This is the draft website for Programming Historian lessons under review. Do not link to these pages.
For the published site, go to https://programminghistorian.org
##
- Introduction
- Courte introduction à l’apprentissage machine
- Guide approfondi de la vision par ordinateur à l’aide de l’apprentissage profond
- Partie I : conclusion
- Annexe : Une expérience non scientifique pour évaluer l’apprentissage par transfert
- Notes
Introduction
Si la plupart des historiens s’accordent à dire que la représentation (moderne) est façonnée par les médias multimodaux — c’est-à-dire les médias, tels que la presse, la télévision ou l’internet, qui combinent plusieurs modes — les domaines des humanités numériques et de l’histoire numérique restent dominés par les médias textuels et la grande variété de méthodes disponibles pour leur analyse1. Les historiens modernes ont souvent été accusés de négliger les formes de représentation non textuelles, et les humanistes numériques, en particulier, se sont consacrés à l’exploration des sources textuelles. Beaucoup ont utilisé l’OCR (Optical Character Recognition), une technologie qui rend les textes numérisés lisibles par machine, ainsi que des techniques issues du domaine du traitement automatique du langage naturel (TAL), pour analyser le contenu et le contexte du langage dans des vastes documents. La combinaison de ces deux éléments a donné naissance à l’innovation méthodologique centrale du domaine de l’histoire numérique : la capacité de « lire à distance » de grands corpus et de découvrir des modèles à grande échelle2.
Au cours des dix dernières années, le domaine de la vision par ordinateur, qui cherche à obtenir une compréhension de haut niveau des images à l’aide de techniques informatiques, a connu une innovation rapide. Ainsi, les modèles de vision par ordinateur peuvent localiser et identifier des personnes, des animaux et des milliers d’objets inclus dans des images, ce avec une grande précision. Cette avancée technologique promet de faire pour la reconnaissance d’images ce que la combinaison des techniques OCR/NLP a fait pour les textes. En d’autres termes, la vision par ordinateur ouvre à l’analyse à grande échelle une partie des archives numériques qui est restée pratiquement inexplorée : les millions d’images contenues dans les livres, journaux, périodiques et documents historiques numérisés. Par conséquent, les historiens seront désormais en mesure d’explorer le « côté visuel du tournant numérique dans la recherche historique » 3.
Cette leçon en deux parties fournit des exemples de la manière dont les techniques de vision par ordinateur peuvent être appliquées pour analyser de nouvelle façon de grands corpus visuels historiques et comment construire des modèles de vision par ordinateur personnalisés. Outre l’identification du contenu des images et leur classification par catégorie - deux tâches axées sur les caractéristiques visuelles - les techniques de vision par ordinateur peuvent également être utilisées pour déterminer les (dis)similitudes stylistiques entre les images.
Il convient toutefois de noter que les techniques de vision par ordinateur posent aux historiens un ensemble de défis théoriques et méthodologiques. Tout d’abord, toute application des techniques de vision par ordinateur aux corpus historiques doit partir d’une question historique soigneusement formulée et, par conséquent, inclure une discussion sur l’échelle de l’analyse. En bref : pourquoi est-il important de répondre à la question et pourquoi les techniques de vision par ordinateur sont-elles nécessaires pour y répondre ?
Deuxièmement, à la suite des discussions dans le domaine de l’éthique de l’apprentissage automatique4,5, qui cherchent à aborder la question des biais dans l’apprentissage automatique (ML, machine learning), les historiens devraient être conscients du fait que les techniques de vision par ordinateur éclairent certaines parties des corpus visuels, mais peuvent négliger, mal identifier, mal classer ou même laisser dans l’ombre d’autres parties. En tant qu’historiens, nous sommes depuis longtemps conscients que nous regardons le passé à partir de notre propre époque, et par conséquent, toute application des techniques de vision par ordinateur devrait inclure une discussion sur un éventuel « biais historique ». Comme (la plupart) des modèles de vision par ordinateur sont entraînés sur des données contemporaines, nous courons le risque de projeter les biais temporels de ces données sur les archives historiques. Bien qu’il ne soit pas possible, dans le cadre de cette leçon en deux parties, d’explorer pleinement la question du biais, il convient de la garder à l’esprit.
Objectifs de la leçon
Cette leçon en deux parties a pour but de :
- Fournir une introduction aux méthodes de vision par ordinateur basées sur l’apprentissage profond pour la recherche en sciences humaines. L’apprentissage profond est une branche de l’apprentissage automatique (nous en parlerons plus en détail dans les leçons).
- Donnez un aperçu des étapes de l’entraînement d’un modèle d’apprentissage profond.
- Discuter de certaines considérations spécifiques concernant l’utilisation de l’apprentissage profond/la vision par ordinateur pour la recherche en sciences humaines.
- vous aider à décider si l’apprentissage profond peut constituer un outil répondant à vos besoins.
Cette leçon n’a pas pour but de :
- Reproduire d’autres introductions plus générales à l’apprentissage profond, bien qu’elle en partage une partie des objectifs pédagogiques.
- Couvrir tous les détails de l’apprentissage profond et de la vision par ordinateur ; il s’agit de vastes sujets, qu’il n’est pas possible de traiter en profondeur ici.
Compétences préalables suggérées
- La connaissance de Python ou d’un autre langage de programmation sera importante pour suivre ces leçons. Plus précisément, il serait bénéfique de comprendre comment utiliser les variables, l’indexation, et d’avoir une certaine familiarité avec l’utilisation de méthodes provenant de bibliothèques externes.
- Nous supposons que vous êtes familier avec les carnets Jupyter (notebooks), c’est-à-dire que vous savez comment exécuter le code qu’ils contiennent. Si vous n’êtes pas familier avec les carnets, vous trouverez en notre Introduction aux carnets Jupyter une ressource utile en préalable à la présente leçon.
- Ce tutoriel fait appel à des bibliothèques Python externes, mais il n’est pas nécessaire d’en avoir une connaissance préalable car les étapes de l’utilisation de ces bibliothèques seront expliquées au fur et à mesure de leur utilisation.
Configuration de la leçon
Nous vous suggérons d’aborder cette leçon en deux parties en deux temps :
- Tout d’abord, lisez les informations de cette page, pour vous familiariser avec les questions conceptuelles clés et le flux de travail global pour l’entraînement d’un modèle de vision par ordinateur.
- Ensuite, exécutez le code proposé dans le carnet Jupyter associé.
Dans cette leçon en deux parties, nous allons utiliser une approche de la vision par ordinateur basée sur l’apprentissage profond. Le processus de mise en place d’un environnement pour l’apprentissage profond est devenu plus facile mais peut encore être complexe. Nous avons essayé de conserver ce processus de configuration aussi simple que possible, et nous proposons un cheminement le plus direct possible pour commencer à exécuter le code de la leçon.
