This is the draft website for Programming Historian lessons under review. Do not link to these pages.
For the published site, go to https://programminghistorian.org
Contents
- Requisitos
- Objetivos da lição
- Folha de registo
- Gráficos de barras
- Gráficos de caixa
- Mais operações sobre folhas de registo
- Valores que faltam
- Observações finais
- Notas de fim
Requisitos
Nesta lição consideramos que o leitor já possui algum conhecimento da linguagem R. Se ainda não completou a lição Noções básicas de R com dados tabulares, recomendamos que o faça primeiro.
Objetivos da lição
Esta lição visa apresentar a forma como dados tabulares podem ser visualizados em R, explicando o conceito de folha de registo (dataframe) e os tipos de visualização que podem ser obtidos a partir delas.
Folha de registo
Quem não teve, ao longo da sua vida, de preencher uma folha de registo numa aula, ou para entrar num edifício, com o seu nome, telefone e correio eletrónico, e às vezes com a assinatura, e/ou com outras informações (data de entrada, hora de entrada, hora de saída, etc)?
Se generalizarmos este conceito, vemos que para cada ocorrência (neste caso, pessoa que entra no edifício) preenche-se um conjunto de informações de vários tipos, e cada coluna tem o mesmo tipo de informação (nome, número de telefone, data…)
Esta estrutura de dados (se usarmos agora o vocabulário de uma linguagem de programação) é muito útil para juntar vários tipos de informação sobre uma mesma entidade (linha), e em R chama-se dataframe, que traduzimos aqui por folha de registo.
Uma folha de registo é pois representada por uma tabela, que em cada uma das suas colunas tem o mesmo tipo de dados, mas que pode ter colunas diferentes com informação diferente.
Existem muitos dados em R que são organizados em folhas de registo, e existem várias funções que se aplicam a folhas de registo para fácil manipulação.
Criação de raiz
Para efeitos pedagógicos, vamos criar algumas folhas de registo de raiz, mas devo desde já notar que na esmagadora maioria dos casos esses dados vêm de fora, e são lidos para o R através das suas funções de entrada/saída, em particular read.table(), de que falaremos mais tarde.
escritores <- data.frame(id=c("JulDin","CamCBra","AacAss","CoeNet"), nome=c("Júlio Dinis", "Camilo Castelo Branco","Machado de Assis","Coelho Neto"),nascimento=c(1839,1825,1839,1864), morte=c(1871,1890,1908,1934),nacionalidade=c("PT","PT","BR","BR"))
O comando data.frame() cria uma folha de registo, c() – concatenar – cria um vetor com os argumentos.
É depois possível identificar cada coluna pelo nome, por exemplo a coluna que indica a data de nascimento é identificada assim: escritores$nascimento
Assim como é possível ter um resumo da folha de registo
summary(escritores)

Figura 1. O resultado do comando summary
Adição de colunas
Para juntar mais colunas, basta dar-lhe um novo nome, e dizer como os valores são calculados. No primeiro exemplo, calculamos quanto tempo um dado autor viveu:
escritores$tempoVida<-escritores$morte-escritores$nascimento
No segundo exemplo, juntamos o sexo do autor, que nesse caso é sempre masculino, e que escolhemos marcar como “masc”.
escritores$sexo<-"masc"
Embora apenas indiquemos um valor (e não um vetor) o R automaticamente repete esse valor tantas vezes quantas a dimensão da coluna.
