente com dados estruturados em que distant reading (em português, leitura distante) de um grande conjunto de dados é usado como contexto para uma leitura detalhada de dados distintos.
-
Um caminho de exemplo, em que utilizamos funções simples na linguagem de programação R para analisar dados do Twitter.
Combinando estes dois caminhos, mostramos como a leitura escalável pode ser utilizada para analisar uma ampla variedade de dados estruturados. O nosso fluxo de trabalho de leitura escalável sugerido inclui duas abordagens de distant reading que ajudarão os pesquisadores a explorar e analisar características gerais em grandes conjuntos de dados (cronologicamente e em relação a estruturas binárias). É ainda uma forma de utilizar distante reading para selecionar dados individuais para close reading de uma maneira sistemática e reproduzível.
Leitura escalável, uma porta de entrada para recém-chegados aos métodos digitais
A combinação de close reading e distant reading apresentada nesta lição pretende constituir uma porta de entrada para os métodos digitais para estudantes e académicos que são novos na incorporação do pensamento computacional no seu trabalho. Quando associa distante reading a grandes conjuntos de dados e close reading a dados individuais, cria uma ponte entre os métodos computacionais e os métodos da curadoria manual usualmente aplicados nas disciplinas das humanidades. Na nossa experiência, a leitura escalável – em que a análise de todo o conjunto de dados representa uma variedade de contextos para close reading – facilita o ultrapassar das dificuldades que os recém-chegados poderão encontrar quando questionam o seu material que pode ser explorado e analisado utilizando o pensamento computacional. A maneira reproduzível para a seleção de casos individuais para uma inspeção mais próxima/detalhada remete diretamente, por exemplo, para questões centrais das disciplinas da história e da sociologia, quando se considera a relação entre um contexto geral e um estudo de caso. Não obstante, também pode ser usado noutras disciplinas das humanidades que operam com quadros analíticos semelhantes.
A leitura escalável
Originalmente usámos o fluxo de trabalho apresentado abaixo para analisar a lembrança do programa de televisão Rua Sésamo (em inglês, Sesame Street) no Twitter. Utilizámos a combinação de close reading e distant reading para compreender como certos eventos geraram discussão sobre a história da Rua Sésamo, que usuários do Twitter dominaram o discurso sobre este tema e que partes da história do programa enfatizaram. O exemplo abaixo utiliza um pequeno conjunto de dados relacionado com tweets sobre a Rua Sésamo. No entanto, a mesma estrutura analítica também pode ser utilizada para analisar muitos outros tipos de dados estruturados. Para demonstrar a aplicabilidade do fluxo de trabalho a outros tipos de dados, discutimos como pode ser adaptado a um conjunto de dados estruturados das coleções digitalizadas da Galeria Nacional da Dinamarca. Os dados desta são muito diferentes dos do Twitter utilizados no caminho de exemplo desta lição, mas ideia geral de utilização de distant reading para contextualizar close reading funciona igualmente bem.
O fluxo de trabalho para a leitura escalável de dados estruturados sugerido abaixo tem três passos:
-
Explorar cronologicamente o conjunto de dados.
No conjunto de dados do Twitter, exploramos como um fenómeno específico ganha força na plataforma durante um certo período de tempo. No caso dos dados da Galeria Nacional, poderíamos ter analisado a distribuição temporal das suas coleções, por exemplo, de acordo com o seu ano de aquisição ou de quando as obras de arte foram produzidas. -
Explorar o conjunto de dados criando categorias analíticas binárias.
Este passo sugere a utilização de categorias de metadados existentes num conjunto de dados para criar questões de natureza binária. Em outras palavras, questões que podem ser respondidas com uma lógica de sim/não ou verdadeiro/falso. Usamos a criação de uma estrutura binária analítica como forma de analisar algumas tendências gerais dos conjuntos de dados. No conjunto de dados do Twitter, exploramos o uso de hashtags (versus o seu não uso); a distribuição de tweets de contas verificadas versus não verificadas; e o nível de interação entre estes dois tipos de contas. No caso dos dados da Galeria Nacional poderíamos ter utilizado os metadados registados sobre o tipo de obra de arte, o género e a nacionalidade para explorar a representatividade das coleções dinamarquesas versus das coleções de artistas internacionais; pinturas versus não-pinturas; ou artistas registados como sendo do sexo feminino e de sexo desconhecido versus artistas registados como sendo do sexo masculino, etc. -
Seleção sistemática de dados individuais para close reading.
Este passo sugere uma forma sistemática e reproduzível de selecionar dados individuais para close reading. No conjunto de dados do Twitter, selecionamos os 20 tweets com mais likes para close reading. No caso dos dados da Galeria Nacional, por exemplo, o top 20 poderia ser constituído pelos itens mais exibidos, emprestados ou anotados.
Abaixo, estão explicados, de uma forma geral, os três passos, bem como especificamente, utilizando o exemplo do Twitter.
Dados e pré-requisitos
Se quiser reproduzir a análise que apresentamos abaixo, usando não apenas o fluxo de trabalho concetual, mas também o código, assumimos que já tem um conjunto de dados que contenha dados do Twitter em formato JSON. Se não tiver, pode obter um das seguintes formas:
-
Usando uma das APIs do Twitter, por exemplo, a chamada API “Essential”, disponível gratuitamente e que foi o meio para chegarmos ao conjunto de dados utilizado neste exemplo (veja mais sobre APIs nesta secção da lição Introduction to Populating a Website with API Data (em inglês)). Este link leva-o para as opções da API do Twitter (em inglês). Pode usar o pacote ‘rtweet’, com a sua própria conta do Twitter, para aceder à API Twitter através do R, conforme descrito abaixo.
-
Usando o Beginner’s Guide to Twitter Data (em inglês) do Programming Historian. Mas, em vez de escolher uma saída CSV, escolha JSON.