Carnets
Cette leçon en deux parties est disponible sous forme d’un carnet (notebook) Jupyter. Nous vous recommandons d’exécuter le code de cette leçon à l’aide de ce carnet compagnon, ce qui convient parfaitement à la nature exploratoire que nous allons mettre en œuvre.
Exécuter les carnets
Vous pouvez utiliser les carnets de différentes manières. Nous vous encourageons vivement à utiliser les instructions de configuration dans le cloud plutôt que de configurer un environnement local. Et ce, pour plusieurs raisons :
- Le processus de configuration de l’apprentissage profond dans un environnement cloud peut être beaucoup plus simple que la configuration locale. De nombreux ordinateurs portables et personnels ne disposent pas de ce type de matériel et le processus d’installation des pilotes logiciels nécessaires peut prendre beaucoup de temps.
- Le code de cette leçon s’exécutera beaucoup plus rapidement si un type spécifique de carte graphique (GPU) est disponible. Cela permettra une approche interactive du travail avec les modèles et leurs résultats.
- Les GPU sont plus efficaces sur le plan énergétique pour certaines tâches comparés aux unités centrales de traitement (CPU), y compris pour le type de tâches sur lesquelles nous allons travailler dans ces leçons.
Kaggle
Kaggle est un site Web qui héberge des jeux de données, organise des concours de science des données et fournit des ressources pédagogique. Kaggle héberge également des carnets Jupyter, y compris avec accès à des GPU.
Pour exécuter le code de la leçon sur Kaggle, vous devrez :
- Créer un compte sur Kaggle (vous devrez fournir un numéro de téléphone), ou vous connecter à votre compte existant.
- Aller sur https://www.kaggle.com/code/davanstrien/progamming-historian-deep-learning-pt1. Les données utilisées dans cette leçon sont fournies avec ces carnets.
- Cliquez sur le bouton “Copy&Edit” pour créer une copie du carnet.
- Réglez l’option “Accelerator” sur “GPU” ; vous trouverez cette option dans l’onglet “Settings”.
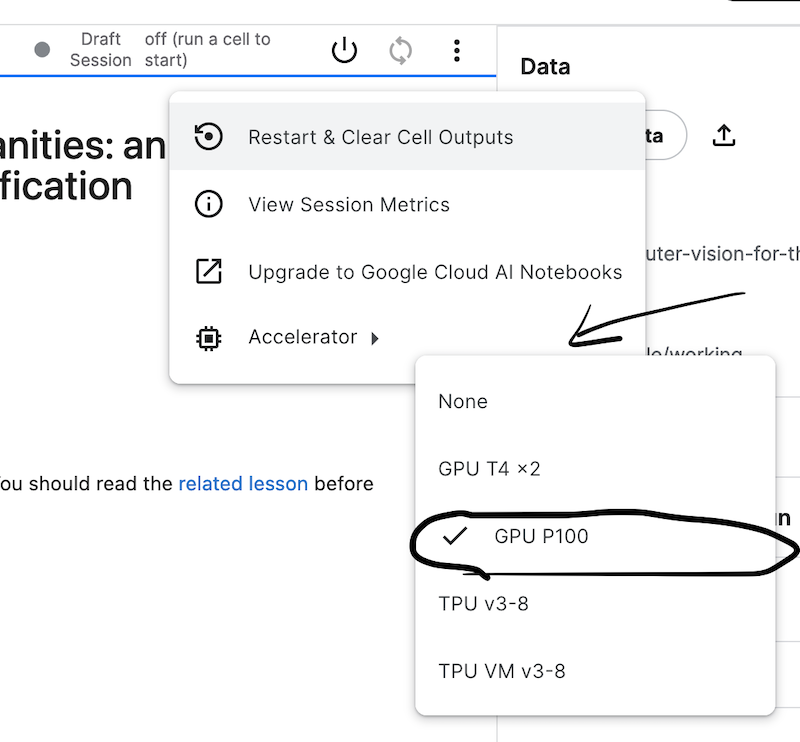
Figure 1 : Menu de paramétrage des notebooks Kaggle
- L’interface des carnets Kaggle devrait vous être familière si vous avez déjà utilisé des carnets Jupyter. Pour exécuter une cellule contenant du code, cliquez sur le bouton en forme de triangle pointant vers la droite ou, si la cellule est sélectionnée, utilisez Maj + Entrée.
- N’oubliez pas de fermer votre session une fois que vous avez fini de travailler avec les notebooks. Vous pouvez le faire en accédant au menu déroulant “Run” en haut d’un carnet Kaggle.
Kaggle dispose d’une documentation sur l’utilisation de ses carnets ainsi que de conseils sur l’utilisation efficace des GPU.
Travailler en local
Si vous ne souhaitez pas utiliser une configuration dans le cloud, vous pouvez suivre les instructions de configuration locale de cette leçon.
Courte introduction à l’apprentissage machine
Avant de passer au premier exemple pratique, il peut être utile de rappeler brièvement ce que l’on entend par « apprentissage automatique ». L’apprentissage automatique vise à permettre aux ordinateurs d’« apprendre » à partir de données au lieu d’être explicitement programmés pour faire quelque chose. Par exemple, si nous voulons filtrer les spams, nous pouvons adopter plusieurs approches différentes. L’une d’elles consiste à lire des exemples de courriels « spam » et « non spam » pour voir si nous pouvons identifier des signaux indiquant qu’un courriel est un spam. À cet effet, nous pourrions par exemple trouver des mots-clés qui, selon nous, sont susceptibles d’indiquer un spam. Nous pourrions ensuite écrire un programme qui ferait quelque chose comme ceci pour chaque courriel reçu :
count number spam_words in email:
if number spam_words >= 10:
email = spam
En revanche, une approche par apprentissage automatique entraînerait un algorithme d’apprentissage automatique sur des exemples étiquetés de courriels qui sont des « spam » et « non spam ». Cet algorithme, après une exposition répétée aux exemples, « apprendrait » des modèles qui indiquent le type de courriels. Il s’agit d’un exemple d’« apprentissage supervisé », un processus dans lequel un algorithme est exposé à des données étiquetées, et c’est ce sur quoi ce tutoriel va se concentrer. Il existe différentes approches pour gérer ce processus d’apprentissage, dont certaines seront abordées dans cette leçon. Un autre type d’apprentissage automatique qui ne nécessite pas d’exemples étiquetés est l’« apprentissage non supervisé ».
