This is the draft website for Programming Historian lessons under review. Do not link to these pages.
For the published site, go to https://programminghistorian.org
Contents
- Análise de Corpus com Voyant Tools
- Análise de corpus
- O que você aprenderá neste tutorial
- Criando um corpus em texto simples
- Carregar o corpus
- Explorando o corpus
- Sumário dos documentos: características básicas do seu conjunto de textos
- Número de documentos, palavras e palavras únicas
- Respostas às atividades
- Bibliografia
- Notas de Rodapé
Análise de Corpus com Voyant Tools
Neste tutorial você aprenderá como organizar um conjunto de textos para pesquisa, ou seja, os passos básicos da criação de um corpus serão aprendidos. As principais métricas de análise quantitativa de textos também serão aprendidas. Para isso, pretendemos usar uma plataforma que não exige instalação (somente conexão à internet): Voyant Tools (Sinclair e Rockwell, 2016). Esse tutorial foi pensado para ser o primeiro de uma série cada vez mais complexa de métodos da linguística de corpus. Nesse sentido, este texto pode ser considerado como uma das opções de análise de corpus que você pode encontrar no PH (ver por exemplo: “Análise de Corpus com Antconc”).
Análise de corpus
A análise de corpus é um tipo de análise de conteúdo que permite que comparações em larga escala sejam feitas num conjunto de textos ou corpus.
Desde o início da informática, tanto linguistas computacionais quanto especialistas em recuperação da informação têm criado e usado softwares para observar padrões que não são evidentes em uma leitura tradicional ou corroborar hipóteses que intuíam ao ler certos textos, mas que exigiam trabalho árduo, caro e mecânico. Por exemplo, para obter os padrões de uso e desaparecimento de certos termos em um determinado momento era necessário contratar pessoas para revisar manualmente um texto e observar quantas vezes o termo pesquisado apareceu. Rapidamente, observando a capacidade de “contagem” dos computadores, esses especialistas logo escreveram programas que facilitaram a tarefa de criar listas de frequências ou tabelas de concordância (ou seja, tabelas com os contextos esquerdo e direito de um termo). O programa que você aprenderá a usar neste tutorial, está inscrito neste contexto.
O que você aprenderá neste tutorial
Voyant Tools é uma ferramenta baseada na Web que não requer a instalação de qualquer software especializado porque funciona em qualquer computador com conexão à Internet.
Como afirmado neste outro tutorial, esta ferramenta é uma boa porta de entrada para outros métodos mais complexos.
Ao final deste tutorial, você será capaz de:
- Montar um corpus em texto simples.
- Enviar seu corpus para Voyant Tools.
- Compreender e aplicar diferentes técnicas de segmentação de corpus.
- Identificar características básicas do seu conjunto de textos:
- Extensão dos documentos enviados.
- Densidade léxica (chamada densidade de vocabulário na plataforma).
- Média de palavras por frase.
- Ler e entender diferentes estatísticas sobre as palavras: frequência absoluta, frequência normalizada, assimetria estatística e palavras distintas.
- Pesquisar palavras-chave em contexto e “exportar” os dados e visualizações em diferentes formatos (csv, png, html).
Criando um corpus em texto simples
Ainda que o Voyant Tools possa trabalhar com muitos tipos de formatos (HTML, XML, PDF, RTF e MS Word), neste tutorial usaremos texto simples (.txt). O texto simples tem três vantagens fundamentais: não possui nenhuma formatação adicional, não requer um programa especial e não requer conhecimento extra. Os passos para criar um corpus em texto simples são:
1. Buscar textos
A primeira coisa que você deverá fazer é procurar as informações de seu interesse. Para este tutorial, Riva Quiroga e Silvia Gutiérrez prepararam um corpus de discursos anuais de presidentes da Argentina, Chile, Colômbia, México e Peru.1 entre 2006 e 2010, ou seja, dois anos antes e depois da crise econômica de 2008. Este corpus foi disponibilizado sob a licença Creative Commons CC BY 4.0 e você pode usá-lo desde que cite a fonte usando o seguinte identificador:
2. Copiar para editor de texto simples
Uma vez que as informações tenham sido localizadas, o segundo passo é copiar o texto que te interessa desde a primeira até a última palavra e salvá-lo em um editor de texto simples. Por exemplo:
- no Windows poderia ser salvo no Bloco de Notas
- no Mac, em TextEdit;
- no Linux, no Gedit.
3. Salvar arquivo
Quando você salva o texto, deve considerar três coisas essenciais:
A primeira é salvar seus textos em UTF-8, que é um formato padrão de codificação para espanhol e outros idiomas.
O que é utf-8? Embora em nossa tela vejamos que quando digitamos um “É” aparece um “É”; para um computador “É” é uma série de zeros e uns que são interpretados em imagem dependendo do “tradutor” ou “codificador” que está sendo usado. O codificador que contém códigos binários para todos os caracteres usados em espanhol é UTF-8. Continuando com o exemplo “11000011”, é uma string de oito bits - ou seja, oito espaços de informação - que em UTF-8 são interpretados como “É”.
No Windows:

