This is the draft website for Programming Historian lessons under review. Do not link to these pages.
For the published site, go to https://programminghistorian.org
##
- Présenter Tropy en un clin d’oeil
- Pourquoi utiliser Tropy
- Le(s) jeu(x) de données de la leçon
- Démarrer avec Tropy
- Importer et organiser les fichiers images de ses sources
- Organiser les fichiers images importés
- Décrire ses sources
- Opérations au niveau de l’objet
- Extensions d’un projet Tropy
- Bibliographie
- Notes de fin
Présenter Tropy en un clin d’oeil
Tropy est un logiciel qui permet de gérer les images numériques de sources primaires tels les documents d’archives, les monuments, les œuvres d’art ou, au final, tout ce qui, dans un contexte de recherche précis, constitue une source dont on dispose sous forme d’image numérique. Il s’agit d’un logiciel à code source ouvert et gratuit qui peut être librement téléchargé à partir de son site web - ce que nous recommandons de faire à celles et ceux qui souhaitent exécuter cette leçon.
Le logiciel a été conçu et développé depuis 2016 au sein d’établissements d’enseignement supérieur et de recherche interdisciplinaires, tel le Centre pour l’histoire et les nouveaux médias Roy Rosenzweig de l’université George Mason (Virginie, Etats-Unis) et le Centre pour l’histoire contemporaine et digitale de l’université du Luxembourg. Tropy bénéficie en outre de l’appui de l’organisation à but non lucratif Digital Scholar qui promeut la production et diffusion de logiciels à code source ouvert à des fins d’usage académique.
En ce qui concerne la documentation d’utilisation, un guide officiel est disponible en anglais. De surcroît, un forum Tropy existe aussi pour les utilisatrices et les utilisateurs qui souhaitent aborder des questions spécifiques avec la communauté (notamment en anglais). Par ailleurs, Tropy dispose d’une chaîne sur YouTube proposant des vidéos éducatives notamment en anglais et en espagnol, mais pas en français à l’heure où cette leçon est publiée. Enfin, Tropy est présent sur les principaux réseaux sociaux en ligne – davantage d’informations sont disponibles sur son site web.
Pour le lectorat francophone, la traduction partielle et officieuse de la documentation du logiciel, effectuée en 2019, peut s’avérer utile. De même, divers tutoriels dont certains audiovisuels sont disponibles en ligne. Pour en savoir plus sur ces ressources francophones, merci de consulter la section afférente des références bibliographiques.
Pourquoi utiliser Tropy
Tropy est une application assez unique en son genre qui permet d’organiser et annoter à partir d’une seule interface les fichiers images de sources primaires. Son avantage est d’avoir été spécialement conçue pour répondre à l’évolution des pratiques de collecte et d’organisation des sources historiques à l’ère numérique afin de faciliter leur organisation et exploitation à des fins d’analyse.
Pourquoi donc recourir à une application spécifique, alors qu’il est tout à fait possible de s’appuyer sur des systèmes d’organisation de fichiers plus traditionnels et tout aussi efficaces ? C’est ce que nous décrivent en tout cas d’expérience un historien de l’intégration européenne sur son blog ou encore une historienne de la Première guerre mondiale dans une bande dessinée.
Si vous pensez être plus adepte d’un système d’organisation classique de vos fichiers sur votre disque dur - sans oublier de sauvegarder régulièrement sur un autre support ! - et hésitez de vous lancer pour le moment dans des nouveautés, vous avez intérêt à vous diriger vers la leçon sur les bonnes pratiques d’organisation des fichiers des données d’une recherche !
L’avènement des technologies web a favorisé l’émergence et la multiplication, surtout depuis les années 2000, des bibliothèques et des archives numériques. Des vagues successives de numérisation de masse, la mise en place d’infrastructures de stockage et de publication électronique y compris des protocoles et standards de description, ont rendu les collections patrimoniales accessibles à distance et, souvent, libres à télécharger. Par conséquent, de plus en plus de « matériaux » de recherche historique sont disponibles sous forme de fichiers numériques qu’il est possible d’obtenir et d’utiliser à des fins de recherche personnelle, sinon de partage.
Certes, il serait illusoire de croire que tout est numérisé : à titre d’exemple, en France, les fonds numérisés des trois services d’archives à compétence nationale (Archives nationales, départementales et régionales) totalisaient en 2020 environ cinq cents millions de documents textuels et iconographiques dont l’ensemble n’était pourtant pas accessible en ligne.1 Ces documents sont estimés représenter « un pourcentage minime » des collections conservées par ces archives. Néanmoins, même ainsi, les historiens et les historiennes doivent désormais composer avec une masse de fonds d’archives numérisées qui va croissant.
En outre, les centres d’archives ont progressivement adopté des politiques plus permissives quant à la possibilité de reproduction photographique de leurs ressources de la part du public. L’époque où il fallait prévoir un petit budget pour effectuer un nombre - parfois limité - de photocopies en papier semble définitivement révolu grâce à la démocratisation et la généralisation de l’usage d’appareils de reproduction photographique (appareil photo numérique, smartphone, applications de numérisation). Il s’agit, en réalité, d’une médiation supplémentaire entre l’historien(ne) et ses sources.2 Extraire les sources de leur contexte d’origine en les numérisant, rend possible de construire sa propre archive hybride, selon une problématique de recherche donnée.
Ainsi, la numérisation à la fois de la source historique et de la pratique de sa collecte, mais aussi de son analyse avec la génération de données secondaires (annotations, données d’analyse…), ont débouché sur de nouveaux défis concernant l’organisation, la gestion et la préservation de l’ensemble de ces données de recherche de plus en plus volumineuses. Déjà dans sa forme analogique, l’archive se prêtait à la métaphore du flux : « démesurée », « envahissante comme les marées d’équinoxes, les avalanches ou les inondations ».3 À son tour, l’archive numérique semble presque côtoyer le chaos :
« […] L’impératif de photographier le plus [de documents] possible amène à dissocier les objets de leur contexte, atomise les documents en les transformant en fragments et, tout en promettant l’abondance, débouche sur du chaos […]. Il n’existe pas de solution technologique rapide […] pour les chercheurs et chercheuses à la dérive devant une mer silencieuse de fichiers JPG ».4 (N.D.L.R. L’extrait a été librement traduit par les soins de l’auteure de la leçon en français).
Tropy vise donc à offrir une infrastructure logicielle, simple d’utilisation et legère, pour répondre aux besoins concrets qui émergent lors des phases distinctes d’une recherche historique (collecte, organisation, analyse) menée avec des sources historiques sous forme de fichiers d’images numériques. Cette infrastructure logicielle permet d’abriter des fichiers en provenance de divers centres d’archives, et donc de combiner de différentes temporalités d’une recherche, avec aussi l’avantage de pouvoir faire côtoyer des formats hétéroclites (PDF, formats images tels JPEG, PNG etc). C’est ainsi que Tropy permet de (re)construire l’archive d’une recherche et effectuer les opérations suivantes :
- Rassembler des photos de documents ou d’autres sources primaires faites lors de séjours aux centres d’archives ou obtenues à partir de collections numériques disponibles en ligne ou encore collectées de ses propres moyens
- Classifier et organiser ces matériaux en séries qui ont du sens pour une recherche spécifique
- Contextualiser les sources en attribuant aux fichiers images qui les représentent des métadonnées d’origine (date d’un document, série et sous-série du fonds d’archive de provenance…)
- Annoter les sources, produire des transcriptions, prendre des notes, indexer à la fois les photos et les données qui émanent de ces opérations supplémentaires dans un environnement unifié
- Croiser de manière relativement facile et intuitive des sources lors de la phase de la rédaction d’un travail de recherche, ce qui permet d’optimiser le temps consacré à la rédaction
- Naviguer facilement et rapidement entre les différents sous-ensembles des sources
Le(s) jeu(x) de données de la leçon
L’intention de cette leçon était de fournir un jeu de données de sources visuelles pertinentes pour un public francophone. La tâche s’est néanmoins avérée compliquée à cause des restrictions appliquées sinon à la collecte, définitivement à la réutilisation et surtout au partage des images en provenance d’archives institutionelles ou de réseaux sociaux numériques. Exposer ces difficultés, plutôt que de fournir simplement les jeux de données d’exercice actuellement proposés, vise à sensibiliser le lectorat quant aux réels défis posés par ce type de données de recherche et qu’il faudra relever.