Adição de linhas
Também se podem juntar mais linhas (usando a função rbind(), que significa “row bind” (ligar linhas), e que recebe como argumentos uma folha de registo e novas linhas, ou duas folhas de registo), mas nesse caso temos de dar um valor a cada coluna. Se usássemos a função c() (concatenar), todos os valores seriam considerados cadeias de carateres…
escritores<-rbind(escritores, c("JorAma","Jorge Amado",1912,2001,"BR",89,"masc"))
Por isso o melhor é criar uma nova folha de registo para o novo autor e adicioná-la:
escritores<-rbind(escritores, data.frame(id="JorAma",nome="Jorge Amado",nascimento=1912,morte=2001,nacionalidade="BR",tempoVida=89,sexo="masc"))
Leitura de fora do R
Mas, como já dito, a maneira mais natural é ler folhas de registo de fora do R. E nesse caso vêm em geral de planilhas ou folhas de cálculo, e é possível indicar, ao ler, várias questões:
- em primeiro lugar, se as colunas têm nome (se tiverem, lemos com a indicação
header=TRUE - em segundo lugar, qual é o separador (por exemplo,
sep="\t"se as várias colunas estiverem separadas por tabuladores,sep=","se estiverem separadas por vírgulas) - para casos de números com casas decimais, qual o separador (
dec=","oudec=".") - se houver uma coluna que apenas contenha identificadores (todos diferentes, portanto), podemos também indicar isso com
rownames=4, em que o algarismo indica o número da coluna
Por exemplo,
maisescritores<-read.table("fich41.tsv",header=TRUE,sep="\t")
leria o que estivesse no ficheiro fich41.tsv, usando a primeira linha como o nome das colunas, e usando os tabuladores a separar as colunas.
Processamento de colunas de uma folha de registo
Muitas vezes o que escrevemos na tabela é para ser um código de um conjunto fixo de etiquetas, e não uma cadeira de carateres em português… nesse caso, devemos indicar ao R que aquilo é um factor (um termo do R que designa uma variável categórica em estatística) e não uma palavra.
No caso da nossa folhinha de registo, BR e PT significam autor brasileiro e português respetivamente, e queremos considerá-los um fator. Idem para o sexo
escritores$nacionalidade<-factor(escritores$nacionalidade)
escritores$sexo<-factor(escritores$sexo)
escritores$id<-factor(escritores$id)
Reparem como o summary se torna muito mais legível:
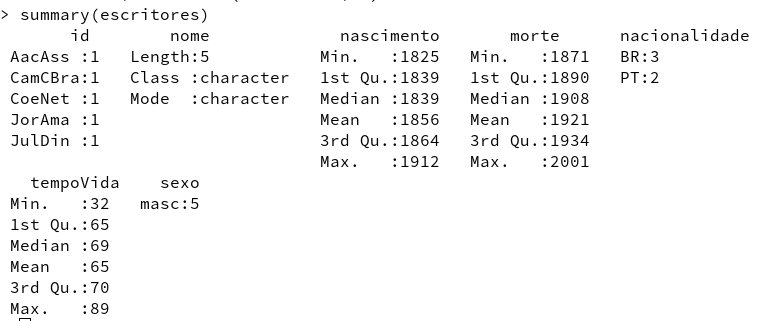
Figura 2. O novo resultado de summary
Podemos, claro, adicionar mais valores ao fator
escritores$nacionalidade<-factor(escritores$nacionalidade,levels=c("PT","BR","AN"))
E agora podemos adicionar escritores angolanos
escritores<-rbind(escritores, data.frame(id="AgoNet",nome="Agostinho Neto",nascimento=1922,morte=1979,nacionalidade="AN",tempoVida=57,sexo="masc"))
Tipos de colunas
Além de simples palavras ou texto, uma coluna pode ter valores de um grupo (fatores), valores lógicos (TRUE e FALSE) e valores numéricos, estes de dois tipos:
- números inteiros, geralmente correspondentes a contagens
- números reais, geralmente correspondentes a medições
É para valores numéricos que a visualização é principalmente expressiva, mas os fatores são uma forma útil de organização.
Gráficos de barras
Estes gráficos representam contagens de um certo número de características. Com a folhinha de registo que temos, a única contagem que faz sentido é a da nacionalidade. O primeiro comando tabula quantos casos temos por cada nacionalidade, e o segundo faz um gráfico de barras.
table(escritores$nacionalidade)
barplot(table(escritores$nacionalidade))
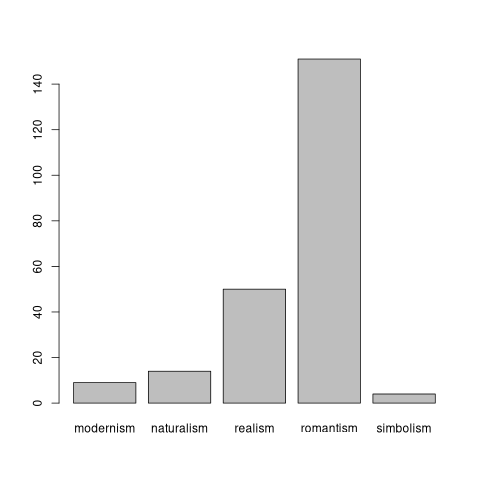
Figura 0X1. Gráfico de barras com nacionalidade do autor
Mas vamos buscar folhas de registo muito mais ricas para demonstrar as potencialidades de visualização. Por exemplo, vejamos uma lista de obras literárias em português com informação sobre o seu autor, data de publicação, escola literária e contagens de vários atributos sintáticos e semânticos, usada no artigo Santos et al. (2020) 1.