No Mac:

Salvar para UTF-8 no Mac: 1) Abra o TextEdit 2) Cole o texto que deseja salvar 3) Converta para texto simples (opção no menu ‘Formato’) 4) Ao salvar, selecione a codificação ‘UTF-8’ (Creative Corner, 2016).
No Linux

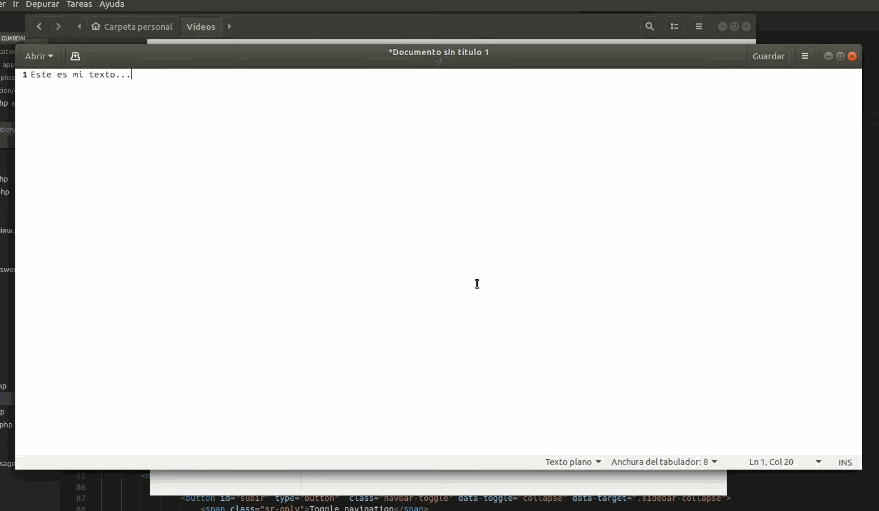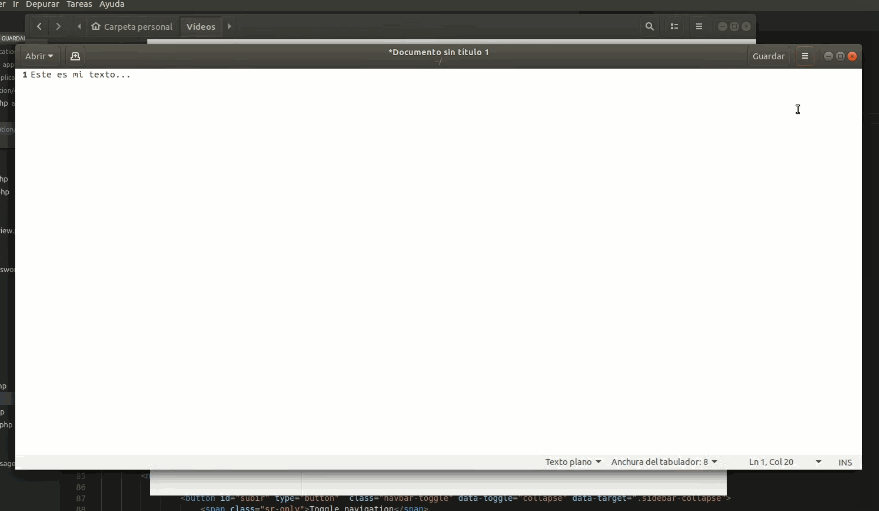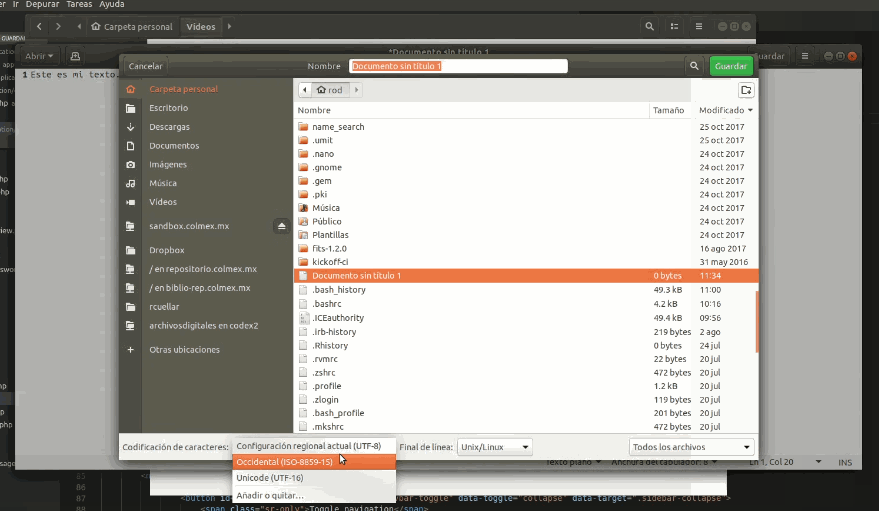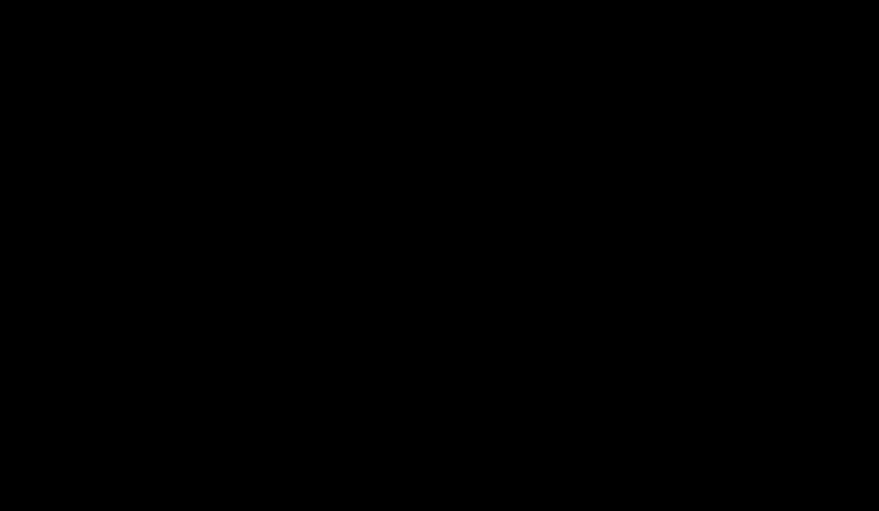
Guardar en UTF-8 en Ubuntu: 1) Abra o Gedit 2) Despois de colar o texto, ao salvar, selecione ‘UTF-8’ na janela ‘Codificação de caracteres’
A segunda é que o nome do seu arquivo não deve conter acentuações ou espaços, isso garantirá que ele possa ser aberto em outros sistemas operacionais.
Por que evitar acentuações e espaços em nomes de arquivos? Por razões semelhantes ao ponto anterior, um arquivo chamado Ébony.txt nem sempre será entendido corretamente por todos os sistemas operacionais pois vários possuem outro codificador padrão. Muitos usam ASCII, por exemplo, que tem apenas sete bits para que o último bit (1) de “1000011” seja interpretado como o início do próximo caractere e a interpretação não é prejudicada.