new Dans le domaine de la vision par ordinateur, reconnaître automatiquement des objets impose aussi d’identifier des signaux caractéristiques, ainsi la forme des oreilles d’un chat ou d’un chien, celle de leur museau, la taille des yeux, etc. Ces signaux doivent être identifiés (manuellement) pour chaque classe d’objet puis un algorithme doit s’appuyer sur ces signaux extraits des images pour tenter de dire si une image à reconnaître contient un chat ou un chien. Cette approche implique un travail laborieux à mener pour chaque contexte visuel à traiter (choix des caractéristiques, des algorithmes). Dans le cas de l’apprentissage automatique, tant la sélection des signaux caractéristiques que le processus de classification des objets sont appris par l’exemple (ici des images annotées chien/chat). new
L’apprentissage automatique présente des avantages et des inconvénients. Dans notre exemple de courrier électronique, il est notamment avantageux de ne pas avoir à identifier manuellement ce qui indique si un courrier électronique est un spam ou non. Cela est particulièrement utile lorsque les signaux peuvent être subtils ou difficiles à détecter. Si les caractéristiques des courriers électroniques non sollicités devaient changer à l’avenir, vous n’auriez pas besoin de réécrire l’ensemble de votre programme, mais vous pourriez réentraîner votre modèle avec de nouveaux exemples. Parmi les inconvénients, citons la nécessité de disposer d’exemples étiquetés, dont la création peut prendre du temps. L’une des principales limites des algorithmes d’apprentissage automatique est qu’il peut être difficile de comprendre comment ils ont pris une décision, c’est-à-dire pourquoi un courriel a été étiqueté comme spam ou non. Les implications de ce phénomène varient en fonction du « pouvoir » accordé à l’algorithme dans un système. À titre d’exemple, l’impact négatif potentiel d’un algorithme qui prend des décisions automatisées concernant une demande de prêt est probablement beaucoup plus élevé que celui d’un algorithme qui fait des recommandations de contenus sur un service de streaming.
Entraînement d’un modèle de classification d’images
Maintenant que nous avons une compréhension générale de l’apprentissage automatique, nous allons passer à notre premier exemple d’utilisation de l’apprentissage profond pour la vision par ordinateur. Dans cet exemple, nous allons construire un classificateur d’images qui affecte les images à l’une des deux catégories ciblées, en fonction de données d’entraînement étiquetées.
Les données : classer des images de presse ancienne
Dans cette leçon, nous allons travailler avec un jeu de données dérivés du projet Newspaper Navigator. Ce jeu de données est constitué du contenu visuel extrait de 16 358 041 pages de journaux historiques numérisés provenant de la bibliothèque du Congrès Chronicling America collection.
Les données du projet Newspaper Navigator ont été créées à l’aide d’un modèle d’apprentissage profond pour la détection d’objets. Ce modèle a été entraîné sur des pages annotées de Chronicling America datant de la Première Guerre mondiale, dont des annotations faites par les volontaires du projet de crowdsourcing Beyond Words.6 Il a permis de classer ces images dans sept catégories, dont photographie et publicité.
Si vous souhaitez en savoir plus sur la façon dont cet ensemble de données a été créé, reportez-vous à l’article qui décrit ce travail, ou consulter le dépôt GitHub qui contient le code et les données d’entraînement. Nous ne reproduirons pas ce modèle. Nous allons plutôt utiliser la sortie de ce modèle comme point de départ pour créer les données que nous utilisons dans ce tutoriel. Puisque les données du Newspaper Navigator sont prédites par un modèle d’apprentissage automatique, elles contiendront des erreurs ; pour l’instant, nous accepterons que les données avec lesquelles nous travaillons soient imparfaites. Un certain degré d’imperfection et d’erreur est souvent le prix à payer si nous voulons travailler avec des collections « à l’échelle » en utilisant des méthodes informatiques.
Classer des publicités
Pour notre première application de l’apprentissage profond, nous allons nous concentrer sur la classification d’images prédites comme des publicités (n’oubliez pas que ces données sont basées sur des prédictions et qu’elles contiendront quelques erreurs). Plus précisément, nous allons travailler avec un échantillon de publicités couvrant les années 1880-1885.
Détecter si les publicités contiennent des illustrations
Si vous regardez les images des publicités, vous verrez que certaines d’entre elles ne contiennent que du texte, tandis que d’autres comportent une sorte d’illustration.
Une publicité illustrée 7 :

Figure 2. Un exemple de publicité illustrée
Une annonce textuelle 8:

Figure 3. Un exemple de publicité sans illustration
Notre classificateur sera entraîné à prédire à quelle catégorie appartient une publicité. Nous pourrions l’utiliser pour automatiser la recherche de publicités comportant des illustrations en vue d’une analyse « manuelle » plus poussée. Nous pourrions également utiliser ce classificateur plus directement pour quantifier le nombre d’annonces contenant des illustrations au cours d’une année donnée et découvrir si ce nombre a évolué dans le temps, ainsi que l’influence d’autres facteurs tels que le lieu de publication. L’utilisation prévue de votre modèle aura un impact sur les étiquettes sur lesquelles vous choisissez de l’entraîner et sur la manière dont vous choisissez d’évaluer si un modèle est suffisamment performant. Nous approfondirons ces questions au fil de cette leçon en deux parties.
Introduction à la bibliothèque fastai
fastai est une bibliothèque Python pour l’apprentissage profond « qui fournit aux praticiens des composants de haut niveau pouvent rapidement et facilement fournir des résultats de pointe dans des domaines d’apprentissage profond standard, et fournit aux chercheurs des composants de bas niveau qui peuvent être assemblés et assortis pour construire de nouvelles approches »9. La bibliothèque est développée par fast.ai, un organisme de recherche qui vise à rendre l’apprentissage profond plus accessible. Outre la bibliothèque fastai, fast.ai organise également des cours gratuits et mène des recherches.
La bibliothèque fastai a été choisie pour ce tutoriel pour plusieurs raisons :
- Elle s’attache à rendre l’apprentissage profond accessible, notamment par la conception de l’API de la bibliothèque.
- Elle facilite l’utilisation de techniques qui ne nécessitent pas une grande quantité de données ou de ressources de calcul.
- De nombreuses bonnes pratiques sont mises en œuvre par « défaut », ce qui permet d’obtenir de bons résultats.
- Il existe différents niveaux d’interaction avec la bibliothèque, en fonction de l’importance des modifications à apporter aux détails de niveau inférieur.
- La bibliothèque s’appuie sur PyTorch, ce qui facilite l’utilisation du code existant.
Bien que ce tutoriel se concentre sur fastai, de nombreuses techniques présentées sont également applicables à d’autres frameworks IA.
Creéer un classifieur d’images avec fastai
La section suivante décrit les étapes de la création et de l’apprentissage d’un modèle de classification permettant de prédire si une publicité est composée uniquement de texte ou contient également une illustration. Brièvement, les étapes seront les suivantes :
- Charger les données
- Créer un modèle
- Entraîner le modèle
Ces étapes seront abordées assez rapidement ; ne vous inquiétez pas si vous avez l’impression de ne pas tout suivre dans cette section, la leçon reviendra sur ce qui se passe de manière plus détaillée lorsque nous arriverons à la section le flux de travail d’un problème de vision par ordinateur.
La première chose que nous allons faire est d’importer les modules nécessaires de la bibliothèque fastai. Dans ce cas, nous importons vision.all puisque nous travaillons sur une tâche de vision par ordinateur.10
from fastai.vision.all import *
Nous importons également Matplotlib, une bibliothèque permettant de créer des visualisations en Python. Nous demanderons à Matplotlib d’utiliser un autre style en utilisant la méthode style.use.