periodizacao<-read.table("https://www.linguateca.pt/Diana/UnivOslo/cursoR/dadosPeriodLit.tsv",header=TRUE)
O primeiro argumento do comando read.table() indica onde se encontra o ficheiro que se pretende ler. Pode ser localmente dadosPeriodLit.tsv, ou através de um URL.2
Através do comando names() podemos ver quais os nomes das colunas, e através de str() ou summary() podemos ver o tipo de informação que cada coluna tem.
names(periodizacao)
str(periodizacao)
summary(periodizacao)
Por agora, basta caracterizar o autor, o sexo, o género literário e a escola literária como fatores. escola2inclui uma versão mais simplificada da escola literária, com os nomes em inglês.
periodizacao$autor<-factor(periodizacao$autor)
periodizacao$sexo<-factor(periodizacao$sexo)
periodizacao$genero<-factor(periodizacao$genero)
periodizacao$escola<-factor(periodizacao$escola)
Podemos assim identificar as escolas (literárias) presentes no material (removemos da figura os casos em que a escola é desconhecida, marcados como desc):
periodSemDesc<-subset(periodizacao, escola2!="desc")
periodSemDesc$escola2<-factor(periodSemDesc$escola2)
barplot(table(periodSemDesc$escola2))
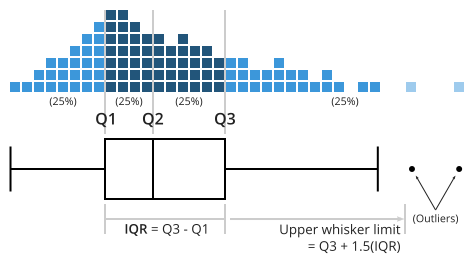
Figura 4. Gráfico de barras com escola literária em inglês
Criamos uma nova folha de registo periodSemDesc a partir da folha de registo original, com apenas os casos em que se conhece a escola literária. A indicação escola2!="desc" significa que o valor da coluna escola2 deve ser diferente de desc. Se, pelo contrário, quiséssemos igual, usaríamos o sinal == em vez de !=.