A terceira é integrar metadados de contexto ( por exemplo, data, gênero, autor, origem ) no nome do arquivo que permite dividir seu corpus de acordo com diferentes critérios e também ler melhor os resultados. Para este tutorial, nomeamos os arquivos com o ano do discurso presidencial, o código do país(ISO 3166-1 alfa-2)e o sobrenome da pessoa que fez o discurso.
2007_mx_calderon.txt tem o ano do discurso dividido por um sublinhado, o código de duas letras do país (México = mx) e o sobrenome do presidente que fez o discurso, Calderón, (sem acento)
Carregar o corpus
Na página principal do Voyant Tools, você encontrará quatro opções simples para carregar textos.2 As duas primeiras opções estão na caixa branca. Nesta caixa você pode colar diretamente um texto que copiou de algum lugar; ou, colar endereços web – separados por vírgulas – dos sites onde os textos que deseja analisar estão localizados. Uma terceira opção é clicar em “Abrir” e selecionar um dos dois corpus que o Voyant tem pré-carregado (peças de Shakespeare ou romances de Austen: ambos em inglês).
Finalmente, a opção que usaremos neste tutorial, e você poderá carregar diretamente os documentos que possui em seu computador. Neste caso, vamos carregar o corpus completo de discursos presidenciais.
Para carregar os materiais clique no ícone que diz “Upload”, abra o explorador de arquivos e, deixando a tecla ‘Shift’ pressionada, selecione todos os arquivos que deseja analisar.