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('seaborn')
Charger les données
Les données peuvent être chargées de plusieurs façons à l’aide de la bibliothèque fastai. Les données des publicités consistent en un dossier qui contient les fichiers image, et un fichier CSV qui contient une colonne avec les chemins vers les images, ainsi que l’étiquette associée :
| file | label |
|---|---|
| kyu_joplin_ver01_data_sn84037890_00175045338_1900060601_0108_007_6_97.jpg | text-only |
Il existe plusieurs façons de charger ce type de données en utilisant fastai. Dans cet exemple, nous allons utiliser ImageDataLoaders.from_csv. Comme son nom l’indique, la méthode from_csv de ImagDataLoaders charge les données depuis un fichier CSV. Nous devons préciser à fastai comment charger les données lorsque l’on utilise cette méthode :
- Le chemin vers le dossier où les images et le fichier CSV sont stockés.
- Les colonnes dans le fichier CSV qui contiennent les étiquettes.
- Un ‘item transform’
Resize()pour redimensionner toutes les images à une taille standard.
Nous allons créer une variable ad_data qui sera utilisée pour stocker les paramètres de chargement de ces données :
ad_data = ImageDataLoaders.from_csv(
path="ads_data/", # chemin vers le dossier des fichiers CSV et images
csv_fname="ads_upsampled.csv/", # le nom de notre fichier CSV
folder="images/", # le dossier où nos images sont stockées
fn_col="file", # la colonne 'fichier' dans notre CSV
label_col="label", # la colonne 'étiquette' dans notre CSV
item_tfms=Resize(224, ResizeMethod.Squish), # redimensionnement des images à 224x224 pixels
seed=42, # choix d'une valeur de graine fixe pour rendre les résultats plus reproductibles
)
Il est important de s’assurer que les données ont été chargées correctement. Une façon de le vérifier rapidement est d’utiliser la méthode show_batch() sur nos données. Cela va afficher les images et les étiquettes associées pour un échantillon de nos données. Les exemples que vous recevrez en retour seront légèrement différents de ceux présentés ici.
ad_data.show_batch()

Figure 4. La sortie de ‘show_batch’
C’est un moyen utile de vérifier que vos étiquettes et vos données ont été chargées correctement. Vous pouvez voir ici que les étiquettes (text-only et illustration) ont été associées conformément à la façon dont nous voulons classer ces images.
Créer le modèle
Maintenant que fastai sait comment charger les données, l’étape suivante consiste à créer un modèle avec celles-ci. Pour créer un modèle adapté à la vision par ordinateur, nous allons utiliser la fonction cnn_learner. Cette fonction va créer un ‘Convolutional Neural Network’, un type de modèle d’apprentissage profond souvent utilisé pour les applications de vision par ordinateur. Pour utiliser cette fonction, vous devez passer (au minimum) :
- Les données que le modèle utilisera comme données d’entraînement
- Le type de modèle que nous souhaitons utiliser
C’est suffisant pour créer un modèle de vision par ordinateur avec fastai, mais vous pouvez aussi vouloir passer certaines métriques à suivre pendant l’entraînement. Cela vous permettra d’avoir une meilleure idée de la façon dont votre modèle effectue la tâche sur laquelle vous l’entraînez. Dans cet exemple, nous allons utiliser accuracy comme métrique.
Créons ce modèle et assignons-le à une nouvelle variable learn :
learn = cnn_learner(
ad_data, # les données sur lesquelles le modèle sera entraîné
resnet18, # le type de modèle cible
metrics=accuracy, # la métrique à suivre
)
Entraîner le modèle
Bien que nous ayons créé un modèle cnn_learner, nous n’avons pas encore entraîné le modèle. Ceci est fait en utilisant la méthode fit. L’entraînement est le processus qui permet au modèle de vision par ordinateur d’apprendre à prédire les étiquettes correctes pour les données. Il existe différentes façons d’entraîner (ajuster) ce modèle. Pour commencer, nous allons utiliser la méthode fine_tune. Dans cet exemple, la seule chose que nous allons passer à la méthode est le nombre d’époques (epoch) pour s’entraîner. Chaque passage à travers le jeu de données complet est une epoch. Le temps d’entraînement du modèle dépendra du contexte d’exécution de ce code et des ressources disponibles. Nous traiterons en détail de ces éléments ci-après.
learn.fine_tune(5)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.971876 | 0.344096 | 0.860000 | 00:06 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.429913 | 0.394812 | 0.840000 | 00:05 |
| 1 | 0.271772 | 0.436350 | 0.853333 | 00:05 |
| 2 | 0.170500 | 0.261906 | 0.913333 | 00:05 |
| 3 | 0.125547 | 0.093313 | 0.946667 | 00:05 |
| 4 | 0.107586 | 0.044885 | 0.980000 | 00:05 |
Lorsque vous exécutez cette méthode, vous verrez une barre de progression indiquant la durée de l’entraînement du modèle et le temps restant estimé. Vous verrez également un tableau qui affiche d’autres informations sur le modèle, comme la métrique de précision que nous avons suivie. Vous pouvez voir que dans cet exemple, nous avons obtenu une précision supérieure à 90 %. Si vous exécutez le code vous-même, le score obtenu peut être légèrement différent.
Résultats
Alors que les techniques d’apprentissage profond sont généralement perçues comme nécessitant de grandes quantités de données et une puissance de calcul importante, notre exemple montre que pour de nombreuses applications, des ensembles de données plus petits suffisent. Dans cet exemple, nous aurions pu utiliser d’autres approches ; l’objectif n’était pas de montrer la meilleure solution avec cet ensemble de données particulier, mais de donner une idée de ce qui est possible de faire avec un nombre limité d’exemples étiquetés.
Guide approfondi de la vision par ordinateur à l’aide de l’apprentissage profond
Maintenant que nous avons une vue d’ensemble du processus, entrons dans les détails de son fonctionnement.
Le flux de travail d’un problème de vision par ordinateur supervisé
Cette section commence par examiner certaines des étapes du processus de création d’un modèle de vision par ordinateur basé sur l’apprentissage profond. Ce processus implique une série d’étapes, dont certaines seulement concernent directement l’entraînement des modèles. Une illustration générale d’un pipeline d’apprentissage machine supervisé pourrait ressembler à ceci :

Figure 5. Une illustration générale d’un pipeline d’apprentissage machine supervisé
Nous pouvons constater qu’il y a un certain nombre d’étapes avant et après la phase d’entraînement du modèle dans le flux. Avant d’entamer l’entraînement d’un modèle, nous avons besoin de données. Dans cette leçon, les données d’image ont déjà été préparées et vous n’avez donc pas à vous préoccuper de cette étape. Cependant, lorsque vous utiliserez la vision par ordinateur pour vos propres besoins, il est peu probable qu’il existe un ensemble de données correspondant à votre cas d’utilisation exact. Par conséquent, vous devrez créer ces données vous-même. Le processus d’accès aux données variera en fonction du type d’images avec lesquelles vous souhaitez travailler et de l’endroit où elles sont conservées. Certaines collections patrimoniales mettent à disposition des données des jeux d’images, tandis que d’autres ne rendent les images disponibles que par l’intermédiaire d’une « visionneuse ». L’adoption croissante du standard IIIF simplifie également le processus de travail avec des images détenues par différentes institutions.