Se tivéssemos executado simplesmente os comandos
periodizacao$escola2<-factor(periodizacao$escola2)
barplot(table(periodizacao[periodizacao$escola2!="desc",]$escola2))
o gráfico de barras apresentaria uma barra nula para desc, como vemos na figura 0X2:
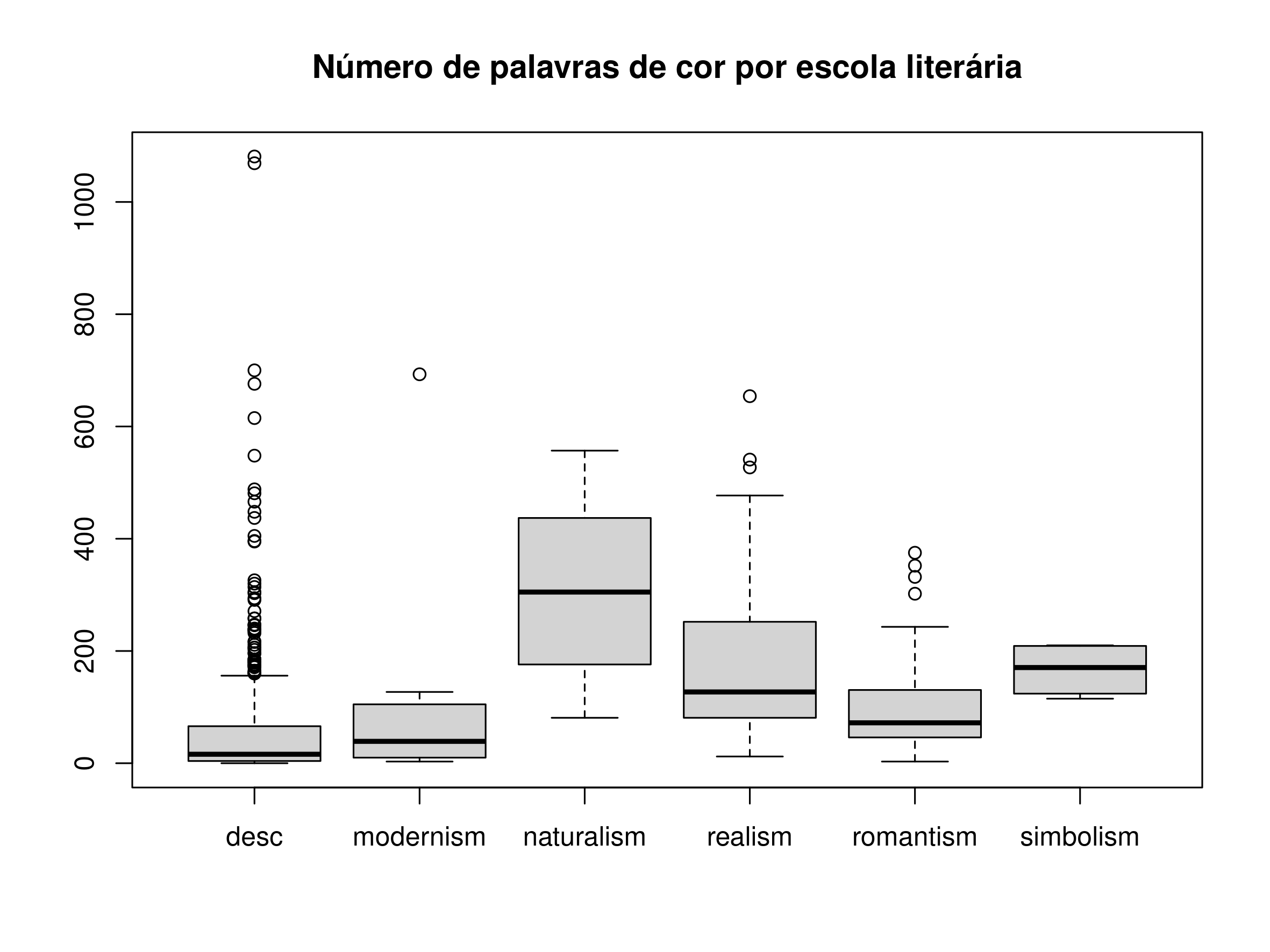
Figura 5. Gráfico de barras com escola literária em inglês, sem termos removido o valor desc do fator escola
A indicação periodizacao[periodizacao$escola2!="desc",] significa todas as linhas da folha de registo periodizacao cuja coluna escola2 não tenha o valor desc, e todas as colunas. (Uma folha de registo tem sempre linhas e colunas, e podemos selecioná-las independentemente. Quando não pomos nada, como depois da vírgula, significa que selecionamos todas.)
Gráficos de caixa
Os gráficos de caixa representam um conjunto de números, mostrando a sua mediana, e a forma como estão distribuídos. A caixa propriamente dita representa 50% dos dados: a linha abaixo representa o valor dos 25% e a de cima o de 75%, chamados primeiro quartil e terceiro quartil. A diferença entre Q3 e Q1 chama-se a diferença entre quartis (interquartile range em inglês, geralmente abreviado por IQR). Os traços horizontais, também chamados bigodes (whiskers) são calculados da seguinte maneira:
- Bigode inferior: é o máximo de valor mínimo e de Q1-1.5*IQR
- Bigode superior: é o mínimo do valor máximo e de Q3+1.5*IQR
Quando há casos fora desses limites descritos pelos bigodes, chamados valores discrepantes (outliers, em inglês), são marcados como pontos discretos.