Dans une certaine mesure, Tropy fait pareil en permettant d’enregistrer systématiquement, sous forme de métadonnées, des informations sur les droits d’utiisation des images d’un corpus donné, anticipant une future mise en ligne ou une réutilisation quelconque. Il vaut mieux ne pas négliger d’enregistrer ce type d’informations dès le début d’un projet ou, à défaut, avoir conscience qu’il s’agit là d’une question à resoudre avant de publier ou partager des données de recherche, si l’intention existe.
La leçon offre la possibilité d’accéder à trois jeux de données distincts afin d’opter pour celui qui correspond au mieux aux intérêts - et aux niveaux des compétences numériques - des lecteurs et des lectrices.
- Le premier jeu de données consiste aux affiches numérisées de Mai 68, accessibles au moyen d’une recherche simple sur le site de Gallica. Les conditions de réutilisation de ces images rendent préférable de fournir la requête précise, le rapport de recherche avec les résultats attendus, ainsi qu’un script écrit en R afin que les lecteurs et lectrices puissent collecter ces données par leurs soins.
- Le deuxième jeu de données rassemble principalement les URL de l’ensemble des photos sous licence libre qui sont indexées sous le mot-clé “Occupy Wall Street” et disponibles sur le réseau social numérique Flickr. Les fichiers ont été téléchargés en utilisant l’API de Flickr à l’aide d’un script R, mais seules les URL sont partagées pour que celles et ceux qui souhaitent travailler avec ce jeu de données puissent télécharger le nombre de photos susceptibles de correspondre à leurs besoins et intérêts.
- Le troisième jeu de données consiste aux fichiers images des affiches du mouvement du Printemps érable québécois de 2012 disponibles sous licence libre sur un site créé dans le cadre d’une recherche universitaire et qui sert d’archive vivante de la production visuelle du mouvement en question. Des explications sont fournies ci-dessous pour contextualiser et pour accéder à chaque jeu de données.
Les scripts en R qui ont permis de travailler avec les API de Gallica et de Flickr ont été préparés et exécutés par Thomas Soubiran, ingénieur d’études en analyse de données au CNRS.
Les affiches numérisées de Mai 68
Pour découvrir comment travailler avec Tropy, l’intention originelle était d’utiliser un corpus d’environ quatre cents affiches numérisées de Mai 1968 en France accessibles sur le site de Gallica, la bibliothèque numérique de la Bibliothèque nationale de France (ci-après BnF) et de ses institutions partenaires. Ces affiches, des sérigraphies pour la plupart, ont été des créations du dit Atelier populaire de l’Ecole des Beaux-Arts de Paris lors de l’occupation de cette école en mai-juin 1968, mais aussi d’ateliers de lutte du même type qui se sont constitués dans d’autres villes (Montpellier, Marseille, Strasbourg…). Gallica fournit un accès unifié à une collection numérisée quasi-complète qui rassemble des items physiquement présents dans diverses institutions. Les numérisations datent des années 2010 et témoignent aussi de la patrimonialisation de l’évènement Mai 68 et son effet sur la création de la source numérisée.
Les fichiers images des affiches sont téléchargeables en format PDF ou JPEG depuis le site de Gallica, mais il ne faut pas croire qu’elles sont accessibles directement. Il faut d’abord formuler une requête en se servant des fonctionnalités de recherche de Gallica, que ce soit du moteur de recherche simple ou d’une recherche avancée. Nous avons utilisé le moteur de recherche simple pour effectuer une requête avec le mot-clé France -- 1968 (Journées de mai) en filtrant préalablement les résultats pour obtenir seulement des images. Le mot-clé mobilisé dans la requête est le mot-matière du thésaurus (vocabulaire contrôlé) utilisé par la BnF pour indexer ses ressources qui désigne l’évènement qui nous intéresse. Cela a permis d’obtenir les résultats les plus pertinents possible. La recherche a retourné une liste de 458 notices qui, quitte à être un peu nettoyée, correspond assez fidèlement aux affiches de Mai 68. Par la suite, il est possible d’obtenir les fichiers images qui correspondent aux notices à l’aide d’un script R qui permet de dialoguer directement avec l’API de Gallica.
Si les métadonnées de Gallica sont sous licence ouverte, il s’avère nettement plus compliqué de partager dans le cadre de cette leçon les fichiers images des affiches. C’est pourquoi nous fournissons ici a) les instructions pour reproduire la requête dans le catalogue de Gallica, afin d’obtenir les mêmes résultats, b) le rapport de recherche avec les métadonnées des affiches, c) le script R qui permet à celles et ceux qui souhaitent expérimenter avec un langage de programmation d’obtenir les images via l’API de Gallica. Et, bien sûr, il est toujours possible de télécharger les fichiers images un par un à l’aide des notices de la requête initiale.
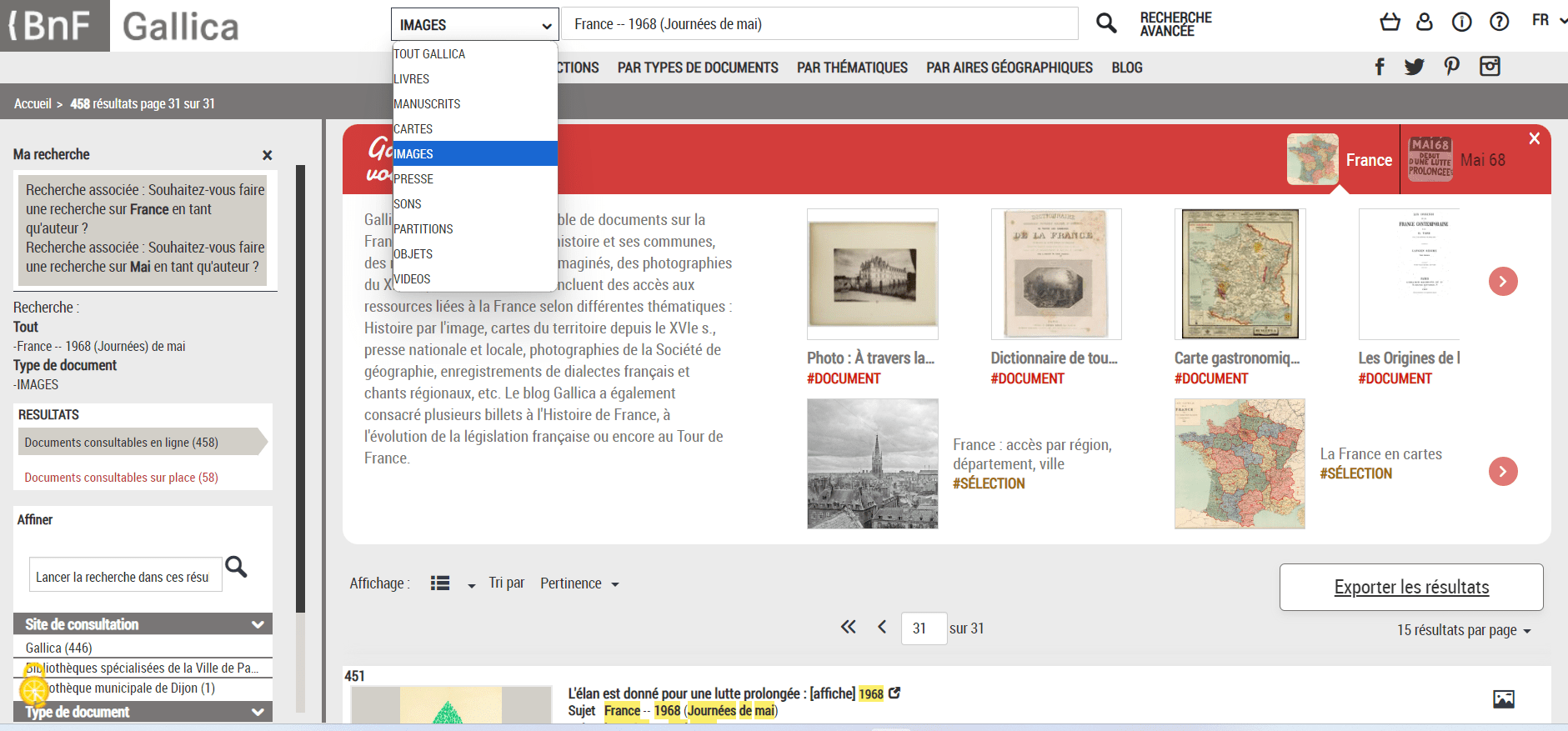
Figure 1. Requête de recherche simple sur Gallica en utilisant le mot-matière et en délimitant les résultats aux images
Pourquoi n’est-il pas possible de partager les fichiers images des affiches dans le cadre de cette leçon ? Cela peut sembler surprenant, vu que les créateurs des affiches ne daignaient pas signer leur œuvre. Mais, concrètement, ces sont les métadonnées de ces documents qui prêtent à la confusion. Le rapport de recherche indique les affiches comme étant dans le domaine public, mais les notices en ligne des reproductions numériques précisent que celles-ci sont seulement consultables en ligne. D’ailleurs, certaines des affiches appartenant à des institutions partenaires ne sont pas téléchargeables du tout - même s’il reste évidemment toujours possible, à des fins de recherche et dans un cadre privé (sans diffusion), d’effectuer des captures d’écran. C’est pourquoi il a semblé préférable d’éviter toute reproduction et partage direct de ces fichiers dans le cadre de la leçon de la part de l’autrice.