Une fois que vous disposez d’une collection d’images, l’étape suivante (si vous utilisez l’apprentissage supervisé) consiste à créer des étiquettes pour ces données et à entraîner le modèle. Ce processus sera abordé plus en détail ci-dessous. Une fois le modèle entraîné, vous obtiendrez des prédictions. Ces prédictions sont « notées » à l’aide d’une série de mesures potentielles, dont certaines seront examinées plus en détail dans la Partie 2 de cette leçon.
Une fois qu’un modèle a atteint un score satisfaisant, ses résultats peuvent être utilisés pour une série d’activités « interprétatives ». Une fois que nous disposons des prédictions d’un modèle d’apprentissage profond, il existe différentes options quant à l’utilisation de ces prédictions. Nos prédictions peuvent directement informer des décisions automatisées (par exemple, où les images doivent être affichées dans une collection web), mais il est plus probable que ces prédictions soient lues par un humain pour une analyse plus approfondie. Ce sera particulièrement le cas si l’utilisation prévue est l’exploration de phénomènes historiques.
Entraîner un modèle
En zoomant sur la partie du flux de travail relative à l’apprentissage profond, à quoi ressemble le processus d’entraînement ?
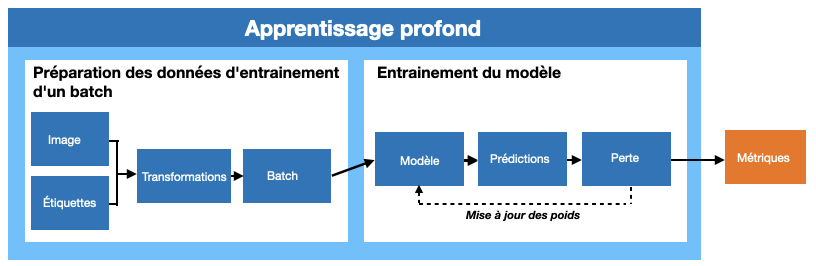
Figure 6. La boucle d’entraînement du deep learning
Un résumé abstrait de la boucle d’entraînement pour l’apprentissage supervisé serait donc : commencer avec des images et des étiquettes, effectuer une préparation pour rendre l’entrée adaptée à un modèle d’apprentissage profond, passer les données à travers le modèle, faire des prédictions pour les étiquettes, calculer à quel point les prédictions sont erronées, mettre à jour le modèle dans le but de générer de meilleures prédictions la prochaine fois. Ce processus est répété un certain nombre de fois. Au cours de cette boucle d’apprentissage, des mesures sont communiquées pour permettre à l’utilisateur du modèle d’évaluer l’efficacité de ce dernier.
Il s’agit évidemment d’une vue synthétique. Examinons une à une les étapes de cette boucle. Bien que la section suivante présente ces étapes à l’aide de code, ne vous inquiétez pas si tout n’est pas clair au début.
Données d’entrée
Pour ce qui est des entrées, nous disposons d’images et d’étiquettes. Bien que l’apprentissage profond s’inspire du fonctionnement de la cognition humaine, la façon dont un ordinateur « voit » est très différente de celle d’un être humain. Tous les modèles d’apprentissage profond prennent des nombres en entrée. Les images étant stockées sur un ordinateur sous la forme d’une matrice de valeurs de pixels, ce processus est relativement simple pour les modèles de vision par ordinateur. Parallèlement à ces images, nous avons une ou plusieurs étiquettes associées à chaque image. Là encore, ces étiquettes sont représentées sous forme de nombres dans le modèle.
Combien de données ?
On croit souvent qu’il faut d’énormes quantités de données pour entraîner un modèle d’apprentissage profond exploitable, mais ce n’est pas toujours le cas. Nous supposons que si vous essayez d’utiliser l’apprentissage profond pour résoudre un problème, vous disposez de suffisamment de données pour justifier de ne pas utiliser une approche manuelle. Le vrai problème est la quantité de données étiquetées dont vous disposez. Il n’est pas possible de donner une réponse définitive à la question « combien de données ? », car cette quantité requise dépend d’un large éventail de facteurs. Un certain nombre de mesures peuvent être prises pour réduire la quantité de données d’entraînement nécessaire, dont certaines seront abordées dans cette leçon.
La meilleure approche consistera probablement à créer des données d’entraînement initiales et à évaluer les performances de votre modèle sur ces données. Vous saurez ainsi s’il est possible de s’attaquer à ce problème particulier. En outre, le processus d’annotation de vos données est précieux en soi. Pour une tâche de classification simple, il est possible de commencer à évaluer si un modèle vaut la peine d’être développé avec quelques centaines d’exemples étiquetés (bien que vous ayez souvent besoin de plus que cela pour entraîner un modèle robuste).
Préparer des mini-lots
Lorsque nous utilisons l’apprentissage profond, il n’est généralement pas possible de passer toutes nos données dans le modèle en une seule fois. Au lieu de cela, les données sont divisées en lots. Lorsqu’on utilise un GPU, les données sont chargées dans la mémoire du GPU un lot à la fois. La taille de ce lot peut avoir un impact sur le processus d’apprentissage, mais elle est le plus souvent déterminée par les ressources informatiques dont vous disposez.
La raison pour laquelle nous utilisons un GPU pour entraîner notre modèle est qu’il sera presque toujours plus rapide d’entraîner un modèle sur un GPU que sur un CPU en raison de sa capacité à effectuer de nombreux calculs en parallèle.
Avant de créer un lot et de le charger sur le GPU, nous devons généralement nous assurer que les images ont toutes la même taille. Cela permet au GPU d’exécuter les opérations de manière efficace. Une fois qu’un lot a été préparé, nous pouvons vouloir effectuer certaines autres transformations supplémentaires sur nos images afin de réduire la quantité de données d’entraînement nécessaires.
Créer un modèle
Une fois que nous avons préparé les données pour qu’elles puissent être chargées un lot à la fois, nous les passons à notre modèle. Nous avons déjà vu un exemple de modèle dans notre premier exemple, resnet18. L’architecture d’un modèle d’apprentissage profond définit la façon dont les données et les étiquettes sont transmises au modèle. Dans cette leçon en deux parties, nous nous concentrons sur un type spécifique d’apprentissage profond qui utilise les réseaux neuronaux convolutifs (CNN, Convolutional Neural Networks).