Veja-se esta figura, retirada do tutorial de Yi3 A complete guide to boxplots:
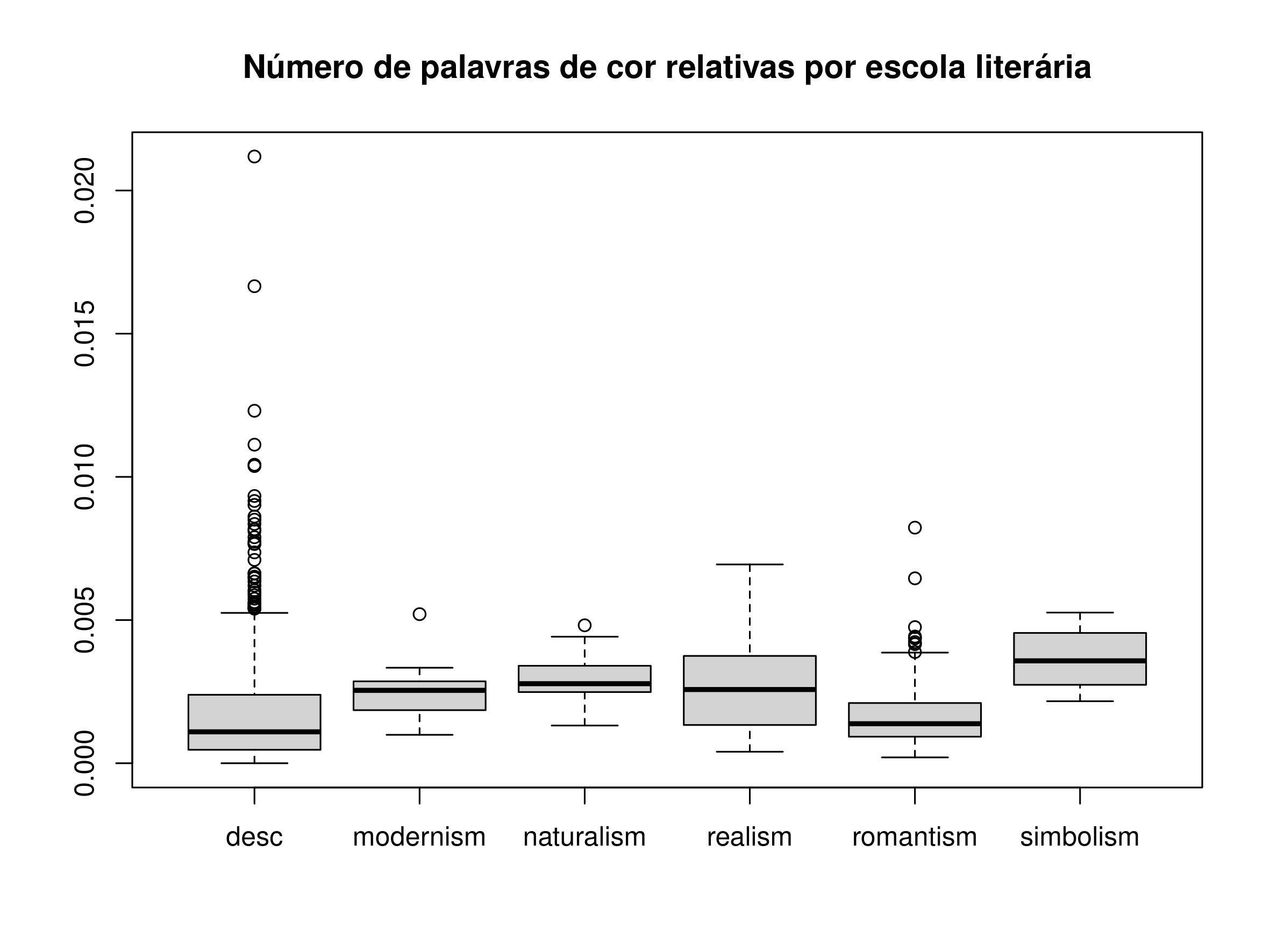
Figura 6. Explicação de um gráfico de caixa, retirada de Yi.
Os gráficos de caixa são sobretudo úteis para comparar vários conjuntos de dados. Vejamos, no nosso caso, a diferença de uso de cor por escola literária:
boxplot(periodizacao$cor~periodizacao$escola2)
O til (~) é como se designa por em R, e espera que a indicação à direita seja um fator. À esquerda teremos valores numéricos para fazer os variados gráficos de caixa, um por cada valor do fator.