Les photos d’Occupy Wall Street sur Flickr
Les mobilisations sociales survenues en septembre 2011 à New York puis propagées au reste des États-Unis et connues sous le nom d’Occupy Wall Street, ont généré une production graphique considérable. Elles comptent aussi parmi les premières documentées sur les réseaux socionumériques. Le jeu de données comprend la liste des URL individuelles des images statiques d’un ensemble de photos collectées sur Flickr. Une première recherche sur l’interface habituelle de Flickr a été effectuée pour définir le périmètre de la collecte. La requête a utilisé la fonctionnalité de recherche avancée pour insérer le mot-clé “occupy wall street” et les restrictions suivantes: “Aucune restriction de droits d’auteur connue” et rechercher dans “Tags” (plutôt que dans “Tout”).
Une fois les résultats vérifiés (environ 350 items sans restrictions de droits contre environ 60 000 au total tous types d’utilisation confondus), la collecte a été lancée à l’aide de l’API de Flickr et en mobilisant à nouveau un script R. Ainsi, les fichiers de 352 photos ont été obtenus accompagnés de fichiers individuels de métadonnées automatiquement générés par Flickr en format JSON. Ces photos sont œuvre de deux photographes dévoués à l’application de licences libres, David Shankbone (États-Unis) et Garry Knight (Royaume-Uni). Celles de David Shankbone sont accessibles aussi via Wikimedia Commons.

Figure 2. Recherche avancée sur Flickr pour repérer des images d’OWS libres de droits
Les photos représentent principalement des personnes vivantes en train de participer aux occupations liées à OWS. Bien que leurs créateurs les aient placées sous licence libre, le partage direct du corpus que nous avons constitué pour la leçon serait une réutilisation dans un but différent de la première diffusion. Pour en faire un usage éthique, le jeu de données consiste en une liste des URL individuelles des images statiques et des métadonnées élémentaires permettant de les contextualiser (identifiant de la publication, identifiant du compte utilisateur du créateur, titre, dimensions des images) que les lecteurs et lectrices peuvent utiliser à volonté pour expérimenter avec Tropy. Il est également possible, en utilisant le script R, de rappeler l’ensemble des fichiers images décrits. Ce jeu de données peut s’avérer utile pour qui serait plus à l’aise à travailler avec des données documentées en anglais. Par ailleurs, les liens des images statiques permettent de travailler avec l’importation directe d’images depuis le web dans Tropy.
Lien vers les fichiers pour obtenir le jeu de données des photos d’OWS sur Flickr.
Les affiches du Printemps érable
La grève étudiante contre la hausse des frais de scolarité déclenchée au printemps 2012 au Québec, aussi appelée Printemps érable, a donné lieu à une production visuelle considérable. Une partie de celle-ci a été rassemblée, dans le cadre d’un travail universitaire, sur un site web qui sert ainsi d’archive non-institutionnelle de la production graphique du mouvement.
Le jeu de données comprend l’ensemble des affiches du Printemps érable hébergées sur le site web Printemps érable archives soit 352 fichiers d’affiches créées à des fins militantes dans le cadre du mouvement étudiant du printemps 2012 au Québec, Canada (connu aussi sous le nom de Printemps érable). Ces affiches constituent par conséquent des sources nativement numériques qui documentent le mouvement.
Lien vers le jeu de données des affiches du Printemps érable déposé sur Zenodo.
Il est donc possible de suivre cette leçon en utilisant un des corpus d’images ci-dessus proposés. Pour qui préfère utiliser ses propres sources, il est possible de commencer avec le fruit d’une journée de travail à un centre d’archives : des centaines de fichiers de photos en forme brute, fraîchement copiés depuis un smartphone vers un disque dur, sans même avoir eu le temps de les renommer. C’est le moment de s’en occuper !
Démarrer avec Tropy
Cette section fournit les informations préalables à la création d’un projet qui permet d’organiser les sources d’un projet de recherche.
Installer Tropy
Tropy est un logiciel multi-plateformes (distributions Linux, Windows, macOS) dont l’installation se fait en local. Pour le moment, il n’existe pas d’application disponible en ligne, sachez donc que votre projet sera hébergé sur le disque dur de votre ordinateur. Il n’est pas non plus possible d’installer Tropy sur un serveur partagé pour travailler à plusieurs de manière synchrone.
Tropy peut être librement téléchargé depuis son site web. Une fois le téléchargement terminé, lancez l’installateur et laissez-vous guider par les instructions. Notre leçon mobilise la version 1.16.1 de Tropy et a été réalisée sur Windows 11.
Les éléments d’un projet dans Tropy
Avant de commencer, il est important de comprendre les éléments de base qui structurent un projet dans Tropy. Ces éléments sont les suivants :
- projet
- objet
- liste
- tag (soit libellé)
De manière sommaire, un projet consiste en un ensemble d’objets qui peuvent être organisés en listes, mais aussi classés selon des libellés qui leur attribuent une caractéristique spéciale.
Le projet est une collection de fichiers images qui représente une recherche localisée sur un sujet: une ébauche de publication, une initiative de crowdsourcing, un mémoire de fin d’études soit tout projet intellectuel susceptible d’englober un ensemble de sources captées en images que nous souhaitons analyser. Techniquement, le projet est le premier point d’entrée dans l’interface de Tropy, pour ensuite accéder aux photos d’archives qui lui correspondent afin de les organiser et d’effectuer de nombreuses opérations (transcription, prise de notes, indexation…) en vue de leur analyse.
Passons à l’objet qui, dans Tropy, est essentiellement la représentation d’une source comme entité : la photo d’un document d’archives, d’un monument, d’une œuvre d’art, d’une affiche… Un objet équivaut à une ou plusieurs photos : par exemple, dans le cas d’un document d’archives de plusieurs pages, nous pouvons avoir des photos distinctes qui correspondent à chaque page. Lorsque nous créons l’objet qui correspond à ce document dans Tropy, nous le verrons, celui-ci englobe les photos de toutes les pages pour compter comme une entité.