O R trabalha com pacotes, cada um adicionando numerosas funcionalizadas às suas funções base. Os pacotes são, frequentemente, código criado pela comunidade, disponibilizado para reutilização. Quando os utiliza está a recorrer ao trabalho de outros codificadores. Neste exemplo, os pacotes mais importantes são os seguintes:
rtweet, tidyverse, lubridate e jsonlite. Para os instalar no R veja esta secção da lição Processamento Básico de Texto em R. Para usar pacotes no R estes têm de ser carregados com o comando library(), conforme abaixo:
library(rtweet)
library(tidyverse)
library(lubridate)
library(jsonlite)
Para seguir os exemplos de código, garanta que instalou e carregou os seguintes pacotes no R:
tidyverse
O pacote “tidyverse” carrega várias bibliotecas que são úteis quando trabalhamos com dados. Para mais informações sobre como usar o tidyverse veja https://www.tidyverse.org.1
lubridate
O pacote “lubridate” é usado para gerir diferentes formatos de dados no R e realizar operações com eles. Este pacote foi criado por um grupo por detrás do pacote “tidyverse”, embora não seja uma função de base deste.2
jsonlite
O pacote “jsonlite” é destinado a trabalhar com dataformat JavaScript Object Notation (JSON), um formato usado para trocar dados na internet. Para mais informações sobre o pacote jsonlite veja https://cran.r-project.org/web/packages/jsonlite/index.html.3
Se já tiver um ficheiro JSON com os seus dados do Twitter, pode usar o comando fromJSON do pacote “jsonlite” para carregá-los no ambiente do R.
Obter um pequeno conjunto de dados de teste
rtweet
O pacote “rtweet” é uma implementação de chamadas criadas para recolher e organizar dados do Twitter através do Twitter’s REST e transmitir Interfaces de Programação de Aplicações (API), que podem ser encontradas no seguinte URL: https://developer.twitter.com/en/docs.4
Se ainda não tiver dados do Twitter e quiser seguir os exemplos de código passo a passo, pode usar a sua conta do Twitter e o comando search_tweets() do pacote “rtweet” para importar dados para o ambiente do R. Trar-lhe-á 18.000 tweets dos últimos nove dias. Estes são escolhidos como um número elevado e arbitrário para assegurar que obtemos todos os tweets disponíveis. Os dados serão estruturados como um dataframe (em português, quadro de dados). Tal como uma folha de cálculo, um dataframe organiza os dados numa tabela bidimensional de linhas e colunas. Ao copiar o código abaixo, conseguirá gerar a dataframe baseada numa pesquisa de texto livre do termo “sesamestreet” de forma a seguir o nosso exemplo. O parâmetro q representa a nossa consulta (em inglês, query). Já o parâmetro n determina quantos tweets serão obtidos.
sesamestreet_data <- search_tweets(q = "sesamestreet", n = 18000)
Passo 1: Explorar cronologicamente o conjunto de dados
Explorar as dimensões cronológicas de um conjunto de dados pode facilitar uma primeira revisão analítica dos dados. Se está a estudar a evolução de um único fenómeno ao longo do tempo (como o nosso caso de eventos específicos que estimularam discussões sobre a Rua Sésamo), compreender como este fenómeno ganhou força e/ou o seu interesse diminuiu pode ser relevante. Pode ser o primeiro passo para compreender como todos os dados recolhidos se relacionam com o fenómeno ao longo do tempo. Análises de dispersão temporal podem relacionar não apenas um evento único, mas também a distribuição total baseada numa variedade de categorias. Por exemplo, se quiser trabalhar dados da Galeria Nacional, pode querer explorar a distribuição das suas coleções segundo períodos históricos, de forma a compreender que períodos possuem uma maior representatividade no conjunto de dados. O conhecimento da dispersão temporal de todo o conjunto de dados pode ajudar a contextualizar dados individuais selecionados para close reading no Passo 3, pois dar-nos-á uma ideia de como um dado específico se relaciona com a cronologia de todo o conjunto de dados.
Exemplos de dispersão espacial de conjuntos de dados: dados do Twitter
Neste exemplo, compreenderá o que se falou sobre a Rua Sésamo num determinado período de tempo. Também observará quantos tweets usaram o hashtag oficial “#sesamestreet” durante esse período.
A operação seguinte, começa com algum processamento de dados antes de passar à produção da visualização. Irá colocar duas questões aos dados:
-
Em primeiro lugar, quer saber a dispersão temporal dos tweets ao longo do tempo.
-
Em segundo lugar, quer saber quantos desses tweets têm a hashtag
”#sesamestreet”.
A segunda questão, em particular, requer alguma manipulação dos dados antes de ser possível obter uma resposta.
sesamestreet_data %>%
mutate(has_sesame_ht = str_detect(text, regex("#sesamestreet", ignore_case = TRUE))) %>%
mutate(date = date(created_at)) %>%
count(date, has_sesame_ht)
## # A tibble: 20 x 3
## date has_sesame_ht n
## <date> <lgl> <int>
## 1 2021-12-04 FALSE 99
## 2 2021-12-04 TRUE 17
## 3 2021-12-05 FALSE 165
## 4 2021-12-05 TRUE 53
## 5 2021-12-06 FALSE 373
## 6 2021-12-06 TRUE 62
## 7 2021-12-07 FALSE 265
## 8 2021-12-07 TRUE 86
## 9 2021-12-08 FALSE 187
## 10 2021-12-08 TRUE 93
## 11 2021-12-09 FALSE 150
## 12 2021-12-09 TRUE 55
## 13 2021-12-10 FALSE 142
## 14 2021-12-10 TRUE 59
## 15 2021-12-11 FALSE 196
## 16 2021-12-11 TRUE 41
## 17 2021-12-12 FALSE 255
## 18 2021-12-12 TRUE 44
## 19 2021-12-13 FALSE 55
## 20 2021-12-13 TRUE 35
O processo aqui apresentado cria uma nova coluna que tem o valor TRUE (em português, verdadeiro) se o tweet contém a hashtag e FALSE (em português, falso) se não possui. Tal é feito com o comando mutate(), que cria uma nova coluna chamada “has_sesame_ht” (em português, tem_sesamo_ht). Para colocar os valores TRUE/FALSE na coluna usa o comando str_detect(). Este último faz a deteção na coluna “text” (em português, texto) que tem o tweet. De seguida, indica o que deteta. Aqui utiliza o comando regex() em str_detect() e, ao fazê-lo, pode especificar que está interessado em todas as variantes do hashtag (por exemplo, #SesameStreet, #Sesamestreet, #sesamestreet, #SESAMESTREET, etc.). Tal é conseguido ao colocar “ignore_case = TRUE” (em português, ignore_caso = VERDADEIRO) no comando regex() que aplica a expressão regular aos seus dados. Expressões regulares podem ser vistas como uma extensão do comando search-and-replace (em português, pesquisa-e-substitui). Se quer explorar mais expressões regulares, pode ler o artigo Understanding Regular Expressions (em inglês).