Figura 7. Gráfico de caixa da presença de palavras de cor por escola literária em inglês
Vemos pelo resultado que é o naturalismo que tem mais cor, e que o romantismo parece ter menos palavras de cor que o realismo. Não nos interessa aqui prosseguir nenhuma análise literária, mas apenas ilustrar o uso dos gráficos de caixa e a sua interpretação.
De facto, para poder comparar como deve ser um grande conjunto de obras de tamanho variável, deveríamos ter calculado a percentagem de palavras de cor e não o número de palavras de cor.
boxplot(periodizacao$cor/periodizacao$tamanho~periodizacao$escola2)
Figura 8. Gráfico de caixa da presença relativa de palavras de cor por escola literária em inglês
Mais operações sobre folhas de registo
Obter subconjuntos
Vejamos agora mais potencialidades do uso e criação de folhas de registo, através da função subset(), que permite escolher um subconjunto de colunas e de linhas e criar uma nova folha de registo, à qual aplicaremos mais visualizações:
algunsAutores<-subset(periodizacao,(autor=="JulDin" | autor=="EcaQue" | autor=="MacAss"|autor=="CoeNet") & genero=="Prosa:romance",c(1:147))
Como só temos quatro autores, faz sentido dizer que os outros valores do fator devem ser ignorados, o que se faz com o seguinte comando:
algunsAutores$autor<-algunsAutores$autor[drop=TRUE]
Podemos ver quantas obras temos por autor:
barplot(table(algunsAutores$autor))
Figura 09. Gráfico de barras do número de obras por autor
Mas o mais interessante será comparar estes quatro autores, por exemplo na frequência relativa de emoções, no uso de nomes próprios, ou na frequência de orações no conjuntivo/subjuntivo:
boxplot(algunsAutores$emocoes/algunsAutores$tamanho~algunsAutores$autor,xlab="",ylab="", main="Frequência relativa de uso de palavras de emoção em romances por autor")
boxplot(algunsAutores$proprios/algunsAutores$tamanho~algunsAutores$autor,xlab="",ylab="", main="Frequência relativa de uso de nomes próprios em romances por autor")
boxplot(algunsAutores$conjuntivo/algunsAutores$oracoes~algunsAutores$autor,xlab="",ylab="", main="Frequência de orações no conjuntivo em romances por autor")