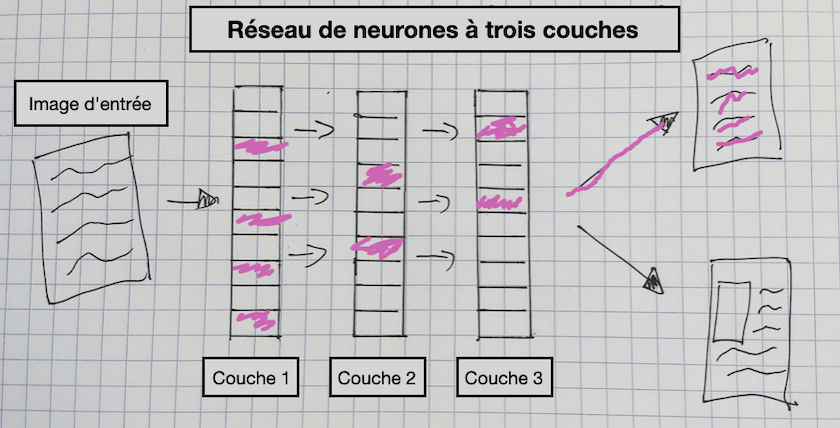
Figure 7. Un réseau neuronal à trois couches
Ce diagramme donne une vue d’ensemble des différents composants d’un modèle CNN. Dans ce type de modèle, une image passe par plusieurs couches avant de prédire une étiquette de sortie pour l’image (« publicité textuelle » dans ce diagramme). Les couches de ce modèle sont mises à jour au cours de l’entraînement afin qu’elles « apprennent » quelles caractéristiques d’une image permettent de prédire une étiquette particulière. Ainsi, par exemple, le CNN que nous avons entraîné sur les publicités mettra à jour les paramètres appelés « poids » pour chaque couche, qui produit alors une représentation de l’image utile pour prédire si une publicité comporte une illustration ou non.
Tensorflow playground est un outil utile pour aider à développer une intuition sur la façon dont ces couches capturent différentes caractéristiques des données d’entrée, et comment ces caractéristiques, à leur tour, peuvent être utilisées pour classer les données d’entrée de différentes façons.
La puissance des CNN et de l’apprentissage profond provient de la capacité de ces couches à coder des modèles très complexes dans les données11. Cependant, il peut souvent être difficile de mettre à jour les poids de manière efficace.
Utiliser un modèle existant ?
Lorsque nous réfléchissons à la manière de créer notre modèle, plusieurs options s’offrent à nous. L’une d’entre elles consiste à utiliser un modèle préexistant qui aurait déjà été entraîné à une tâche particulière. Vous pouvez par exemple utiliser le modèle YOLO. Ce modèle a été entraîné à prédire les boîtes englobantes pour un certain nombre de types d’objets différents dans une image. Bien qu’il puisse s’agir d’un point de départ valable, cette approche présente un certain nombre de limites lorsqu’il s’agit de travailler avec des contenus historiques ou, plus généralement, avec des questions relatives aux sciences humaines. Tout d’abord, les données sur lesquelles ces modèles ont été entraînés peuvent être très différentes de celles que vous utilisez. Cela peut avoir un impact sur les performances de votre modèle sur vos données et conduire à des biais en faveur des images de vos données qui sont similaires aux données d’apprentissage. Un autre problème est que si vous utilisez un modèle existant sans aucune modification, vous êtes limité à utiliser les seules étiquettes sur lesquelles le modèle original a été entraîné.
Bien qu’il soit possible de définir directement un modèle CNN en choisissant les couches que vous souhaitez inclure dans l’architecture de votre modèle, ce n’est généralement pas par là qu’il faut commencer. Il est souvent préférable de commencer par une architecture de modèle existante. Le développement de nouvelles architectures de modèles est un domaine de recherche actif, certains modèles s’avérant bien adaptés à une série de tâches et de données. Souvent, ces modèles sont ensuite mis en œuvre par des frameworks d’apprentissage machine. Par exemple, la bibliothèque Transformers library de Hugging Face met en œuvre un grand nombre des architectures de modèles les plus populaires.
Souvent, nous souhaitons trouver un équilibre entre partir de zéro et exploiter des modèles existants. Dans cette leçon en deux parties, nous présentons une approche qui utilise des architectures de modèles existantes mais modifie légèrement le modèle pour lui permettre de prédire de nouvelles étiquettes. Ce modèle est ensuite entraîné sur de nouvelles données afin d’être mieux adapté à la tâche que nous voulons lui confier. Il s’agit d’une technique connue sous le nom d’apprentissage par transfert (ou transfert learning) qui sera explorée dans l’annexe de cette leçon.
Entraînement
Une fois le modèle créé et les données préparées, le processus d’entraînement peut commencer. Examinons les étapes d’une boucle d’entraînement :
-
Un modèle reçoit des données et des étiquettes, un lot à la fois. Chaque fois qu’un ensemble de données complet est passé à travers un modèle, on parle d’un epoch. Le nombre d’epochs utilisés pour entraîner un modèle est l’une des variables que vous devrez contrôler.
-
Le modèle fait des prédictions pour ces étiquettes sur la base des données fournies, en utilisant un ensemble de poids internes. Dans ce modèle de réseau CNN, les poids sont contenus dans les couches du réseau.
-
Le modèle calcule le degré d’erreur des prédictions en les comparant aux étiquettes réelles. Une « [fonction de perte] »(https://perma.cc/JUD5-J6MQ) (loss function) est utilisée pour calculer le degré d’erreur des prédictions fournies par le modèle.
-
Le modèle modifie ses paramètres internes pour essayer de faire mieux la prochaine fois. La fonction de perte de l’étape précédente renvoie une valeur de perte » (loss value), souvent appelée simplement « perte », qui est utilisée par le modèle pour mettre à jour les poids.
Un « taux d’apprentissage » (learning rate) est utilisé pour déterminer dans quelle mesure un modèle doit être mis à jour sur la base de la perte calculée. Il s’agit d’une autre variable importante qui peut être manipulée au cours du processus de formation. Dans la Partie 2 de cette leçon, nous aborderons une manière possible d’essayer d’identifier un taux d’apprentissage approprié pour votre modèle.
Données de validation
Lorsque nous entraînons un modèle d’apprentissage profond, nous le faisons généralement pour faire des prédictions sur de nouvelles données inédites qui ne contiennent pas d’étiquettes. Par exemple, nous pourrions vouloir utiliser notre classificateur de publicités sur toutes les images d’une période donnée pour compter le nombre de chaque type de publicité (illustrée ou non) apparaissant dans ce corpus. Nous ne voulons donc pas d’un modèle qui n’apprendrait à classer que les données d’apprentissage qui lui sont présentées. Par conséquent, nous utilisons presque toujours une sorte de « données de validation ». Il s’agit de données utilisées pour vérifier que les poids qu’un modèle apprend sur les données d’entraînement s’appliqueront également à de nouvelles données. Dans la boucle d’entraînement, les données de validation sont uniquement utilisées pour « tester » les prédictions du modèle. Le modèle ne les utilise pas directement pour mettre à jour les poids. Cela permet de s’assurer que nous ne finissons pas par « suradapter » notre modèle.