O próximo passo é outro comando mutate(), no qual cria uma nova coluna com o cabeçalho “date” (em português, data). Esta coluna conterá simplesmente a data dos tweets, em vez de todo o registo do Twitter, que tem não só a data, mas também a hora, o minuto e segundo do post. Isto é obtido através do comando date() do pacote “lubridate”, que está preparado para extrair a data da coluna “created_at” (em português, criado_em). Por último, use o comando count do pacote “tidyverse” para contabilizar os valores TRUE/FALSE na coluna “has_sesame_ht”, com ocorrência por dia no conjunto de dados. O comando pipe (%>%) é usado para encadear comandos de código e é explicado mais à frente nesta secção.
Por favor tenha em atenção que os seus dados podem ser ligeiramente diferentes dos nossos, uma vez que não foram recolhidos na mesma data. As conversas sobre a Rua Sésamo presentes no seu conjunto de dados não serão iguais às que aconteceram antes de 13 de dezembro, quando recolhemos os dados para o nosso exemplo.
sesamestreet_data%>%
mutate(has_sesame_ht = str_detect(text, regex("#sesamestreet", ignore_case = TRUE))) %>%
mutate(date = date(created_at)) %>%
count(date, has_sesame_ht) %>%
ggplot(aes(date, n)) +
geom_line(aes(linetype=has_sesame_ht)) +
scale_linetype(labels = c("No #sesamestreet", "#sesamestreet")) +
scale_x_date(date_breaks = "1 day", date_labels = "%b %d") +
scale_y_continuous(breaks = seq(0, 400, by = 50)) +
theme(axis.text.x=element_text(angle=40, hjust=1)) +
labs(y="Number of Tweets", x="Date", caption = "Total number of tweets: 2432") +
guides(linetype = guide_legend(title = "Whether or not the\ntweet contains \n#sesamestreet"))
labs(title = “Figure 1 - Daily tweets dispersed on whether or not they\ncontain #sesamestreet”, y=”Number of Tweets”, x=”Date”, subtitle = “Period: 4 december 2021 - 13 december 2021”, caption = “Total number of tweets: 2.413”) +
guides(linetype = guide_legend(title = “Whether or not the\ntweet contains \n#sesamestreet”))
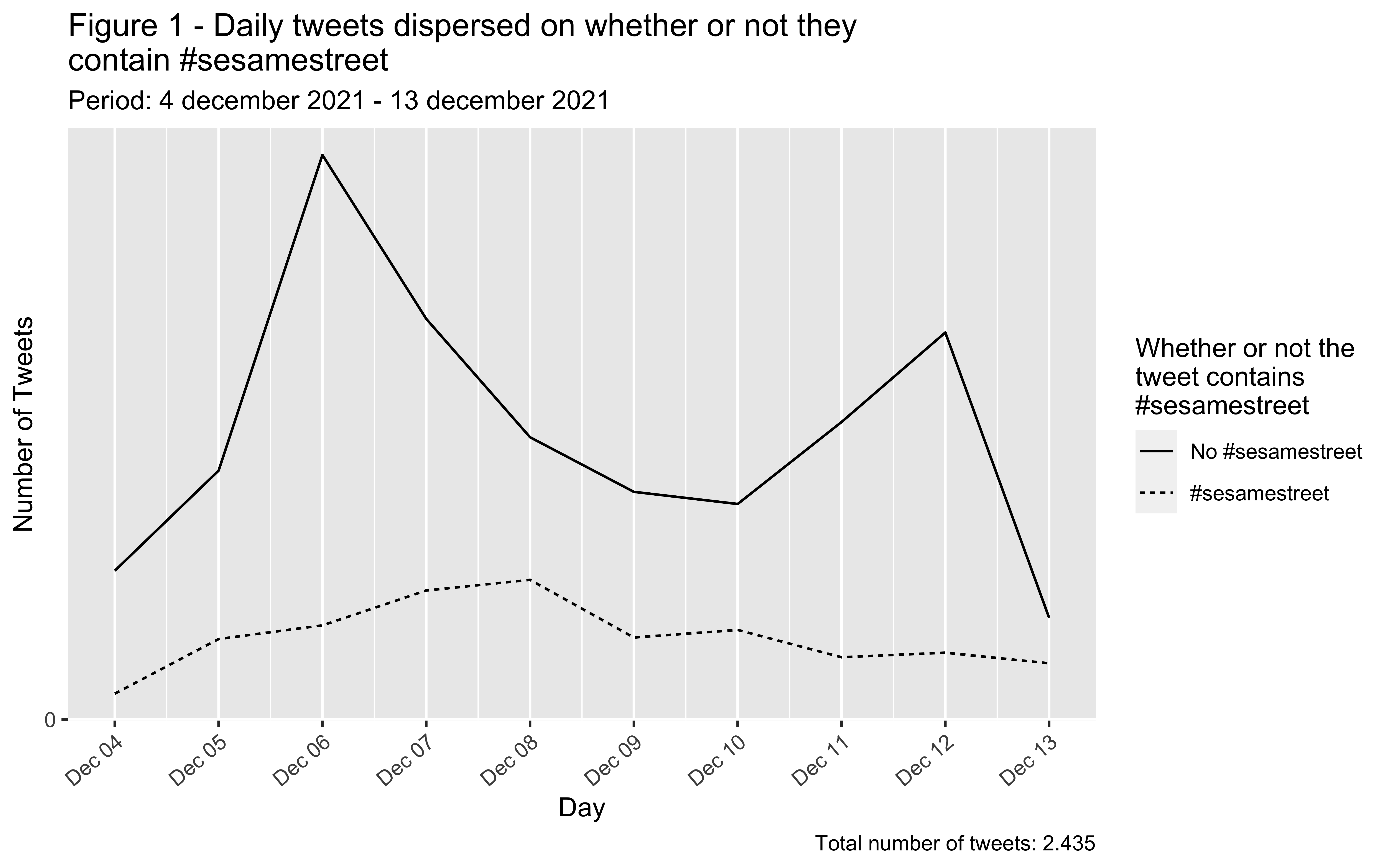
Tweets diários entre 4 de dezembro de 2021 e 13 de dezembro de 2021, dispersos consoante se contêm ou não ‘#sesamestreet’. Os tweets deste período foram recolhidos pela pesquisa livre do termo ‘sesamestreet’ sem o hashtag. O número total de tweets devolvidos foi 2.413.