Ces objets nous pouvons ensuite les organiser en listes. Par liste, dans Tropy, il faut entendre une série, ou une sous-partie, que nous constituons pour y classer plusieurs objets qui partagent une caractéristique commune. Par exemple, si notre projet porte sur la création artistique d’une certaine période, nous pouvons constituer des listes selon les avant-gardes de la période en question ou selon artiste ou encore en appliquant des critères géographiques…
Enfin, dernier mais non moins important élément de base, le libellé, ou « tag ». Il s’agit de mots-clés libres qui décrivent des caractéristiques distinctives d’un objet et permettent ainsi de le classer. Nous le verrons plus en détail par la suite, les tags sont des moyens d’indexation personnelle des objets que nous créons dans Tropy. Cette indexation peut être thématique (par exemple, le nom d’une personnalité politique qui apparaît dans plusieurs documents du projet) ou fonctionnelle (par exemple, à transcrire, pour les documents du projet dont nous souhaitons insérer une transcription en note). En tout cas, elle doit convenir à son créateur et être systématique et cohérente. Bien indexer less sources au moment de les enregistrer peut parfois être jugé chronophage. En réalité, c’est du temps bien investi et récupéré lors de l’analyse et de la rédaction. L’indexation facilite l’accès, de manière transversale, à des sources qui peuvent faire partie de différentes listes mais être réorganisées suivant une ou plus de caractéristiques communes.
Configurer un projet standard ou avancé
Au moment de créer un projet, il faut préalablement définir s’il est de type standard ou avancé - l’option par défaut étant le projet standard. Il s’agit là d’une fonctionnalité disponible à partir de la version 1.13 de Tropy. Mais de quoi s’agit-il exactement ?
Un projet standard, au moment de l’importation des fichiers des images, crée aussitôt des copies de ces images pour les stocker dans un répertoire spécifique de Tropy. L’avantage dans ce cas est que le projet devient intégralement portable. Par exemple, en le copiant sur une clé USB et en l’important dans un autre environnement de travail que notre ordinateur habituel, nous pouvons le retrouver tel que nous l’avions laissé dans son environnement d’origine, et continuer à travailler dessus sans interruption. L’inconvénient d’un projet standard est cependant qu’il nécessite des machines performantes avec beaucoup de mémoire disponible, car les fichiers images sont des fichiers volumineux.
En revanche, un projet avancé n’effectue pas de copies des images d’origine. Celles-ci ne sont donc pas stockées dans un répertoire intégré au projet, même si nous pouvons toujours les voir via l’interface de Tropy. Ici, comme il le faisait dans ses versions précédentes, Tropy établit des liens, que nous appelons des chemins, vers les répertoires que nous avons initialement choisi comme emplacement pour stocker nos fichiers. Par exemple, cet emplacement peut se trouver sur le disque dur de notre PC dans Documents. L’avantage des projets avancés est qu’ils sont légers, puisqu’ils ne contiennent que les données que nous ajoutons (structure de notre projet, notes, libellés, transcriptions…). En revanche, pour assurer la portabilité d’un projet avancé, il faudra veiller à l’accompagner, dans son nouvel environnement, des répertoires dans lesquels nous avons stocké nos images et d’intervenir pour rétablir les chemins cassés, le cas échéant. Si vous ne souhaitez pas mettre la main dessus ou ne savez pas trop comment s’y prendre, il vaut mieux sélectionner le mode standard, mais n’ayez pas peur de vous expérimenter plus tard.
Pour suivre les étapes suivantes de la leçon, le choix de type de projet n’a pas vraiment d’incidence. En ce qui nous concerne, nous optons pour créer un projet avancé pour éviter d’avoir un projet lourd, mais, encore une fois, le choix vous appartient selon vos propres contraintes et préférences.
Admettons que nous avons créé notre projet, par défaut celui-ci est stocké dans le répertoire Documents et son extension est .TPY. Il est tout à fait possible de sauvegarder un projet Tropy à l’emplacement de notre préférence, que nous choisissons via la boîte de dialogue qui s’ouvre après avoir entré le nom de notre projet et appuyé sur le bouton Create Project.
Paramétrer la langue
Tropy est disponible dans plusieurs langues dont le français. Pour paramétrer la langue à laquelle nous souhaitons rendre disponible l’interface, rendons-nous, à partir du menu principal, à Édition > Préférences > Paramètres. Une fois là, il est possible de sélectionner la langue de notre préférence à partir de la liste déroulante. Attention, la première fois que nous lançons Tropy le menu peut apparaître en anglais. Dans ce cas, suivre Edit > Preferences > Settings > Locale pour définir la langue de préférence.
Créer un projet
Lançons à présent Tropy - comme vous le verrez, nous avons aussitôt accès à une boîte de dialogue et aussi, en haut, au menu principal. La boîte de dialogue nous invite à créer un projet, d’abord en le nommant puis en sélectionnant son type : standard ou avancé - nous avons vu plus haut de quoi il s’agit. Nous pouvons aussi créer notre projet à partir du menu principal : Fichier > Nouveau > Projet. Nous n’allons pas explorer davantage le menu à ce point, sauf si nous souhaitons paramétrer la langue de l’interface.
Créons donc notre projet en lui attribuant le titre de notre préférence.
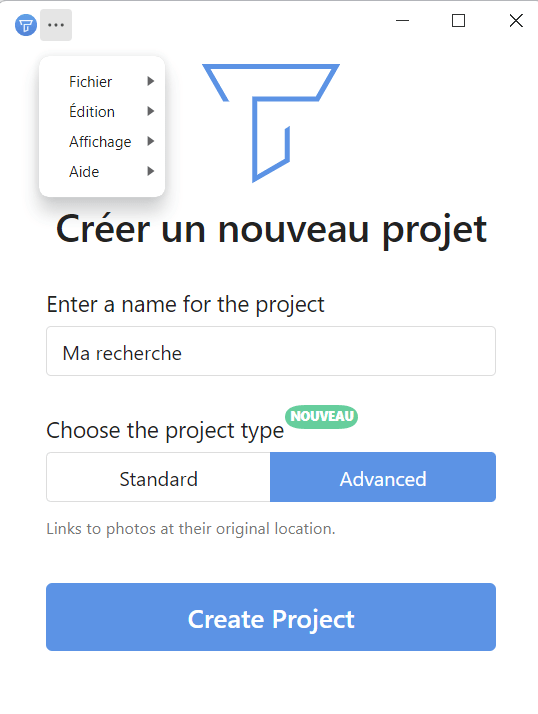
Figure 3. La boîte de dialogue pour créer un projet dans Tropy
Une fois notre projet créé et lancé, nous accédons enfin à l’interface qui permet d’effectuer les opérations globales le concernant : c’est l’interface du projet. L’autre interface principale via laquelle nous travaillerons est celle de l’objet, mais nous n’en sommes pas encore là ! Restons pour le moment à l’interface du projet d’où nous avons accès au menu principal en haut. Elle nous permet aussi d’accéder au menu latéral à gauche qui offre un point supplémentaire d’accès à l’interface du projet, aux listes créées, mais aussi aux dernières importations que nous effectuons au fur et à mesure, tout comme aux tags et aux objets supprimés. Il est maintenant temps d’importer nos sources pour pouvoir explorer davantage les fonctionnalités qui nuos sont offertes !

Figure 4. Vue de l’interface principale de projet de Tropy
Importer et organiser les fichiers images de ses sources
Nous partons du principe que vous avez déjà des photos de vos archives ou que vous avez récupéré les fichiers de l’un des jeux de données que nous fournissons avec la leçon. Vous avez enregistré ces fichiers dans l’emplacement de votre choix sur votre disque dur. Alternativement, vous avez repéré quelques images à importer directement depuis le web - si ce n’est pas le cas, n’hésitez pas à vous servir des liens fournis dans le jeu de données des photos d’Occupy Wall Street.