Explorando o corpus
Uma vez que todos os arquivos são carregados, você chegará à interface (‘skin’) que tem cinco ferramentas por padrão. Veja aqui uma breve explicação de cada uma dessas ferramentas:
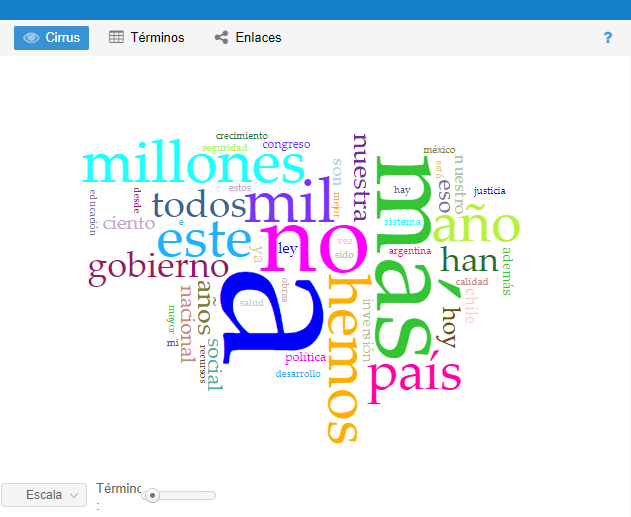
- Cirrus: nuvem de palavras que mostra os termos mais frequentes.
Leitor: espaço para a revisão e leitura dos textos completos com um gráfico de barras que indica a quantidade de texto que cada documento possui.

-
Tendências: gráfico de distribuição que mostra os termos em todo o corpus (ou dentro de um documento quando apenas um é carregado).
-
Sumário: fornece uma visão geral de certas estatísticas textuais do corpus atual.
-
Contextos: contexto que mostra cada ocorrência de uma palavra-chave com algum contexto circundante



Contextos
Sumário dos documentos: características básicas do seu conjunto de textos
Uma das janelas mais informativas do Voyant é o sumário. Aqui temos uma visão geral sobre algumas estatísticas do nosso corpus, funcionando como um bom ponto de partida. Nas seções a seguir, você obterá uma explicação das diferentes medidas que aparecem nesta janela.
Número de documentos, palavras e palavras únicas
A primeira frase que lemos é mais ou menos assim:
Este corpus tem 25 documentos com total de 261.032 palavras e 18.550 formas únicas de palavras. Criado há 8 horas [o texto é o produto de uma tradução semiautomática do inglês e é por isso que parece estranho]
Desde o início com essas informações sabemos exatamente quantos documentos diferentes foram carregados (25); quantas palavras existem no total (261.032); e quantas palavras únicas existem (18.550).
Nas linhas a seguir você encontrará nove atividades que podem ser resolvidas em grupos ou individualmente. Cinco delas têm respostas no final do texto para servir como guia. As quatro últimas estão abertas à reflexão/discussão de quem as realizam.
Atividade
Se o nosso corpus fosse composto de dois documentos, um que diga: “Estou com fome” e outro que diga: “Estou com sono”, quais informações apareceriam na primeira linha do sumário? Complete:
Este corpus tem _ documentos com um total de palavras de _ e _ palavras únicas.
Extensão de documentos
A segunda coisa que veremos é a seção “extensão de documentos”. Aparecerá o seguinte:
-
Mais longo: 2008_cl_bachelet (20702); 2007_ar_kircher (20390); 2006_ar_kircher (18619); 2010_cl_pinera (16982); 2007_cl_bachelet (15514)
-
Mais curto: 2006_pe_toledo (1289); 2006_mx_fox (2450); 2008_mx_calderon (3317); 2006_co_uribe (4709); 2009_co_uribe (5807)
Atividade 2
-
O que podemos concluir sobre os textos mais longos e os mais curtos considerando os metadados no nome do arquivo (ano, país, presidente)?
-
Para que nos serve saber a extensão dos textos?
Densidade do vocabulário
A densidade do vocabulário é medida dividindo o número de palavras únicas pelo número de palavras totais. Quanto mais próximo o índice de densidade estiver de um, significa que o vocabulário tem maior variedade de palavras, ou seja, é mais denso.
Atividade 3
1) Calcule a densidade das seguintes estrofes, compare e comente:
- Estrofe 1. De “Homens tolos que você acusa por Sor Juana Inés de la Cruz
Que humor pode ser mais raro do que aquele que, sem conselhos, mancha o próprio espelho, e sente que não está claro?
- Estrofe 2. De “Despacito” de Erika Ender, Luis Fonsi e Daddy Yankee
Passo a passo, de mansinho, de mansinho, vamos grudando aos poucos. Quando você me beija com aquela habilidade eu vejo que você é malícia com delicadeza.
2) Leia os dados de densidade léxica dos documentos do nosso corpus, o que eles lhe dizem?
-
Maior: 2006_pe_toledo (0,404); 2006_co_uribe (0,340); 2009_co_uribe (0,336); 2008_co_uribe (0,334); 2006_mx_fox (0,328)
-
Menor: 2008_cl_bachelet (0,192); 2007_mx_calderon (0.192); 2007_ar_kircher (0,206); 2007_pe_garcia (0,214); 2010_ar_fernandez (0.217)
3) Compare-os com as informações sobre sua extensão, o que você percebe?
Palavras por frase
A forma como o Voyant calcula o comprimento da sentença deve ser considerada muito aproximada, especialmente por causa da dificuldade de distinguir entre o fim de uma abreviação e a de uma frase ou outros usos de pontuação. Por exemplo, em alguns casos um ponto e vírgula marca o limite entre as frases. A análise das frases é realizada por um modelo com instruções ou “classe” da linguagem de programação Java que é chamada BreakIterator.
Atividade 4
1) Olhe para as estatísticas de palavra por frase (ppo) e responda: que padrão ou padrões você pode observar se considerar o índice “ppo” e os metadados do país, presidente e ano contidos no nome do documento?
2) Clique nos nomes de alguns documentos que lhe interessam pelo seu índice de “ppo”. Olhe para a janela “Leitor” e leia algumas linhas. A leitura do texto original adiciona novas informações à sua leitura dos dados? Comente o porquê.
Cirrus e Sumário: frequências e filtros de palavras vazias
Agora que temos uma ideia de algumas características globais de nossos documentos, é hora de começarmos com as características dos termos em nosso corpus. Um dos pontos de entrada mais comuns é entender o que significa analisar um texto a partir de suas frequências.
Frequências sem filtro
O primeiro aspecto que vamos trabalhar é com a frequência bruta e, para isso, usaremos a janela Cirrus.
Atividade 5
1) Quais palavras são as mais frequentes no corpus?
2) O que essas palavras do corpus nos dizem? Todas elas são significativas?
Dica: passe o mouse sobre as palavras para obter suas frequências precisas.
Palavras vazias
O importante não é o valor intrínseco, sempre dependerá de nossos interesses. É exatamente por isso que Voyant oferece a opção de filtrar certas palavras. Um procedimento comum para a obtenção de palavras relevantes é filtrar unidades lexicais gramaticais ou palavras vazias: artigos, preposições, interjeições, pronomes, etc. (Peña e Peña, 2015).
Atividade 6
1) Que palavras vazias estão na nuvem de palavras?
2) Quais você removeria e por quê?
O Voyant já tem carregado uma lista stopwords ou palavras vazias do português. Podemos editá-la da seguinte forma: 1) Colocamos nosso cursor no canto superior direito da janela Cirrus e clicamos no ícone que parece um interruptor.