Irá agora visualizar os seus resultados. Ao usar o código ‘ggplot(aes(date, n)) +’, está a criar a visualização das quatro linhas anteriores (que transformaram os dados para nos ajudar a explorar a cronologia dos tweets com e sem o hashtag oficial “#sesamestreet”). Para recomeçar onde acabou no anterior trecho de código, continue com o comando ggplot(), que é o pacote gráfico do “tidyverse”. Neste comando indicamos que a etiqueta do eixo x será “Date” (em português, data) e que a etiqueta do eixo y será “Number of Tweets” (em português, número de tweets) baseado em valores TRUE/FALSE. O comando seguinte necessário para criar a visualização é geom_line(), no qual específica “linetype=has_sesame_ht” (em português, linhatipo=tem_sesame_ht), que divide duas linhas na visualização, uma representativa de TRUE e a outra de FALSE.
As linhas de código após o argumento geom_line() ajustam a estética da visualização. Neste contexto, a estética corresponde à representação visual dos dados na sua visualização. scale_linetype() indica ao R as etiquetas das linhas. scale_x_date() e scale_y_continuous() modificam a aparência dos eixos x e y, respetivamente. Por fim, os argumentos labs() e guides() são usados para criar textos descritivos na visualização.
Lembre-se de alterar os títulos no código abaixo para corresponderem ao seu conjunto de dados (como explicámos acima, provavelmente não estará a fazer esta lição no dia 13 de dezembro de 2021). Encontrará os títulos em labs().
Agora deverá ter um gráfico que representa a dispersão temporal dos tweets do seu conjunto de dados. Este gráfico mostra a distribuição dos tweets recolhidos durante o período de pesquisa. Considerando os tweets da Rua Sésamo, o nosso gráfico demonstra que a maioria destes foram publicados sem o hashtag #sesamestreet. Adicionalmente, podemos identificar dois picos no gráfico, um a 6 de dezembro e outro a 12 de dezembro. Estes indicam-nos que existiu uma maior atividade sobre a Rua Sésamo nestas duas datas face a todas as restantes. De seguida, passaremos à exploração binária de algumas características distintivas do conjunto de dados.
Passo 2: Explorar o conjunto de dados criando categorias analíticas binárias
Usar uma lógica binária para explorar um conjunto de dados pode ser uma primeira maneira e, comparada com outros métodos digitais, relativamente simples de compreender relações importantes no seu conjunto de dados. Relações binárias são fáceis de contabilizar utilizando código computacional e podem revelar estruturas sistemáticas e definidoras dos seus dados. No nosso caso, estamos interessados nas relações de poder no Twitter e, mais genericamente, na esfera pública. Desta forma, explorámos as diferenças entre as contas designadas de verificadas e as não verificadas – contas verificadas são aquelas que estão marcadas com um distintivo que indica que o usuário é distinto e autêntico, devido ao seu reconhecimento público fora da plataforma. No entanto, poderá estar interessado noutra coisa, por exemplo, em quantos tweets fora retweets ou originais. Em ambos os casos, pode utilizar os metadados registados para o conjunto de dados para formular a questão que pode ser respondida utilizando uma lógica binária (o tweet vem de uma conta verificada, sim ou não?; o tweet é um retweet, sim ou não?). Ou, suponha que estamos a trabalhar com dados da Galeria Nacional. Nesse caso, pode querer explorar preferências de género nas coleções, descobrindo se a instituição favoreceu a aquisição de obras de arte de pessoas registadas no seu catálogo como pertencendo ao sexo masculino. Para fazê-lo, pode organizar o seu conjunto de dados para contabilizar os artistas masculinos (há artistas registados como sendo do sexo masculino, sim ou não?). Ou, se estiver interessado na distribuição de coleções de artistas dinamarqueses versus de artistas internacionais, os dados podem ser organizados numa estrutura binária permitindo-lhe responder à questão: este artista está registado como dinamarquês, sim ou não?
As relações binárias podem formar um contexto para o seu close reading de dados selecionados no Passo 3. Conhecer a distribuição dos dados em duas categorias também lhe permitirá estabelecer a representatividade de dados individuais em relação à distribuição por categorias de todo o conjunto. Por exemplo, se no Passo 3 escolher trabalhar com os 20 tweets com um maior número de likes, reparará que mesmo que existam muitos tweets de contas verificadas entre a amostra escolhida, estas contas podem não estar bem representadas no total do conjunto de dados. Assim, os 20 tweets com um maior número de likes que selecionou não são representativos de tweets da maioria das contas no nosso conjunto de dados. Pelo contrário, representam uma percentagem pequena, mas com um grande número de likes. Ou, se escolher trabalhar com as 20 obras de arte exibidas com maior frequência num conjunto de dados da Galeria Nacional, uma análise binária de artistas dinamarqueses versus artistas não dinamarqueses poderá permitir-lhe ver que, mesmo se esses trabalhos fossem todos pintados por artistas internacionais, esses artistas tinham pouca representatividade no conjunto das coleções da Galeria Nacional.