Importer les fichiers images
Les formats de fichiers que Tropy peut prendre en charge sont les principaux formats qui peuvent abriter des images dont JPG/JPEG, PNG, SVG, TIFF, GIF, PDF. Il s’agit là de formats communément rencontrés dans le cadre de recherches historiques, mais pour consulter la liste complète, merci de se référer à la documentation de Tropy disponible sur son site web.
Il est possible d’importer les fichiers images de deux façons :
- Soit les glisser, un par un ou en les sélectionnant tous, directement dans la zone du milieu du menu, réservée aux objets
- Soit utiliser le menu principal ; pour ce faire, aller à
Fichier>Importer>Photos, pour importer un ou plusieurs fichiers d’images depuis un répertoireFichier>Importer>Dossier, si vous souhaitez importer tout un répertoire de fichiers
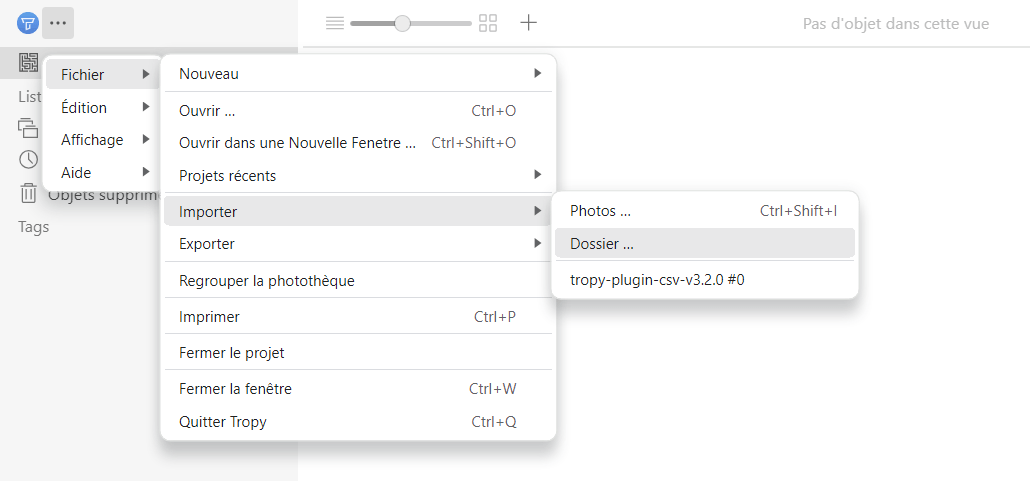
Figure 5. Menu principal d’importation de fichiers dans un projet Tropy
Nous avons testé l’importation des fichiers du jeu de données des affiches du Printemps érable des deux manières ci-dessus évoquées : via Photos, en sélectionnant tous les fichiers à la fois, et via Dossier, qui nous semble plus pratique pour les répertoires volumineux. Les deux ont été aussi bien efficaces. Au passage, Tropy a la possibilité de repérer à ce stade des doublons dans le jeu de données qu’il est possible de ne pas importer (c’était le cas du jeu de données importé pour cette leçon).
Depuis la zone du milieu, nous avons maintenant une vue d’ensemble des objets de notre projet. Un menu spécifique en haut permet de naviguer dans les objets à l’aide d’une barre de recherche à droite. Il est possible d’ajuster la vue en réglant le curseur, qui se trouve en haut à gauche, pour afficher les objets du projet en mode liste ou en mode vignettes, et ce en alternant les échelles, allant d’une vue de l’ensemble à la vue d’un seul objet. Par ailleurs, sélectionner un objet permet de faire afficher, dans le menu latéral à droite, des informations qui lui sont spécifiques : métadonnées de description, tags, le(s) fichier(s) de photo(s) qui se rapportent à cet objet.
À ce stade il n’y a pas autre chose à afficher que le nom du fichier, puisque nous venons d’importer nos fichiers et n’avons pas encore procédé à leur description plus détaillée (soit à la saisie des métadonnées). Nous allons voir cela dans un instant, mais il est important de retenir que, le mieux nous décrivons nos fichiers, le plus les fonctionnalités de recherche offertes par le logiciel deviennent efficaces.

Figure 6. Vue d’ensemble en mode vignettes de fichiers importés dans un projet Tropy
Importer des images depuis une page web
Il est possible d’importer des images statiques qui ont leur propre URL directement depuis une page web dans un projet Tropy. Pour ce faire, il faut se positionner dans l’interface du projet puis glisser l’image sélectionnée depuis le navigateur, en appuyant à gauche de l’URL, vers la zone du milieu de l’interface offrant une vue d’ensemble des objets. Attention, l’importation est différente selon que le type du projet soit standard ou avancé. Si le projet est standard, Tropy effectue aussi une copie de l’image qui est ainsi téléchargée au cours de l’opération et intégrée dans le projet. En revanche, si le projet est en mode avancé, seulement un lien est créé vers l’adresse web de l’image, sans que celle-ci ne soit téléchargée. Dans ce cas, il faut soit double-cliquer sur l’icône de l’objet créé dans notre interface pour accéder, via le web, à l’image d’origine ; soit effectivement la télécharger de son emplacement d’origine pour ensuite l’importer dans le projet.
Enfin, il faut noter que les opérations décrites ci-dessus sont possibles seulement avec les formats d’images statiques mais pas avec les fichiers PDF. Il faudra télécharger ces derniers pour ensuite pouvoir les intégrer dans un projet Tropy. De même, lorsque les images sont accessibles via des pages dynamiques, comme le sont les pages générées via un moteur de recherche, il n’est pas possible de les importer directement dans Tropy. C’est en grande partie le cas d’images auxquelles nous accédons à la suite de recherches dans des bibliothèques numériques. Des corpus fournis avec la leçon, celui des photos d’Occupy Wall Street vous permet d’importer des images de la manière décrite plus haut. Comme bonne pratique, nous conseillons de télécharger et de sauvegarder en local les corpus qui constituent vos données de recherche pour pouvoir ensuite les importer facilement.
Organiser les fichiers images importés
Indépendamment de la manière dont vous avez importé vos photos, maintenant qu’elles sont bien là, promenez-vous à nouveau dans l’interface du projet. Vous pouvez ainsi régler l’affichage de vos photos dans la vue d’ensemble de la manière qui vous convienne le plus (en liste ou vignettes). Vous pouvez aussi vous placer sur un objet : en cliquant droit sur celui-ci, vous avez accès à un menu supplémentaire permettant d’effectuer des opérations au niveau des objets. Au point où vous en êtes, vous pouvez utiliser ce menu pour, par exemple, tourner à gauche ou à droite des images, si cela est nécessaire. Notez que le click droit marche si vous êtes sur Windows ; si vous êtes sur Mac ou une distribution Linux, il faut maintenir la touche Ctrl enfoncée tout en cliquant (gauche) sur l’élément qui vous intéresse - un objet dans ce cas-ci.