Abrir opções
2) Uma janela aparecerá com diferentes opções, selecionamos a primeira “Editar lista”

Lista de edição
3) Adicionamos as palavras “vazias”, sempre separadas por uma quebra de linha (tecla enter)

Remover palavras vazias
4) Uma vez que adicionamos as palavras que queremos filtrar, clicamos em “salvar” (sic).
Atenção: por padrão, uma caixa que diz ‘Aplicar a todos’ está selecionada; se isso for deixado selecionado, a filtragem de palavras afetará as métricas de todas as outras ferramentas. É muito importante que você documente suas decisões. Uma boa prática é salvar a lista de palavras vazias em um arquivo de texto (.txt) Para este tutorial criamos uma lista de palavras para filtrar e você pode usá-la se quiser, basta lembrar que isso afetará seus resultados. Por exemplo: na lista de palavras filtradas que incluí ‘todas’ e ‘todos’, haverá pessoas para quem essas palavras podem ser interessantes, pois mostram que ‘todos’ é muito mais usado do que ‘todas’ e isso pode nos dar pistas sobre o uso da linguagem inclusiva.
Frequências com palavras vazias filtradas
Voltemos então a esta seção do sumário. Como dissemos na abertura anterior, as palavras filtradas afetam outros campos do Voyant. Neste caso, se você deixou a caixa “Aplicar a todos” selecionada, na lista que aparece abaixo da legenda: Palavra mais frequente no corpus, as palavras que mais se repetem serão exibidas sem contar as que foram filtradas. No meu caso, mostra:
social (437); nacional (427); nosso (393); investimento (376); lei (369)
Atividade 7
-
Reflita sobre essas palavras e pense sobre quais informações elas lhe dão e como essas informações são diferentes daquelas que você obtém ao olhar para a nuvem de palavras.
-
Se você está em um grupo discuta as diferenças entre seus resultados e os dos outros.
Termos
Embora as frequências possam nos dizer algo sobre nossos textos, existem muitas variáveis que podem fazer com que estes números sejam pouco significativos. As seções a seguir explicarão diferentes estatísticas que podem ser obtidas na guia “Termos” que fica à esquerda do botão “Cirrus” no layout padrão do Voyant.
Frequência normalizada
Na seção anterior observamos a “frequência bruta” das palavras. No entanto, se tivéssemos um corpus de seis palavras e um corpus de 3.000 palavras, as frequências brutas são pouco informativas. Três palavras em um corpus de seis palavras representam 50% do total. Três palavras em um corpus de 6.000 representam 0,1% do total. Para evitar a sub-representação de um termo, os linguistas criaram outra medida chamada: “frequência relativa normalizada”. Isso é calculado da seguinte forma: Frequência Bruta * 1.000.000 / Número total de palavras. Vamos olhar para um verso como um exemplo. Tomemos a frase, “mas meu coração diz não, diz não”, que tem oito palavras no total. Se calcularmos sua frequência bruta e relativa, temos que:
**Palavra Frequência bruta Frequência normalizada** coração 1 1*1.000.000/8 = 125.000 diz dois 2*1.000.000/8 = 111.000
Qual é a vantagem disso? Que se tivéssemos um corpus em que a palavra coração tivesse a mesma proporção, por exemplo, 1.000 ocorrências entre 8.000 palavras; embora a frequência bruta seja muito diferente, a frequência normalizada seria a mesma, pois 1.000 * 1.000.000/8.000 também é 125.000.
Vamos ver como isso funciona no Voyant Tools:
- Na seção Cirrus, clicamos em ‘Termos’. Isso abrirá uma tabela que por padrão tem três colunas: Termos (com a lista de palavras nos documentos, sem as filtradas), Contagem (com a ‘frequência bruta ou líquida’ de cada termo) e Tendência (com um gráfico da distribuição de uma palavra tomando sua frequência relativa). Para obter informações sobre a frequência relativa de um termo, na barra de nomes de coluna, à extrema direita, clique no triângulo que oferece mais opções e em ‘Colunas’ selecione a opção ‘Relativa’ como mostrado na imagem abaixo:

Frequência relativa
- Se você classificar as colunas em ordem descendente, como faria em um programa de planilha, notará que a ordem da frequência relativa (‘Relativa’) é a mesma. Para que serve essa medida então? Para quando comparamos diferentes corpus. Um corpus é um conjunto de textos com algo em comum. Neste caso, Voyant está interpretando todos os discursos como um único corpus. Se quiséssemos que cada país fosse um corpus diferente, teríamos que salvar nosso texto em uma tabela, em HTML ou em XML, onde os metadados fossem expressos em colunas (no caso da tabela) ou em tags (no caso de HTML ou XML).3
Assimetria estatística
Embora a frequência relativa não sirva para entender a distribuição do nosso corpus, existe uma medida que nos dá informações sobre o quão constante é um termo em nossos documentos: assimetria estatística.
Essa medida nos dá uma ideia da distribuição de probabilidade de uma variável sem ter que fazer sua representação gráfica. A forma como é calculada é observando os desvios de uma frequência em relação à média, para determinar se aqueles que ocorrem à direita da média (assimetria negativa) são maiores do que os da esquerda (assimetria positiva). Quanto mais perto de zero o grau de assimetria estatística, mais regular é a distribuição desse termo (ou seja, ocorre com uma média muito semelhante em todos os documentos). Algo que não é muito intuitivo é que se um termo tem uma assimetria estatística com números positivos significa que esse termo está abaixo da média, e quanto maior o número, mais assimétrico o termo é (ou seja, acontece muito em um documento, mas quase não ocorre no corpus). Números negativos,por outro lado, indicam que esse termo tende a estar acima da média.

Assimetria estatística
Para obter esta medida no Voyant, temos que repetir os passos que fizemos para obter a frequência relativa, mas desta vez selecionar Distorção (Skew). Essa medida permite observar, então, que a palavra “crisis” por exemplo, apesar de ter uma alta frequência, não só não tem uma frequência constante em todo o corpus, mas que tende a ficar abaixo da média porque sua assimetria estatística é positiva (1,9).
Palavras distintas
Como você já deve suspeitar, as informações mais interessantes geralmente não são encontradas dentro das palavras mais frequentes, pois estas tendem a ser as mais óbvias também. No campo da recuperação da informação, foram inventadas outras medidas que possibilitam localizar os termos que fazem um documento se destacar de outro. Uma das medidas mais utilizadas é chamada de tf-idf “(do inglês term frequency – inverse document frequency). Essa medida busca expressar numericamente a relevância de é um documento em uma determinada coleção; ou seja, em uma coleção de textos sobre “maçãs” a palavra maçã pode ocorrer muitas vezes, mas elas não nos dizem nada de novo sobre a coleção, por isso não queremos saber a frequência bruta das palavras term frequency, frequência do termo), mas medir o quão única ou comum ela é na determinada coleção (inverse document frequency, frequência inversa do documento).
No Voyant o tf-idf é calculado da seguinte forma:
Frequência Bruta (tf) / Número de Palavras (N) * log10 ( Número de Documentos / Número de vezes que o termo aparece nos documentos)