Exemplo de exploração binária: dados do Twitter
Neste exemplo, demonstramos o fluxo de trabalho que usaria se estivesse interessado em explorar a distribuição de contas verificadas versus não verificadas que publicaram tweets sobre a Rua Sésamo.
Sugerimos que processe os seus dados passo a passo, Seguindo a lógica do pipe (%>%) no R. Quando consolidar esta ideia, o restante processamento dos dados será mais fácil de ler e compreender. O objetivo geral desta secção é explicar como os tweets recolhidos foram dispersos entre contas não verificadas e contas verificadas, bem como demonstrar como visualizamos o resultado.
sesamestreet_data %>%
count(verified)
## # A tibble: 2 x 2
## verified n
## * <lgl> <int>
## 1 FALSE 2368
## 2 TRUE 64
Usando o pipe %>% passa os dados para baixo – os dados estão a fluir pelo cano como água! Aqui ‘pour’ (em português, derrama) os dados para o comando count (em português, contagem) e pede que sejam contabilizados os valores na coluna “verified” (em português, verificado). O valor será “TRUE” se a conta for verificada ou “FALSE” se não for verificada.
Agora que contou os valores poderá fazer mais sentido tê-los em percentagem. Assim, o nosso próximo passo será adicionar outro pipe e um snippet de código para criar uma nova coluna que contenha o número total de tweets do nosso conjunto de dados – isto será necessário para, mais tarde, calcular as percentagens.
sesamestreet_data %>%
count(verified) %>%
mutate(total = nrow(sesamestreet_data))
## # A tibble: 2 x 3
## verified n total
## * <lgl> <int> <int>
## 1 FALSE 2368 2432
## 2 TRUE 64 2432
Poderá encontrar o número total de tweets usando o comando nrow(), que nos dá o número de linhas da dataframe. Neste conjunto de dados uma linha é equivalente a um tweet.
Usando um outro pipe, criará agora uma nova coluna chamada “percentage” (em português, percentagem), onde calculará e armazenará a dispersão de percentagem entre tweets verificados e não verificados:
sesamestreet_data %>%
count(verified) %>%
mutate(total = nrow(sesamestreet_data)) %>%
mutate(pct = (n / total) * 100)
## # A tibble: 2 x 4
## verified n total pct
## * <lgl> <int> <int> <dbl>
## 1 FALSE 2368 2432 97.4
## 2 TRUE 64 2432 2.63
O próximo passo é visualizar este resultado. Aqui utiliza o pacote “ggplot2” para criar um gráfico de barras:
sesamestreet_data %>%
count(verified) %>%
mutate(total = nrow(sesamestreet_data)) %>%
mutate(pct = (n / total) * 100) %>%
ggplot(aes(x = verified, y = pct)) +
geom_col() +
scale_x_discrete(labels=c("FALSE" = "Not Verified", "TRUE" = "Verified"))+
labs(x = "Verified status",
y = "Percentage",
caption = "Total number of tweets: 2432") +
theme(axis.text.y = element_text(angle = 14, hjust = 1))
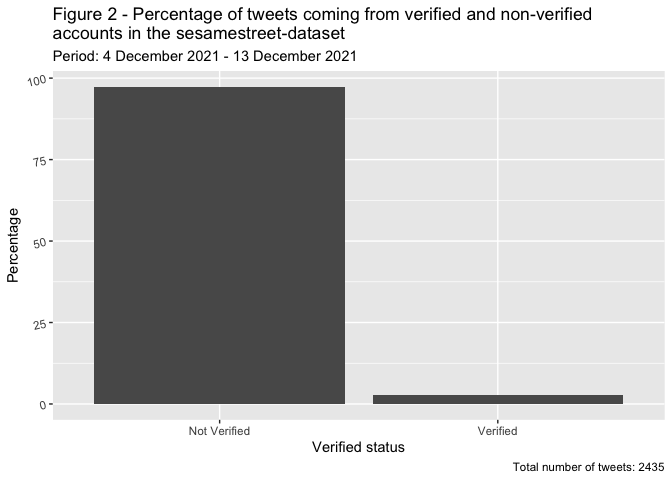
Percentagem de tweets postados por contas verificadas e não verificadas no conjunto de dados sesamestreet entre 4 de dezembro de 2021 e 13 de dezembro de 2021. O número total de tweets foi 2.435.
Comparativamente às visualizações anteriores, que traçavam os tweets ao longo do tempo, agora usamos o comando geom_col para criar colunas. Repare que quando começa a trabalhar no ggplot o pipe (%>%) é substituído por um+. Esta figura ilustra que a maioria dos tweets sobre a Rua Sésamo foram criados por contas de usuários não verificados. Tal pode indicar que a Rua Sésamo é um tópico popular, politizado e público no Twitter, no qual pessoas sem contas verificadas estão envolvidas.
Interação com contas verificadas versus não verificadas
Nesta parte do exemplo demonstramos que o fluxo de trabalho que usámos para pesquisar o quanto as pessoas interagiam com tweets de contas verificadas versus com tweets de contas não verificadas. Escolhemos contar likes como uma forma de medir essa interação. Contrastando o nível de interação destes dois tipos de contas ajudará a estimar se poucas contas verificadas possuem um maior poder, não obstante a sua fraca representação geral, pois as pessoas interagem muito mais com tweets de usuários verificados do que com tweets de usuários não verificados.
sesamestreet_data %>%
group_by(verified) %>%
summarise(mean = mean(favorite_count))
## # A tibble: 2 x 2
## verified mean
## * <lgl> <dbl>
## 1 FALSE 0.892
## 2 TRUE 114.
Usando o código acima, agrupa o conjunto de dados com base no status do tweet: verificado = TRUE e não verificado = FALSE. Depois de usar o comando de agrupamento, todas as operações posteriores serão feitas em todo o grupo. Em outras palavras, todos os tweets postados por contas não verificadas serão tratados como um grupo e todos os tweets postados por contas verificadas serão tratados como outro. O próximo passo é usar o comando summarise para calcular a média de “favorite_count” (em português, favorito_conta) dentro dos tweets de contas verificadas e não verificadas (“favorito” é o termo do conjunto de dados para like).