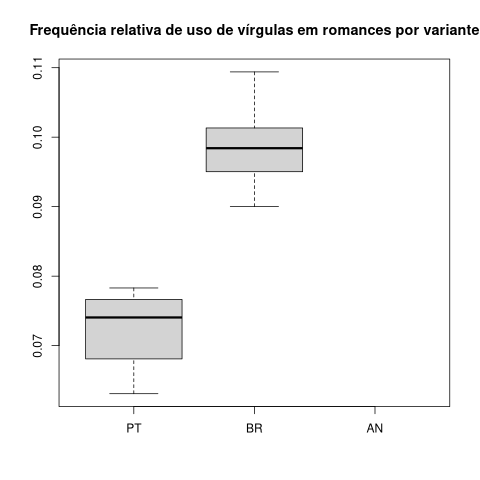
Figura 10. Gráfico de caixa da presença relativa de palavras de emoção por escola literária em inglês
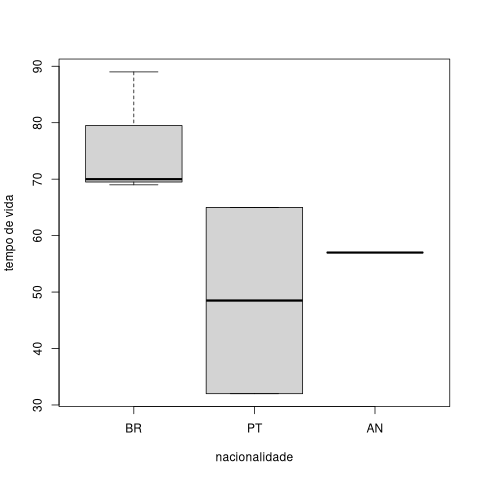
Figura 11. Gráfico de caixa da presença relativa de nomes próprios por escola literária em inglês
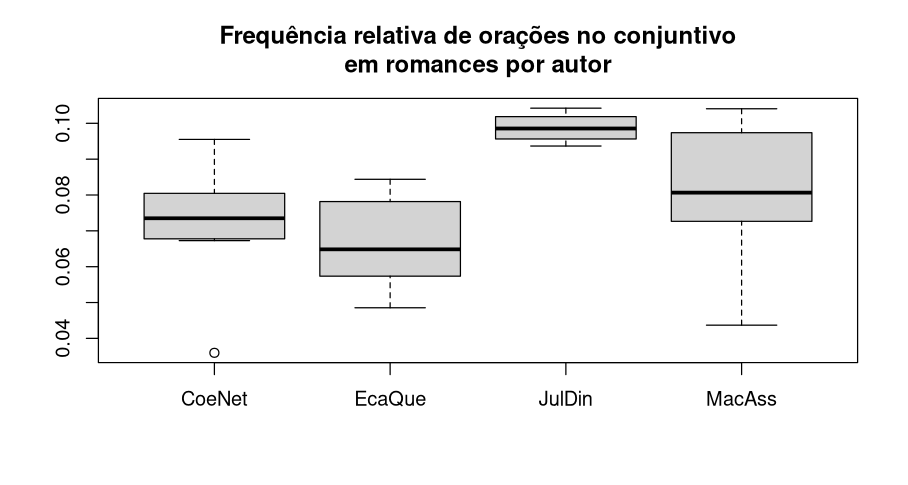
Figura 12. Gráfico de caixa da presença relativa de orações no conjuntivo por escola literária em inglês
Juntar mais do que uma folha de registo numa só
Finalmente, para mostrar ainda mais potencialidades do uso das folhas de registo, e da forma como a informação pode ser bem distribuída em folhas de registo diferentes, vamos criar uma nova folha de registo que contenha toda a informação contida em duas folhas de registo que já usámos: a algunsAutores e a escritores. A ideia é obter para cada obra, além do nome do autor, nova informação que temos sobre o autor, basicamente a variante, o tempo de vida e o sexo. Para isso usamos o comando merge().
maisInfo<-merge(algunsAutores,escritores,by.x=c("autor", "sexo"),by.y=c("id","sexo"))
Esse comando é muito importante – correspondente ao “join” das bases de dados – porque permite estruturar o conhecimento em ficheiros – tabelas – diferentes, mas juntá-lo quando queremos usar toda a informação. Na figura 0X4 vemos as primeira linhas da folha de registo maisInfo.

Figura 13. O que o R mostra se pedirmos as primeiras linhas da folha de registo MaisInfo
O uso deste comando permite-nos, por exemplo, fazer um diagrama de caixa pela variedade do português, e não pelos autores. Escolhi observar o uso das vírgulas na Figura 10.
boxplot(maisInfo$virg/maisInfo$tamanho~maisInfo$nacionalidade,xlab="",ylab="", main="Frequência relativa de uso de vírgulas em romances por variante")
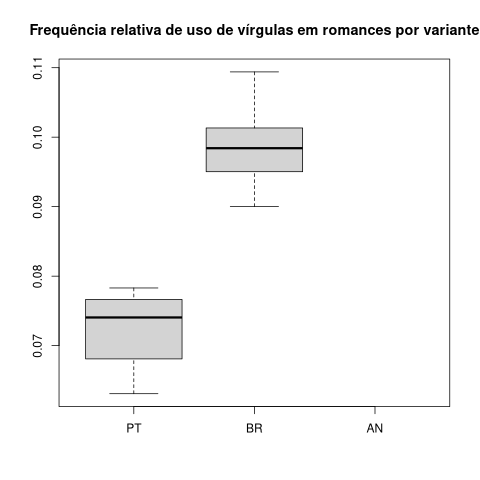
Figura 14. Gráfico de caixa da presença relativa de vírgulas por variante
Guardar folhas de registo
Finalmente, assim como é possível ler folhas de registo de fora do R, também é possível guardá-las fora do R, para serem usadas por outros programas, ou para quando voltarmos ao R. Para isso o comando mais usual é o write.table().