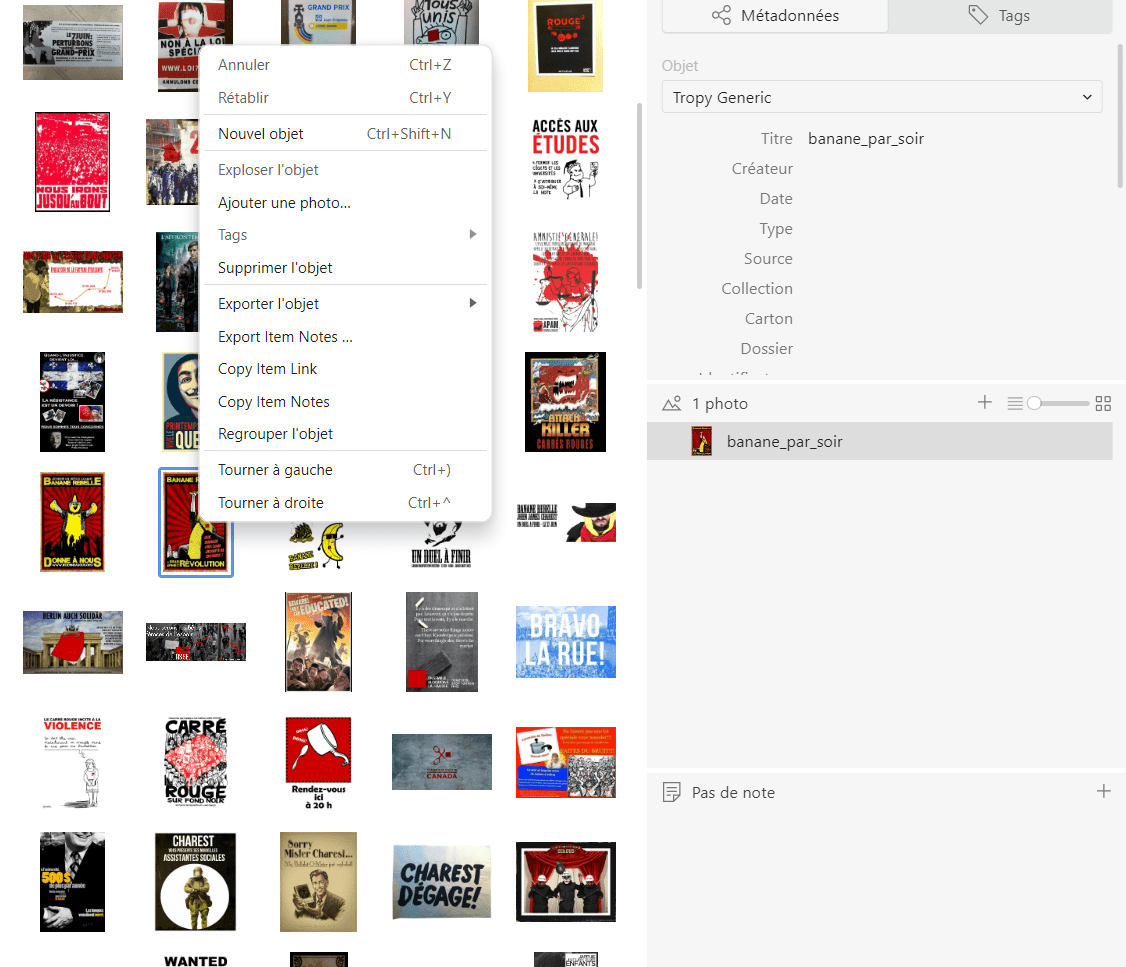
Figure 7. Menu au niveau de l’objet accédé après click droit sur un objet (source) du projet
Fusionner des fichiers images en un seul objet
Pour reproduire les étapes ci-dessous décrites, les fichiers des journaux de tranchées sont fournis et peuvent être téléchargés et utilisés pour créer un projet séparé Tropy.
Il est aussi possible de regrouper plusieurs fichiers de photos en un seul objet en les fusionnant. Pourquoi faire cela ? Le but n’est pas de faire une collection quelconque - pour cela, il existe la fonctionnalité des listes - mais plutôt de relier les parties qui représentent différentes facettes d’une seule source. Il se peut, plus particulièrement, que plusieurs photos se rapportent toutes à la même source primaire sans faire du sens indépendamment l’une de l’autre - sauf pour créer des fichiers orphélins, et, au final, de la pagaille. Les figures ci-dessous illustrent l’exemple de huit photos correspondant aux différentes pages du même numéro d’un journal de tranchées daté de février 1915 - le numéro 3 de L’écho des marmites, conservé et numérisé par La Contemporaine. Dans un projet Tropy, ces photos ne constituent pas des objets distincts, puisque nous savons à présent qu’un objet est égal à une source primaire. Nous pouvons donc regrouper ces photos pour qu’elles correspondent à une seule source, le numéro spécifique du journal.
Pour ce faire, il faut d’abord identifier la photo qui représente la première page, en tout cas la partie d’entrée vers la source. En l’occurrence il s’agit de la une du journal, mais dans d’autres projets cela pourrait être la première page d’une correspondance, la couverture d’un livre… Après donc avoir identifié ce fichier image principal, il existe deux manières de faire.
- La première consiste à sélectionner les photos que nous souhaitons fusionner avec la photo principale (à ce stade, nous n’avons pas à sélectionner cette dernière, il suffit de l’avoir identifiée). Ensuite, il suffit de glisser les fichiers sélectionnés sur le fichier image principal pour créer un objet Tropy fusionné. S’il existe plusieurs fichiers à fusionner, attention à sélectionner de la fin vers le début soit à l’ordre inverse d’une pagination, c’est-à-dire d’abord le fichier qui représente la dernière page puis celui qui représente l’avant dernière et ainsi de suite, pour glisser l’ensemble vers le fichier image principal. Cela garantit le bon ordre de la pagination de la source représentée.
- L’autre manière de faire consiste à sélectionner tous les fichiers images à fusionner y compris le fichier image principal - via la manipulation
Ctrl+ cliquer pour choisir les fichiers). Ensuite, il faut accéder au menu au niveau de l’objet en cliquant droit (ou l’équivalent pour Mac ou distributions Linux) et choisirFusionner les objets sélectionnés. Attention, pour s’assurer que les fichiers fusionnés respectent l’ordre de la pagination de l’original, la sélection cette fois-ci doit commencer par le fichier qui représente la première page du document puis continuer avec ceux qui suivent dans l’ordre souhaité. L’exemple qu’illustrent les figures ci-dessous a suivi cette manière de faire (pour éviter des problèmes de confusion dans l’ordre, bien que le nommage embarqué lors du téléchargement de ces fichiers depuis Argonnaute ait été maintenu, des préfixes-chiffres ont été ajoutés pour indiquer l’ordre des pages).
Si un objet émane d’une fusion de fichiers, c’est le premier fichier image qui hérite aux autres une série de caractéristiques, dont les métadonnées sont le plus important. Des opérations telle la prise de notes ou la transcription peuvent toujours d’effectuer au niveau de chaque fichier image.
Un objet fusionné peut toujours être décomposé - via le menu au niveau de l’objet, en choisissant Exploser l'objet.