Neste próximo passo, adiciona o resultado do cálculo acima à dataframe. Use uma nova coluna chamada “interaction” (em português, interação) para especificar que é “favorite_count”.
interactions <- sesamestreet_data %>%
group_by(verified) %>%
summarise(gns = mean(favorite_count)) %>%
mutate(interaction = "favorite_count")
Utilizando este método passa a ter uma dataframe que contem os valores médios de diferentes interações, o que torna possível passar os dados para o pacote ggplot para visualização, o que é feito desta forma:
interactions %>%
add_row(
sesamestreet_data %>%
group_by(verified) %>%
summarise(gns = mean(retweet_count), .groups = "drop") %>%
mutate(interaction = "retweet_count")) -> interactions
interactions %>%
ggplot(aes(x = verified, y = mean)) +
geom_col() +
facet_wrap(~interaction, nrow = 1) +
labs(caption = "Total number of tweets: 2411",
x = "Verified status",
y = "Average of engagements counts") +
scale_x_discrete(labels=c("FALSE" = "Not Verified", "TRUE" = "Verified"))
A visualização é semelhante aos gráficos anteriores, mas a diferença aqui é a facet_wrap, que cria um gráfico de três barras para cada tipo de interação. O gráfico ilustra que tweets de contas verificadas têm mais atenção do que aqueles que são publicados por contas não verificadas.
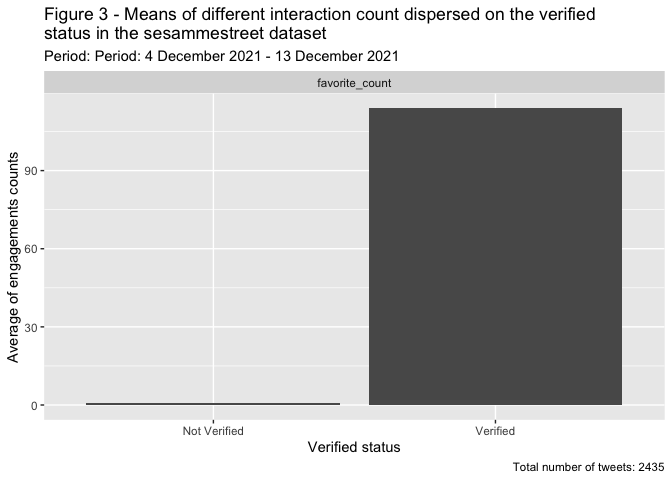
Médias das interações de diferentes contas dispersas pelo status verificado de 4 de dezembro de 2021 a 13 de dezembro 2021. O número total de tweets foi 2.435.
Passo 3: Seleção reproduzível e sistemática de dados para close reading
Uma das grandes vantagens em combinar close reading e distant reading é a possibilidade de fazer uma seleção de dados sistemática e reproduzível para close reading. Ao explorar o conjunto de dados através de dois métodos diferentes de distant reading nos Passos 1 e 2, consegue usar essas perceções para selecionar sistematicamente dados específicos para close reading. Este último permitir-lhe-á explorar tendências interessantes dos seus dados e descompactar determinados fenómenos para os pesquisar em profundidade.
A quantidade de dados que seleciona para close reading depende do fenómeno de pesquisa, do tempo que tem e da complexidade dos dados. Por exemplo, analisar obras de arte individualmente pode consumir mais tempo do que ler tweets individuais mas, claro, isto varia de acordo com o seu objetivo. Portanto, é importante que seja sistemático na seleção dos dados para assegurar a adequação às suas perguntas de pesquisa. No nosso caso, queríamos saber mais sobre como os tweets com um maior número de likes representaram a Rua Sésamo: como falaram sobre o programa e a sua história?, os tweets estavam ligados a outro media?, e como era o programa representado visualmente (por imagens, ligações para vídeos, memes, etc.)? Considerando o interesse da relação observada entre a baixa representatividade, mas alta interação dos tweets de contas verificadas, pretendemos fazer uma análise de close reading dos 20 tweets com um maior número de likes de todo o conjunto (de contas verificadas e não verificadas), mas também dos 20 tweets com mais likes postados apenas por contas não verificadas – para verificar se estes eram diferentes na forma como abordavam o programa e a sua história. Escolhemos o top 20 porque esta parece ser uma tarefa fácil de concretizar no tempo que temos disponível.
Se estiver a trabalhar dados da Galeria Nacional, pode querer selecionar as cinco ou dez obras de arte mais exibidas ou emprestadas com maior frequência de artistas dinamarqueses e internacionais. Tal permite-lhe analisar as suas diferenças ou aspetos em comum, conduzindo-o para um close reading de artistas particulares, tipos de obra de arte, motivo, conteúdo, dimensão, período da história de arte, etc.
Exemplo de uma seleção reproduzível e sistemática de dados para close reading: dados do Twitter
Neste exemplo, interessa-nos selecionar o top 20 de tweets com um maior número de likes de todo o conjunto. Podemos prever que muitos destes terão sido publicados por contas verificadas, mas também precisaremos de selecionar os 20 tweets com mais likes de contas não verificadas para poder comparar e contrastar as duas categorias.
Para examinar apenas os tweets originais, comece por filtrar todos os tweets que são retweets.
No canto do topo direito da interface do R Studio, encontrará o “Global Environment” (em português, ambiente global) do R, com a dataframe sesamestreet_data. Clicando nesta última, conseguirá ver as linhas e colunas com os dados do Twitter. Ao observar a coluna “is_retweet” (em português, e_retweet), verá que esta indica se o tweet é ou não um retweet com base nos valores TRUE ou FALSE.
Voltando atrás no código do R, depois de fechar a vista de dataframe pode usar o comando filter para manter apenas os tweets originais (isto é, manter linhas onde o valor de retweet é FALSE). R-markdown é um formato de ficheiro que suporta o código R e texto. Pode organizar os restantes tweets de acordo com o número de likes que cada um recebeu. Este número está na coluna “favorite_count”.