On parle de « surapprentissage » (overfitting) lorsqu’un modèle réussit à faire des prédictions sur les données d’apprentissage, mais que ces prédictions ne se généralisent pas au-delà des données d’apprentissage. En effet, le modèle se « souvient » des données d’apprentissage au lieu d’apprendre des caractéristiques plus générales pour faire des prédictions correctes sur de nouvelles données. Un ensemble de validation permet d’éviter ce problème en vous permettant de voir si le modèle fonctionne bien sur des données qu’il n’a pas apprises. Parfois, une division supplémentaire des données est effectuée et n’est utilisée pour faire des prédictions qu’à la fin de l’apprentissage d’un modèle. Cet ensemble est souvent appelé « ensemble de test ». Un ensemble de test est utilisé pour valider les performances d’un modèle dans le cadre de concours de science des données, tels que ceux organisés sur Kaggle, et pour valider les performances des modèles créés par des partenaires externes. Cela permet de s’assurer qu’un modèle est robuste dans les situations où les données de validation ont été délibérément ou accidentellement utilisées pour « jouer » avec les performances d’un modèle. pas très clair…
Apprentissage par transfert
Dans notre premier classificateur, nous avons utilisé la méthode fine_tune() sur notre learner pour l’apprentissage. Que faisait cette méthode ? Vous aurez vu que la barre de progression se divise en deux parties. Le première epoch n’entraînait que les couches finales du modèle, après quoi les couches inférieures du modèle étaient également entraînées. C’est l’une des méthodes d’apprentissage par transfert dans Fastai. L’importance de l’apprentissage par transfert a déjà été abordée dans les sections précédentes. Pour rappel, l’apprentissage par transfert utilise les « poids » qu’un modèle a précédemment appris sur une autre tâche pour une nouvelle tâche. Dans le cas de la classification d’images, cela signifie généralement qu’un modèle a été entraîné sur un ensemble de données beaucoup plus important. Souvent, cet ensemble de données d’entraînement est ImageNet.
ImageNet est une vaste base de données d’images très utilisée dans la recherche en vision par ordinateur. ImageNet contient actuellement 14 197 122 images avec plus de 20 000 étiquettes différentes. Cet ensemble de données est souvent utilisé comme référence par les chercheurs en vision pour comparer leurs approches. Les questions éthiques liées aux étiquettes et à la production d’ImageNet sont explorées dans The Politics of Images in Machine Learning Training Sets par Crawford et Paglen.4
Pourquoi l’apprentissage par transfert est-il souvent utile ?
Comme nous l’avons vu, l’apprentissage par transfert consiste à utiliser un modèle entraîné à accomplir une tâche pour en réaliser une autre. Dans notre exemple, nous avons utilisé un modèle entraîné sur ImageNet pour classer des images de journaux numérisés du XIXe siècle. Il peut sembler étrange que l’apprentissage par transfert fonctionne dans ce cas, car les images sur lesquelles nous entraînons notre modèle sont très différentes des images d’ImageNet. Bien qu’ImageNet contienne une catégorie pour les journaux, il s’agit essentiellement d’images de journaux dans le contexte de la vie quotidienne, plutôt que d’images découpées dans les pages des journaux. Alors pourquoi l’utilisation d’un modèle formé sur ImageNet est-elle encore utile pour une tâche dont les étiquettes et les images sont différentes de celles d’ImageNet ?
Le diagramme d’un modèle CNN montre qu’il est constitué de différentes couches. Ces couches créent des représentations de l’image d’entrée qui s’appuient sur des caractéristiques particulières de l’image pour prédire une étiquette. Quelles sont ces caractéristiques ? Il peut s’agir de caractéristiques élémentaires, par exemple des formes simples. Il peut aussi s’agir de caractéristiques visuelles plus complexes, comme les traits du visage. Plusieurs techniques ont été développées pour aider à visualiser les différentes couches d’un réseau neuronal. Ces techniques ont permis de constater que les premières couches d’un réseau neuronal ont tendance à apprendre des caractéristiques « de base », par exemple, elles apprennent à détecter des formes géométriques telles que cercles ou lignes, tandis que les couches plus avancées du réseau contiennent des filtres qui codent des caractéristiques visuelles plus complexes, telles que les yeux. Étant donné que nombre de ces caractéristiques capturent des propriétés visuelles utiles pour de nombreuses tâches, le fait de commencer par un modèle déjà capable de détecter des caractéristiques dans des images permettra de détecter des caractéristiques importantes pour la nouvelle tâche, puisque ces nouvelles caractéristiques seront probablement des variantes des caractéristiques que le modèle connaît déjà, plutôt que de nouvelles caractéristiques.
Lorsqu’un modèle est créé dans la bibliothèque fastai à l’aide de la méthode cnn_learner, une architecture existante est utilisée comme « corps » du modèle. Les couches plus profondes ajoutées sont appelées la « tête » du modèle. Le corps utilise par défaut les poids (paramètres) appris lors de l’entraînement sur ImageNet. La partie tête prend la sortie du corps comme entrée avant de passer à une couche finale qui est créée pour s’adapter aux données d’entraînement que vous passez à cnn_learner. La méthode fine_tune n’entraîne d’abord que la partie tête du modèle, c’est-à-dire les dernières couches du modèle, avant de « dégeler » les couches inférieures. Lorsque ces couches sont dégelées, les poids du modèle sont mis à jour par le biais du processus décrit précédemment. Il est aussi possible de contrôler plus activement la quantité d’entraînement des différentes couches du modèle, ce que nous verrons au fur et à mesure que nous avancerons dans un pipeline complet d’entraînement d’un modèle d’apprentissage profond.
Suggestions d’expérimentation
Il est important de savoir ce qui se passe lorsque vous modifiez le processus d’entraînement. Nous vous suggérons de faire une copie notebook et de voir ce qui se passe si vous apportez des changements. Voici quelques suggestions :
- Changez la taille des images en entrée définies dans la transformation
ResizedansImageDataLoaders. - Changer le modèle utilisé dans
cnn_learnerderesnet18àresnet34. - Changez les métriques définies dans
cnn_learner. Certaines métriques incluses dans fastai peuvent être trouvées dans la documentation. - Modifier le nombre d’epochs utilisés dans la méthode
fine_tune.
Si quelque chose « casse », ne vous inquiétez pas ! Vous pouvez retourner au notebook d’origine pour revenir à une version fonctionnelle du code. Dans la prochaine partie de la leçon, les composants d’un pipeline d’apprentissage profond seront abordés plus en détail. L’étude de ce qui se passe lorsque vous apportez des modifications constituera une part importante du savoir-faire nécessaire à l’entraînement d’un modèle de vision par ordinateur.