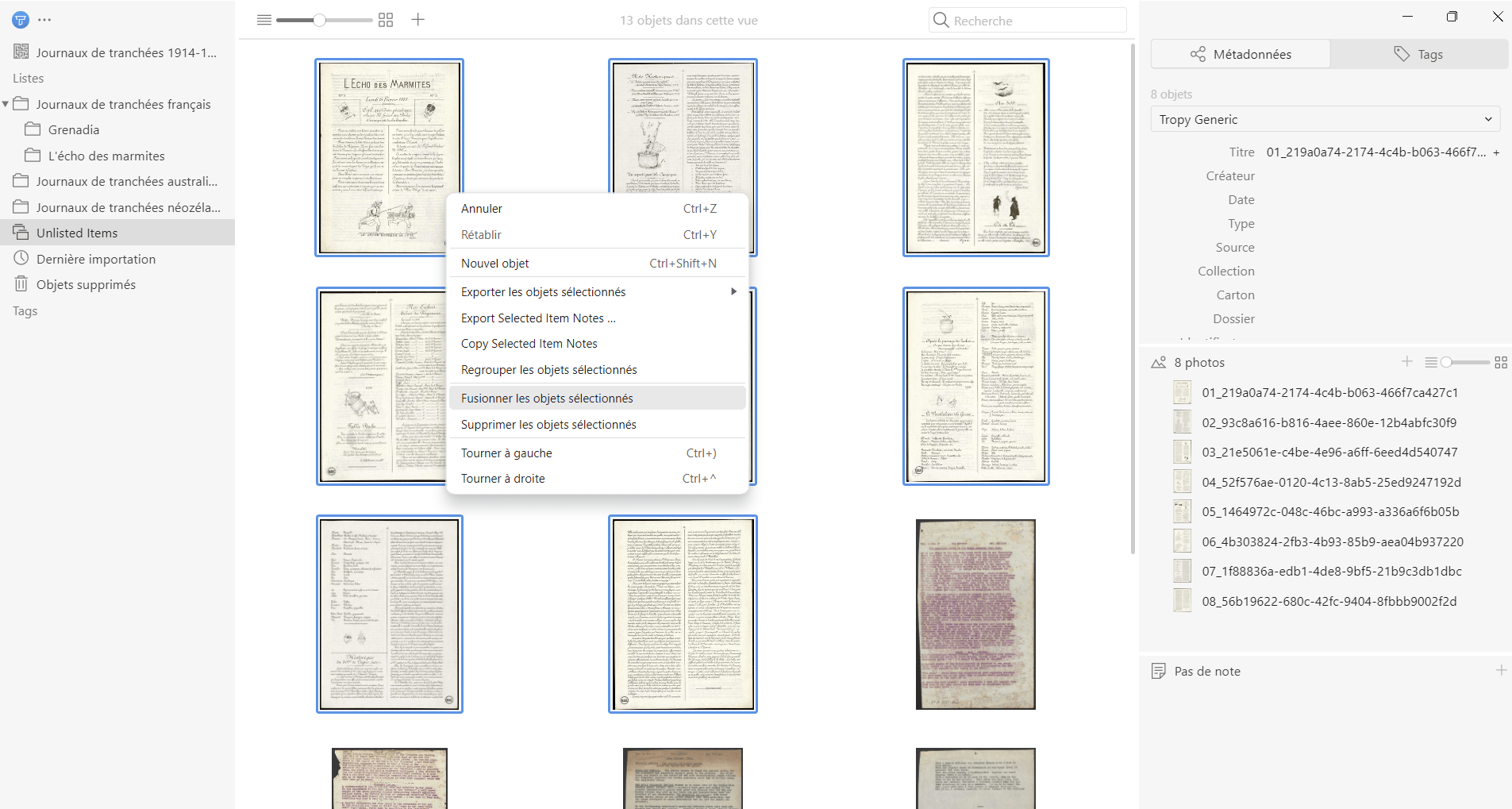
Figure 8. Sélection des fichiers représentant les pages du numéro 3 du journal L’écho des marmites pour les fusionner en un seul objet Tropy. Les métadonnées saisies décriront alors le numéro et se rapporteront à tous les fichiers à l’identique. Source des fichiers numérisés: Argonnaute, La Contemporaine. Licence Ouverte Etalab
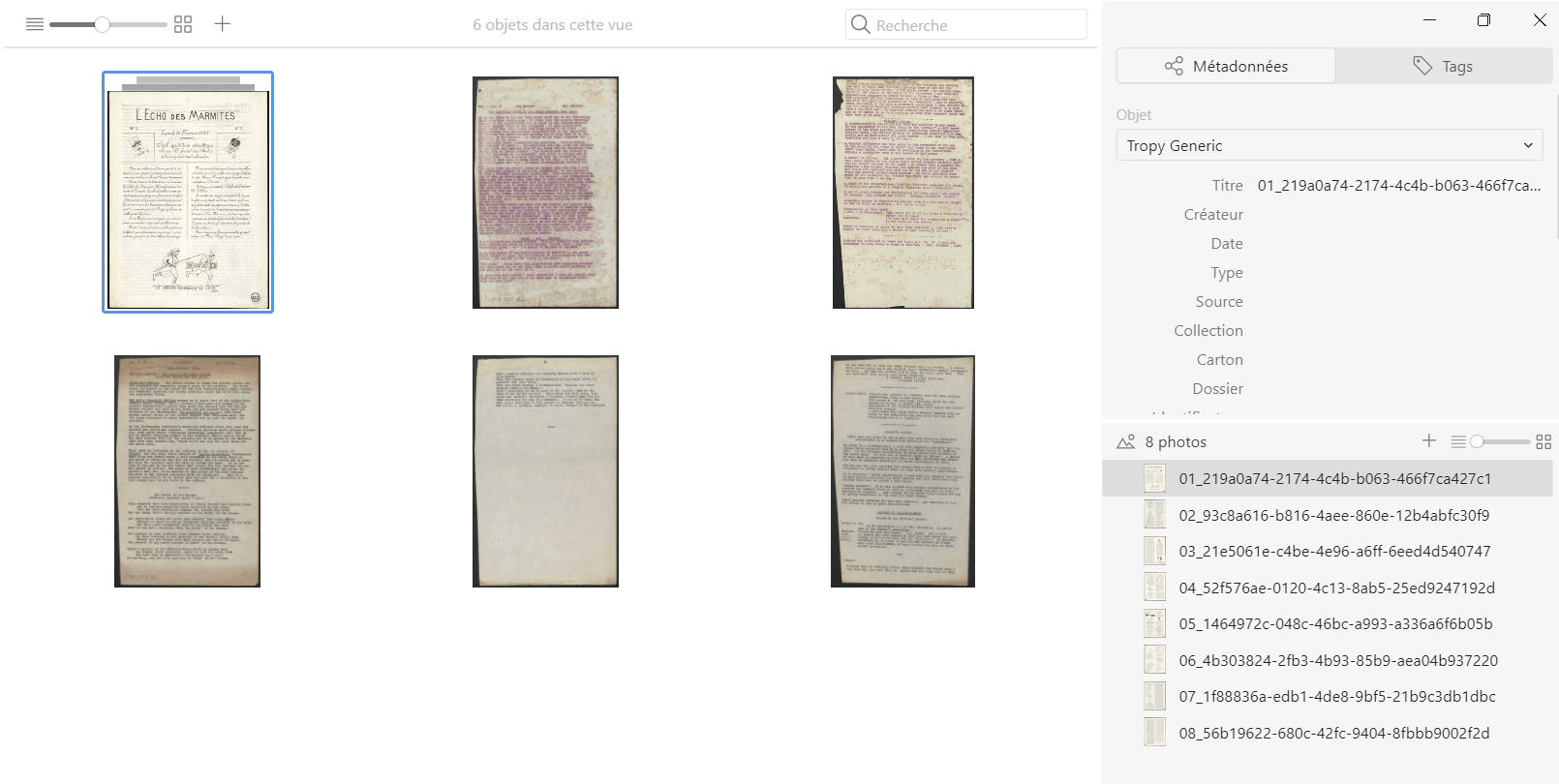
Figure 9. Cet objet Tropy correspond à un numéro du journal des tranchées L’écho des marmites. Il a émané de la fusion du fichier qui représente la une avec les sept fichiers qui représentent une page du journal chaque. Source des fichiers numérisés: Argonnaute, La Contemporaine. Licence Ouverte Etalab
Organiser les objets en listes
Les listes permettent de classer les objets (les photos des sources primaires) de manière thématique, chronologique ou selon toute autre catégorisation qui puisse être signifiante selon la problématique d’une recherche. Une classification cohérente des sources peut faciliter considérablement leur analyse puis leur rappel lors de la phase de l’écriture. Pour créer une liste, aller au menu principal de Tropy et sélectionner Fichier > Nouveau > Liste. Cela peut se faire aussi depuis le menu latéral situé à gauche de l’interface du projet en cliquant droit (ou la manipulation équivalente sur Mac et distributions Linux) sur cette zone-ci et en choisissant Nouvelle liste. Ensuite, l’icône d’un répertoire apparaît dans le menu latéral de gauche suivi d’une boîte qu’il faut renseigner avec le nom de la liste. Nous intégrons les objets dans une liste ou plusieurs en les glissant, depuis l’interface principale du projet, sur le nom de la liste visée. La suppression d’une liste n’a pas d’incidence sur les objets qui, eux, continuent d’exister dans le projet.