Tanto o comando filter como o comando arrange pertencem ao pacote dplyr, que é parte do tidyverse.
sesamestreet_data %>%
filter(is_retweet == FALSE) %>%
arrange(desc(favorite_count))
(Output removido por motivos de privacidade)
Como pode verificar no “Global Environment”, os dados sesamestreet_data compreendem um total de 2.435 observações (o número irá variar dependendo de quando recolheu os seus dados). Ao correr o código acima, conseguirá calcular quantos tweets originais o seu conjunto de dados tem. A figura aparecerá no seu dataframe. O nosso exemplo de dados conta com 852 tweets originais, mas lembre-se que o seu valor pode ser diferente.
Observando a coluna “favorite_count”, consegue agora observar o número de likes no seu top 20. No nosso exemplo desta amostra contabilizámos acima de 50. Estes números são variáveis, pelo que serão diferentes quando decidir reproduzir este exemplo. Assegure-se de verificar estes números.
Criar um conjunto de dados dos 20 tweets com mais likes (de contas verificadas e não verificadas)
Agora que já sabe que o valor mínimo de “favorite_count” é 50, adicione um segundo comando filter ao trecho de código anterior que tem todas as linhas de “favorite_count” com um valor superior a 50.
Como destacou os 20 tweets com mais likes, pode agora criar um novo conjunto de dados chamado sesamestreet_data_favorite_count_over_50 (em português, ruasesamo_dados_favorito_contagem_acima_50).
sesamestreet_data %>%
filter(is_retweet == FALSE) %>%
filter(favorite_count > 50) %>%
arrange(desc(favorite_count)) -> sesamestreet_data_favorite_count_over_50
Inspecionar a nossa nova dafaframe
Para criar uma visão geral rápida do novo conjunto de dados, use o comando select do pacote dplyr para isolar as variáveis que quer inspecionar. Neste caso, quer isolar as colunas “favorite_count”, “screen_name” (em português, ecra_nome), “verified” e “text”.
sesamestreet_data_favorite_count_over_50 %>%
select(favorite_count, screen_name, verified, text) %>%
arrange(desc(favorite_count))
(Output removido por motivos de privacidade)
Depois organiza-os pelo valor “favorite_count”, utilizando o comando arrange.
Este trecho de código devolve a dataframe que tem os valores para as variáveis que quer isolar: favorite\_count, screen\_name, verified e text. Portanto, é muito mais fácil inspecionar, do que observando todo o conjunto de dados sesamestreet_data_favorite_count_over_50 no seu “Global Environment”.
Exportar o novo conjunto de dados como um ficheiro JSON
Para exportar o seu novo conjunto de dados do ambiente R e salvá-lo como um ficheiro JSON precisa de usar o comando toJSON do pacote jsonlite. Escolhemos o formato JSON porque os nossos dados do Twitter sã ocompexos e incluem listas dentro de linhas, por exemplo existem vários hashtags numa única linha. Esta situação é difícil de contornar nos formatos de dados populares como o CSV, motivo pelo qual escolhemos o JSON.
Para assegurar que os seus dados estão organizados e bem estruturados, anote em todos os seus ficheiros de dados de close reading a mesma informação:
-
Quantos tweets/observações tem o conjunto de dados?
-
Em função de que variáveis estão os dados organizados?
-
Os tweets são postados de todos os tipos de contas ou apenas de contas verificadas?
-
Em que ano foram produzidos os dados?
Top_20_liked_tweets <- jsonlite::toJSON(sesamestreet_data_favorite_count_over_50)
Após converter os seus dados para o formato de ficheiro JSON, pode usar o comando write da base do R para exportar os dados e salvá-los na sua máquina.
write(Top_20_liked_tweets, "Top_20_liked_tweets.json")
Criar um novo conjunto de dados do top 20 de tweets com mais likes (apenas de contas não verificadas)
Agora pretende ver o top 20 de tweets com mais likes de contas não verificadas.
sesamestreet_data %>%
filter(is_retweet == FALSE) %>%
filter(verified == FALSE) %>%
arrange(desc(favorite_count))
(Output removido por motivos de privacidade)
Para fazê-lo, siga o fluxo de trabalho anterior, mas no primeiro trecho de código inclua um comando extra filter do pacote “dplyr”, que mantem todas as linhas com o valor FALSE na coluna “verified”, removendo assim dos nossos dados todos os tweets que foram produzidos por contas verificadas.
Aqui pode observar quantos tweets do total de 2.435 não foram retweetados e foram criados por contas não verificadas. No nosso exemplo contabilizamos 809. No entanto, este número não será o mesmo no seu caso.
Olhando novamente para a coluna “favorite_count”, procure o número 20 na lista de likes (o 20º tweet com um maior número de likes). Observe quantos likes tem este tweet e configure este valor para “favorite_count”. No nosso exemplo o top 20 de tweets de contas não verificadas tinham uma contagem acima de 15. Desta vez, dois tweets partilham o 20º e o 21º lugares. Portanto, para esta análise terá um top 21 de tweets com mais likes.
sesamestreet_data %>%
filter(is_retweet == FALSE) %>%
filter(verified == FALSE) %>%
filter(favorite_count > 15) %>%
arrange(desc(favorite_count)) -> sesamestreet_data_favorite_count_over_15_non_verified
Agora, pode filtrar os tweets que tiveram likes mais de 15 vezes, organizá-los de forma decrescente daquele que possui um maior número para o menor e criar um novo conjunto de dados no seu “Global Environment” chamado sesamestreet_data_favorite_count_over_15_non_verified (em portugues, ruasesamo_dados_favorito_contagem_acima_15_nao_verificado).
Inspecionar a nossa nova dataframe (apenas para contas não verificadas)
Pode criar, novamente, uma rápida visão do seu conjunto de dados usando os comandos select e arrange como anteriormente, e inspecionar os valores escolhidos na dataframe.
sesamestreet_data_favorite_count_over_15_non_verified %>%
select(favorite_count, screen_name, verified, text) %>%
arrange(desc(favorite_count))
(Output removido por motivos de privacidade)
Exportar o novo conjunto de dados como ficheiro JSON
Novamente, use o comando toJSON para guardar os seus dados para um ficheiro JSON local.