Partie I : conclusion
Dans cette leçon, nous avons :
- donné un aperçu général de la distinction entre les approches basées sur les règles et les approches basées sur l’apprentissage machine pour aborder un problème,
- montré un exemple de base sur la façon d’utiliser fastai pour créer un classifieur d’images avec relativement peu de temps et de données d’apprentissage,
- présenté une vue d’ensemble des étapes d’un pipeline d’apprentissage profond et identifié les étapes de ce pipeline où les chercheurs en sciences humaines devraient porter une attention particulière,
- réaliser une expérience rudimentaire pour essayer de vérifier si l’apprentissage par transfert est utile pour notre classifieur.
Dans la prochaine partie de cette leçon, nous nous appuierons sur ces fondamentaux et entrerons dans plus de détails.
Annexe : Une expérience non scientifique pour évaluer l’apprentissage par transfert
L’utilisation de l’apprentissage profond dans le contexte d’un travail avec des données patrimoniales n’a pas fait l’objet de recherches approfondies. Il est donc utile d’expérimenter et de valider l’efficacité d’une technique particulière. Par exemple, voyons si l’apprentissage par transfert s’avère utile pour entraîner un modèle permettant de classer les annonces de journaux du XIXe siècle en deux catégories : celles qui contiennent des images et celles qui n’en contiennent pas. Pour ce faire, nous allons créer un nouveau learner avec les mêmes paramètres que précédemment mais avec l’option pretrained fixée à False. Ce drapeau indique à fastai de ne pas utiliser l’apprentissage par transfert. Nous le stockons dans la variable learn_random_start.
learn_random_start = cnn_learner(ad_data, resnet18, metrics=accuracy, pretrained=False)
Maintenant que nous avons créé un nouvel learner, nous allons utiliser la même méthode fine_tune que précédemment et entraîner pour le même nombre d’epochs que la dernière fois.
learn_random_start.fine_tune(5)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.303890 | 0.879514 | 0.460000 | 00:04 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.845569 | 0.776279 | 0.526667 | 00:05 |
| 1 | 0.608474 | 0.792034 | 0.560000 | 00:05 |
| 2 | 0.418646 | 0.319108 | 0.853333 | 00:05 |
| 3 | 0.317584 | 0.233518 | 0.893333 | 00:05 |
| 4 | 0.250490 | 0.202580 | 0.906667 | 00:05 |
Le meilleur score de précision que nous obtenons lorsque nous initialisons les poids de manière aléatoire est de ~90%. En comparaison, si nous retournons à notre modèle original, qui est stocké dans une variable learn, et utilisons la méthode validate(), nous obtenons les métriques (dans ce cas la précision) calculées sur l’ensemble de validation :
learn.validate()
(#2) [0.04488467052578926,0.9800000190734863]
Nous constatons qu’il existe une assez grande différence entre les performances des deux modèles. Nous avons conservé le même contexte excepté le drapeau pretrained, que nous avons positionné à False. Ce drapeau détermine si le modèle démarre à partir des poids appris lors de l’entraînement sur ImageNet ou à partir de poids « aléatoires »12. Cela ne prouve pas de manière concluante que l’apprentissage par transfert fonctionne, mais cela suggère une qu’il est raisonnable de l’utiliser par défaut.
Notes
-
Romein, C. Annemieke, Max Kemman, Julie M. Birkholz, James Baker, Michel De Gruijter, Albert Meroño‐Peñuela, Thorsten Ries, Ruben Ros, and Stefania Scagliola. ‘State of the Field: Digital History’. History 105, no. 365 (2020): 291–312. https://doi.org/10.1111/1468-229X.12969. ↩
-
Moretti, Franco. Distant Reading. Illustrated Edition. London ; New York: Verso Books, 2013. ↩
-
Wevers, Melvin, and Thomas Smits. ‘The Visual Digital Turn: Using Neural Networks to Study Historical Images’. Digital Scholarship in the Humanities 35, no. 1 (1 April 2020): 194–207. https://doi.org/10.1093/llc/fqy085. ↩
-
Crawford, K., Paglen, T., 2019. Excavating AI: The Politics of Training Sets for Machine Learning. https://www.excavating.ai (accessed 2.17.20). ↩ ↩2
-
Jo, Eun Seo, and Timnit Gebru. ‘Lessons from Archives: Strategies for Collecting Sociocultural Data in Machine Learning’. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, 306–316. FAT* ’20. New York, NY, USA: Association for Computing Machinery, 2020. https://doi.org/10.1145/3351095.3372829. ↩
-
Ces annotations comprennent une “boîte englobantes” autour des images, ainsi que des informations sur le type d’image contenu dans cette boîte. Ce modèle de détection d’objets a été entraîné sur ces données et a ensuite été utilisé pour faire des prédictions sur l’ensemble de la collection Chronicling America. Le modèle extrait les images de la page et les classe dans une parmi sept catégories. Lee, Benjamin Charles Germain, Jaime Mears, Eileen Jakeway, Meghan Ferriter, Chris Adams, Nathan Yarasavage, Deborah Thomas, Kate Zwaard, and Daniel S. Weld. ‘The Newspaper Navigator Dataset: Extracting And Analyzing Visual Content from 16 Million Historic Newspaper Pages in Chronicling America’. ArXiv:2005.01583 [Cs], 4 May 2020. https://doi.org/10.48550/arXiv.2005.01583. ↩
-
Arizona republican. [volume] (Phoenix, Ariz.) 1890-1930, March 29, 1895, Page 7, Image 7. Image provided by Arizona State Library, Archives and Public Records; Phoenix, AZ. https://chroniclingamerica.loc.gov/lccn/sn84020558/1895-03-29/ed-1/seq-7/. ↩
-
The Indianapolis journal. [volume] (Indianapolis [Ind.]) 1867-1904, February 06, 1890, Page 8, Image 8. Image provided by Indiana State Library. https://chroniclingamerica.loc.gov/lccn/sn82015679/1890-02-06/ed-1/seq-8/. ↩
-
Howard, Jeremy, and Sylvain Gugger. ‘Fastai: A Layered API for Deep Learning’. Information 11, no. 2 (16 February 2020): 108. https://doi.org/10.3390/info11020108. ↩
-
Using ‘star imports’ est généralement déconseillé en Python. Cependant, fastai utilise
__all__pour fournir une liste de packages qui devraient être importés lors de l’utilisation de l’import étoile. Cette approche est utile pour les travaux exploratoires, mais il se peut que vous souhaitiez modifier vos importations pour qu’elles soient plus explicites. ↩ -
Les réseaux neuronaux sont théoriquement capables d’approximer n’importe quelle fonction. La preuve mathématique de cette capacité existe sous plusieurs formes, sous le nom de “théorème d’approximation universelle”. Ces preuves ne font pas partie des éléments que vous aurez besoin de connaître pour utiliser l’apprentissage profond dans la pratique. Toutefois, si vous êtes intéressé, vous trouverez un bon aperçu de l’idée dans cette vidéo YouTube. ↩
-
Cette initialisation n’est pas réellement aléatoire dans le framework fastai, et utilise à la place l’initialisation Kaiming. ↩