Vamos guardar a folha de registo maisInfo num ficheiro chamado obras4autoresComInfoAutor.txt (mais propriamente, deveria ser chamado .tsv, visto que o separador vai ser um tabulador (indicado por sep="\t", mas a extensão .txt permite ler diretamente num navegador (browser).)
write.table(maisInfo,"obras4autoresComInfoAutor.txt", sep="\t", quote=FALSE)
quote=FALSE indica que os valores não serão envolvidos em aspas, o que seria o caso se fosse TRUE.
Valores que faltam
Uma questão real de observações empíricas é que pode haver valores a que não temos acesso. E folhas de registo com grandes quantidades de dados invariavelmente sofrem desse problema.
Por outro lado, pode haver razões para não haver dados em algumas colunas mesmo em questões triviais: no exemplo que temos vindo a esmiuçar, como preencher a data da morte de um autor ainda vivo?
O R tem o conceito de valor NA (not available, inexistente), e praticamente todas as funções do R têm um comportamento apropriado para esses valores. Além disso, é possível testar e identificar os casos que faltam, através das funções is.na() ou na.exclude().
No caso dos diagramas apresentados na presente lição, simplesmente esses casos são excluídos da visualização, como podemos ver adicionando um autor ainda vivo e pedindo um diagrama de caixa do tempo de vida:
escritores<-rbind(escritores, data.frame(id="Pepet",nome="Pepetela",nascimento=1941,morte=NA,nacionalidade="AN",tempoVida=NA,sexo="masc"))
boxplot(escritores$tempoVida~escritores$nacionalidade)
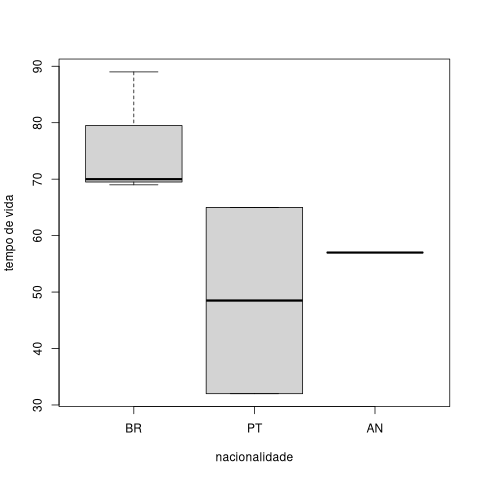
Figura 15. Gráfico de caixa do tempo de vida de alguns escritores por nacionalidade
Como só existe um autor angolano com tempo de vida diferente de NA, Agostinho Neto, apenas um ponto – visualizado como uma linha – é mostrado no gráfico de caixa.4
Observações finais
Nesta lição tentei explicar o conceito e as funcionalidades de uma folha de registo, e algumas formas simples de visualizar o seu conteúdo, usando gráficos de barras e gráficos de caixa.
Agora pode seguir para lições mais complicadas como Investigar a literatura lusófona através dos tempos usando a Literateca, em que as folhas de registo vêm do projeto AC/DC.
Notas de fim
-
Santos, Diana, Emanoel Pires, João Marques Lopes, Rebeca Schumacher Fuão & Cláudia Freitas. “Periodização automática: Estudos linguístico-estatísticos de literatura lusófona”. Linguamática 12 (1), 2020, pp. 80-95. ↩
-
Em alguns navegadores esse comando pode produzir o seguinte erro:
Error in file(file, "rt") : cannot open the connection to ’https://www.linguateca.pt/...'Nesse caso, leia o ficheiro para o seu próprio computador fora do R, e faça apenasread.table("dadosPeriodLit.tsv", header=TRUE)↩ -
Yi, Mike. A complete guide to box plots. https://www.atlassian.com/data/charts/box-plot-complete-guide. Último acesso: 3 de maio de 2024 ↩
-
O comportamento pode variar em versões diferentes do R. Se obtiverem uma mensagem de erro do
boxplot, executem os seguintes comandos, que retiram explicitamente os NA, transformam em inteiros as idades, antes de invocar o comandoboxplot.novoEscritores<-na.omit(escritores) novoEscritores$tempoVida<-as.integer(novoEscritores$tempoVida) boxplot(novoEscritores$tempoVida~novoEscritores$nacionalidade)↩