Fórmula TF-IDF
Atividade 8
Observe as palavras distintas (em comparação com o resto do corpus) em cada um dos documentos e note quais hipóteses você pode derivar delas
- 2006_ar_kircher: uruguai (12), 2004 (13), 2005 (31), prata (7), inclusão (16).
- 2006_cl_bachelet: inovação (15), rodrigo (8), alegremente (4), barrios (9), cobre (10).
- 2006_co_uribe: tutela (5), reeleição (6), royalties (7), iva (6), publicação (5).
- 2006_mx_fox: atenção (5), apego (5), federalismo (3), intransigência (2), fundação (3).
- 2006_pe_toledo: rendição (5), senhor (14), senhora (5), amiga (5), tracemos (2).
- 2007_ar_kircher: 2006 (65), Mercosul (12), Uruguai (9), províncias (16), ano a ano (5).
- 2007_cl_bachelet: macrozona (7), devedores (12), berço (9), subsídio (10), pessimismo (4).
- 2007_co_uribe: guerrilheiros (10), sindicalistas (7), paramilitares (8), investidores (10) e punts (7).
- 2007_mx_calderon: equalizar (9), transformar (19), tortilla (4), aquíferos (4), miséria (10).
- 2007_pe_garcia: huancavelica (9), redistribuição (10), callao (8), 407 (4), lima (7).
- 2008_ar_fernandez: endereçamento (17), capítulo (12), pressupostos (5), lesa (8), articular (5).
- 2008_cl_bachelet: desafio (18), look (10), pass (6), adulto (6), dez (11).
- 2008_co_uribe: ecopetrol (6), reavaliação (4), jogos (4), depreciação (3), bilhões (6).
- 2008_mx_calderon: cartel (5), noites (3), mexicano (6), controlado (3), federal (6).
- 2008_pe_garcia: vilas (11), quilômetros (52), lima (11), estradas (21), mineiros (4).
- 2009_ar_fernandez: segurando (7), liderança (5), coparticipação (6), catamarca (7), pbi (9).
- 2009_cl_bachelet: selo (5), fortalecido (5), crise (48), pessoas (24), aplausos (4).
- 2009_co_uribe: colômbia (20), estrada (6), contribuinte (5), deslocada (6), notificada (3).
- 2009_mx_calderon: federal (27), organizado (10), mudança (13), proponho (8), polícia (4).
- 2009_pe_garcia: cal (11), 1.500 (6), tingo (4), pampas (4), desordem (6).
Palavras em contexto
O projeto com que algumas histórias inauguram as Humanidades Digitais é o Index Thomisticus, uma concordância da obra de Tomás de Aquino liderado pelo filólogo e religioso Roberto Busa (Hóquei, 2004), no qual dezenas de mulheres participaram da codificação (Terras, 2013). Este projeto, que levou anos para ser concluído, é um recurso interno do Voyant Tools no canto inferior direito, na janela “Contextos”, é possível consultar as concordâncias esquerdas e direitas de termos específicos.
A tabela que vemos tem as seguintes colunas padrão:
- Documento: Aqui está o nome do documento em que ocorre a palavra-chave de consulta
- Esquerda: contexto esquerdo da palavra-chave (este pode ser modificado para cobrir mais ou menos palavras e se você clicar na célula, esta se expande para mostrar mais contexto)
- Termos: palavras-chave de consulta
- Direito: contexto direito
Você pode adicionar a coluna Posição que indica o lugar no documento onde o termo consultado se encontra:

Adicionar coluna de posição
Consulta avançada Voyant permite o uso de curingas para procurar variações de uma palavra. Aqui estão algumas das combinações
- famili*: esta consulta retornará todas as palavras que começam com o prefixo “famili” “(familias, familiares, familiar, familia)
- **ción : termos que terminam com o sufixo “ción” (poluição, militarização, fabricação)
- pobreza, desigualdade: você pode procurar mais de um termo separando-os por vírgulas
- “anti-pobreza“:encontre a frase exata
- “pobreza extrema”~ 5: Busque os termos dentro das aspas, a ordem não importa, e pode haver até 5 palavras no meio (essa condição retornaria frases como “desigualdade extrema e pobreza” onde a palavra “pobreza” e “extrema” são encontradas.
Actividad 9
- Pesquise o uso de um termo que você acha interessante, use algumas das estratégias da consulta avançada.
- Classifique as linhas usando as diferentes colunas (Documento, Esquerda, Direita e Posição). Que conclusões você pode tirar sobre seus termos usando as informações dessas colunas?
Atenção: a ordem das palavras na coluna “Esquerda” está invertida; ou seja, da direita para a esquerda a partir da palavra-chave.
Exportando as tabelas
Para exportar os dados, clique na caixa com seta que aparece quando você passa o mouse sobre o canto direito de “Contextos”. Em seguida, selecione a opção “Exportar dados atuais” e clique na última opção: Export all available data as tab separated values (text)grid.
Isso leva a uma página onde os campos são separados por uma tabulação:

Exportar contextos
Selecione todos os dados (Ctrl+A ou Ctrl+E); copie (Ctrl+C) e cole em uma planilha (Ctrl+V). Se isso não funcionar, salve os dados em editor de texto simples como .txt (não se esqueça da codificação utf-8!). Em seguida importe os dados em sua planilha. No Excel isso é feito na guia “Dados” e, em seguida, “De texto” ou “Obter dados do Texto”, dependendo da versão do Excel.