Top_21_liked_tweets_non_verified <- jsonlite::toJSON(sesamestreet_data_favorite_count_over_15_non_verified)
write(Top_21_liked_tweets_non_verified, "Top_21_liked_tweets_non_verified.json")
Agora, deverá ter dois ficheiros JSON guardados no seu diretório, prontos a serem carregados noutro R Markdown para uma análise de close reading. Ou, se preferir, pode inspecionar a coluna de texto dos conjuntos de dados com o seu “Global Environment” do R atual.
Está pronto para copiar os URLs da dataframe e inspecionar os tweets individuais no Twitter. Lembre-se de observar os “Termos do serviço” do Twitter e aja em concordância. Por exemplo, os termos estipulam que não está autorizado a partilhar o seu conjunto de dados com outros, exceto uma lista de IDs dos tweets. Também determina que a correspondência off-Twitter (isto é, a associação de contas a indivíduos) deve seguir muito estritamente as regras e manter limites específicos. Adicionalmente, tem várias restrições se quiser publicar ou citar tweets, etc.
Conclusão: avançar com close reading
Quando escolheu os dados individuais queria close read (Passo 3) os métodos exploratórios iniciais de distant reading (detalhados nos Passo 1 e 2). Estes podem ser combinados como um contexto altamente qualificado para a sua análise aprofundada. Retomando a exploração cronológica (Passo 1), conseguirá identificar a localização dos dados individuais que escolheu face a todo o conjunto de dados. Com este conhecimento, pode considerar que diferença poderá trazer à sua leitura se se localizarem mais cedo ou mais tarde comparativamente à distribuição do conjunto ou que significado pode ser desvendado se o seu conjunto de dados formar um pico. Considerando a análise binária (Passo 2), distante reading Pode ajudar a determinar se dados individuais são representativos de uma tendência do conjunto, bem como que porção do conjunto de dados isto representa relativamente a uma determinada característica. No exemplo que utiliza os dados do Twitter, demonstrámos como close reading de dados selecionados pode ser contextualizado por distant reading. A exploração cronológica pode ajudar a determina onde os tweets selecionados para close reading estão localizados em relação a um evento no qual possa ter interesse. Um tweet postado mais cedo do que a maioria, pode ser considerado parte de um “primeiro avanço” num certo assunto. Por sua vez, um post mais tardio, pode ser mais reflexivo e retrospetivo. Para determiná-lo, pode ter de close read e analisar os tweets usando métodos tradicionais das humanidades, mas distant reading pode ajudar a qualificar e contextualizar a sua análise. O mesmo é verdade para as estruturas binárias e para os critérios usados para selecionar o top 20 de tweets com mais likes. Se souber se um tweet é de uma conta verificada ou não e se foi o que teve um maior número de likes, então pode compará-lo com a tendência geral para estes parâmetros ao longo do conjunto de dados quando fizer close reading. Tal ajudá-lo-á a qualificar o seu argumento para uma análise mais aprofundada de qualquer dado individual, pois saberá o que representa em relação ao evento, discussão ou assunto que está a pesquisar.
Dicas para trabalhar com dados do Twitter
Como mencionado no início desta lição, existem diferentes formas de obter os seus dados. Esta secção da lição pode ajudá-lo a aplicar o código apresentado aos dados que não foram recolhidos com o pacote rtweet.
Se recolheu os seus dados seguindo os passos definidos na lição Beginner’s Guide to Twitter Data (em inglês) percebeu que a data dos tweets aparece num formato que não é compatível com a presente lição. Para tornar o nosso código compatível com os dados recolhidos usando o método do Beginner’s Guide to Twitter Data, a coluna da data terá de ser manipulada usando expressões regulares. Estas têm uma certa complexidade mas, em suma, diga ao seu computador que parte do texto nas colunas deve ser entendido como dia, mês, ano e parte do dia:
df %>%
mutate(date = str_replace(created_at, "^[A-Z][a-z]{2} ([A-Z][a-z]{2}) (\\d{2}) (\\d{2}:\\d{2}:\\d{2}) \\+0000 (\\d{4})",
"\\4-\\1-\\2 \\3")) %>%
mutate(date = ymd_hms(date)) %>%
select(date, created_at, everything())
df$Time <- format(as.POSIXct(df$date,format="%Y-%m-%d %H:%M:%S"),"%H:%M:%S")
df$date <- format(as.POSIXct(df$date,format="%Y.%m-%d %H:%M:%S"),"%Y-%m-%d")
Outras colunas usadas no nosso exemplo também não partilham o mesmo nome daquelas que foram criadas para dados extraídos com a lição Beginner’s Guide to Twitter Data. As nossas colunas “verified” e “text” correspondem às colunas “user.verified” e “full_text”. Tem duas opções: carrega o código de forma a sempre que aparecer “verified” ou “text” escreva, em vez disso, “user.verified” ou “full_text”. Outra abordagem é mudar os nomes das colunas na dataframe, o que pode ser feito com o seguinte código:
df %>%
rename(verified = user.verified) %>%
rename(text = full_text) -> df
Referências
-
Wickham et al., (2019). “Welcome to the Tidyverse”, Journal of Open Source Software, 4(43), https://doi.org/10.21105/joss.01686. ↩
-
Garrett Grolemund and Hadley Wickham (2011). “Dates and Times Made Easy with lubridate”, Journal of Statistical Software, 40(3), 1-25, https://doi.org/10.18637/jss.v040.i03. ↩
-
Jeroen Ooms (2014). “The jsonlite Package: A Practical and Consistent Mapping Between JSON Data and R Objects”, https://doi.org/10.48550/arXiv.1403.2805. ↩
-
Michael W.Kearney, (2019). “rtweet: Collecting and analyzing Twitter data”, Journal of Open Source Software, 4(42), 1829, 1-3. https://doi.org/10.21105/joss.01829. ↩