Importar dados de um arquivo de texto
Respostas às atividades
Atividade 1
Este corpus tem 2 documentos com um total de 4 palavras e 3 palavras únicas (tenho, fome, sono)
Atividade 2
1) Podemos observar, por exemplo, que os textos mais longos são de dois países: Chile e Argentina, e de três presidentes diferentes: Kirchner, Bachelet e Pinera. Nos mais curtos, vemos que, embora o mais curto seja do Peru, na realidade os que mais aparecem entre os curtos são os do México e da Colômbia.
2) Conhecer a extensão de nossos textos nos permite compreender a homogeneidade ou disparidade do nosso corpus, bem como compreender certas tendências (por exemplo, em que anos os discursos tendiam a ser mais curtos, quando o comprimento mudava).
Atividade 3
1) A primeira estrofe tem 23 palavras e 20 são palavras únicas, então 20/23 equivale a uma densidade de vocabulário de 0,870; na verdade, 0,869, mas o Voyant Tools arredonda esses números:
https://voyant-tools.org/?corpus=b6b17408eb605cb1477756ce412de78e.
A segunda estrofe tem 24 palavras e 20 são palavras simples, então 20/24 equivale a uma densidade de vocabulário de 0,833:
https://voyant-tools.org/?corpus=366630ce91f54ed3577a0873d601d714.
Como podemos observar, a diferença entre um verso de Sor Juana Inés de la Cruz e outro composto por Érika Ender, Daddy Yankee e Luis Fonsi têm uma diferença de densidade de 0,037, o que não é muito alto. Devemos ter cuidado ao interpretar esses números porque eles são apenas um indicador quantitativo da riqueza do vocabulário e não incluem parâmetros como a complexidade da rima ou os termos.
Parece haver uma semelhança entre os discursos mais curtos e mais longos, isso é natural porque quanto mais curto for um texto, menos “oportunidade” há de se repetir. No entanto, isso também poderia nos dizer algo sobre os estilos de diferentes países ou presidentes. Quanto menos densidade eles são mais propensos a recorrer a recursos retóricos.
Atividade 4
Esses resultados parecem indicar que a presidente Kirchner, além de ter os discursos mais longos, é quem faz as frases mais longas; no entanto, temos que ter cuidado com conclusões desse tipo, pois se tratam de discursos orais em que a pontuação depende de quem transcreve o texto.
Atividade 5
-
a (5943); mais (1946); não (1694); mil (1045); milhões (971)
-
A primeira palavra é uma preposição, a segunda um advérbio de comparação e a terceira um advérbio de negação. Estas palavras podem ser significativas se você estiver procurando entender o uso dos tipos de palavras funcionais. No entanto, se o que você está procurando são substantivos, você terá que fazer uma filtragem (ver seção: “Palavras mais frequentes”)
Bibliografia
Hockey, Susan. 2004 “The History of Humanities Computing”. A Companion to Digital Humanities. Schreibman et al. (editores). Blackwell Publishing Ltd. doi:10.1002/9780470999875.ch1.
Peña, Gilberto Anguiano, y Catalina Naumis Peña. 2015. «Extracción de candidatos a términos de un corpus de la lengua general». Investigación Bibliotecológica: Archivonomía, Bibliotecología e Información 29 (67): 19-45. https://doi.org/10.1016/j.ibbai.2016.02.035.
Sinclair, Stéfan and Geoffrey Rockwell, 2016. Voyant Tools. Web. http://voyant-tools.org/.
Terras, Melissa, 2013. “For Ada Lovelace Day – Father Busa’s Female Punch Card Operatives”. Melissa Terras’ Blog. Web. http://melissaterras.blogspot.com/2013/10/for-ada-lovelace-day-father-busas.html.
Este tutorial foi escrito graças ao apoio da Academia Britânica e preparado durante a Oficina de Escrita de Historiadores de Programação na Universidad de los Andes em Bogotá, Colômbia, de 31 de julho a 3 de agosto de 2018.
Notas de Rodapé
[^1] Os textos do Peru foram compilados por Pamela Sertzen
[^2] Existem maneiras mais complexas de carregar o corpus que você pode consultar na documentação em inglês.
[^3] Para obter mais informações, consulte a documentação em inglês. ↩