Par ailleurs, il est tout à fait possible de créer des listes imbriquées pour organiser une arborescence.
La figure ci-dessous illustre comment classer un fichier dans une liste. En outre, il est possible d’y voir un exemple d’arborescence de listes thématiques (qui reproduisent celle de l’archive conservant les sources).
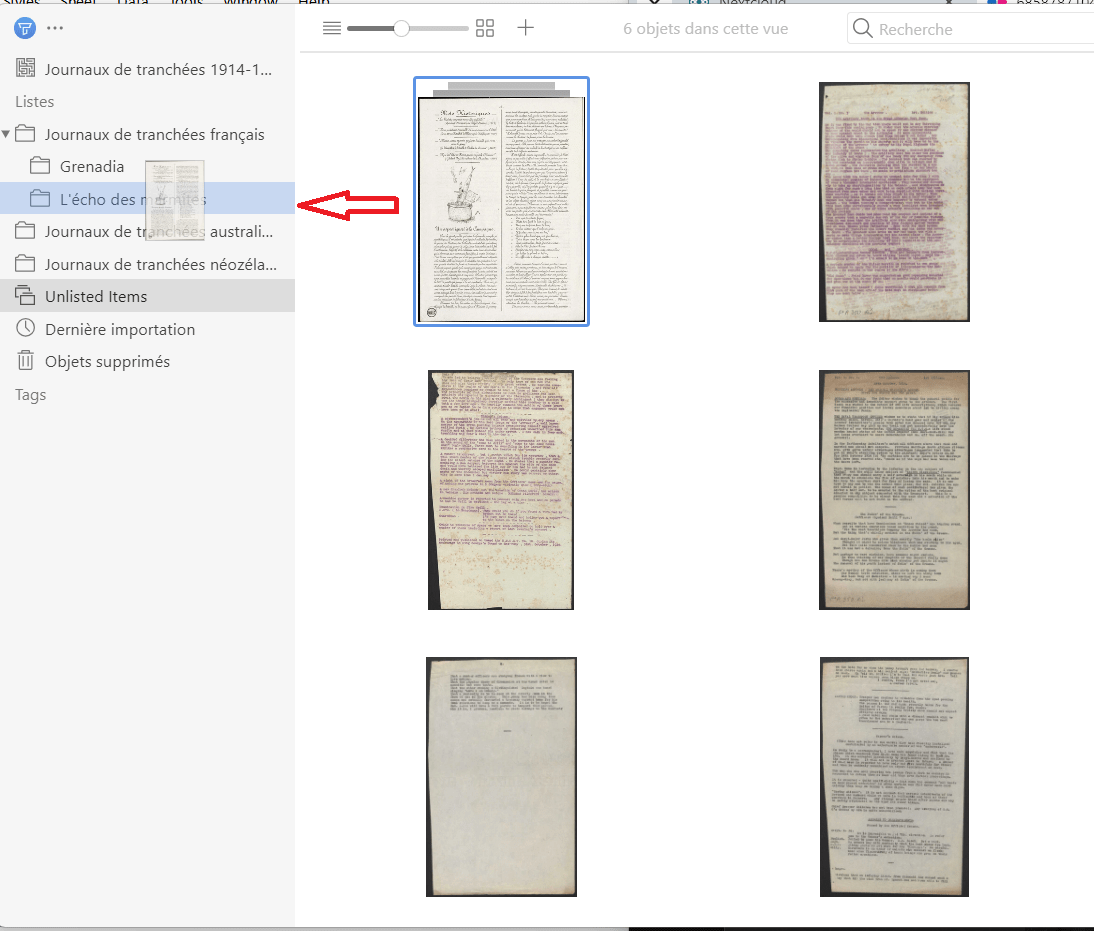
Figure 10. Cet objet Tropy correspond à un numéro du journal des tranchées L’écho des marmites. L’objet est sélectionné et en cours d’être glissé vers une liste thématique pour y être classé. Source des fichiers: Argonnaute, La Contemporaine
Décrire ses sources
Au moment d’importer les fichiers images des sources primaires dans un projet Tropy, il est judicieux de les décrire avec des informations qui sont communément appelées métadonnées. Il s’agit de choses que les historiens et les historiennes ont l’habitude de retenir pour leurs sources : le titre d’un document, un nom d’auteur, une date de création… Les métadonnées sont des informations qui décrivent d’autres données - dans notre cas les sources historiques et qui deviennent signifiantes dans un système défini. C’est tout ce qu’il faut retenir sur ce terme intimidant pour découvrir le reste dans la pratique. Tropy offre pour cela un formulaire spécifique, accessible dans la zone de la partie droite de l’interface principale et en tout cas actif en cliquant sur un objet.
L’opération de saisie systématique de ces informations descriptives relie la photo à la source et permet ensuite d’y accéder facilement et rapidement autant de fois que souhaité. Par ailleurs, elle est importante pour analyser correctement la source puisqu’elle facilité sa contextualisation et vérification. Enfin, l’opération de description des sources les rend citables dans un travail de recherche scientifique. En plus de ce type d’information au final très classique, Tropy permet de saisir des informations importantes pour les environnements numériques (bases de données, sites web, dépôts de données…) dans lesquels les sources peuvent désormais circuler, dont les droits d’utilisation ou encore des informations techniques sur les fichiers des images.
Attribuer des métadonnées par lot
Il est possible de décrire chaque objet à l’unité, en se rendant à son formulaire de métadonnées depuis le menu d’objet. Cependant, si nos objets sont homogènes, par exemple losque nous importons un ensemble de photos de documents en provenance de la même archive, carton ou autre, ils peuvent partager un certain nombre de métadonnées communes. Dans ce cas, nous pouvons attribuer les métadonnées communes par lot, ce qui peut faire gagner du temps lorsque l’importation comprend un grand nombre de photos. Pour ensuite aller renseigner, au niveau d’objet, des métadonnées plus spécifiques à l’unité. En vérité, dans la plupart de cas, nous combinons l’attribution de métadonnées de manière globale au travail plus personnalisé pour bien décrire chaque objet.
Une bonne pratique pour attribuer des métadonnées communes à un lot de photos est de se positionner au niveau de la dernière importation. Pour cela, il suffit d’aller placer son curseur sur Dernière importation accessible depuis le menu à gauche de l’interface du projet. Pourquoi faire cela ? Au fil d’un projet, plusieurs importations de fichiers d’images peuvent se succéder de manière différée, selon la temporalité d’une recherche. Si des métadonnées sont attribuées après chaque nouvelle importation, d’abord c’est là un gage contre le risque de finir avec des photos insufisamment décrites et difficiles à exploiter pour l’analyse. Mais cela préserve aussi les anciennes couches du projet de modifications accidentelles et non-intentionnelles qui peuvent corrompre le projet.
Pour prendre l’exemple du corpus d’affiches du Printemps érable, celui-ci se compose de plus de trois cents objets. La figure ci-dessous représente le formulaire de métadonnées saisies pour une affiche selon le modèle générique fourni par Tropy. Pour celle-ci, les champs Type, Source, Droits ont été remplis en effectuant une description par lot pour l’ensemble des objets puisque ces caractéristiques étaient communes à tous. Seul le champ Créateur a été rempli manuellement par nos soins, en allant au niveau du menu objet pour travailler plus minutieusement. Le reste des champs (titre, date) s’est rempli automatiquement de métadonnées embarquées au moment de l’importation des fichiers dans Tropy. Attention, tant le nombre que la qualité des métadonnées embarquées peut varier et dépend beucoup de la qualité de description des fichiers d’origine (dans le cas que nous décrivons, nous avons eu de la chance !). A minima les métadonnées embarquées sont toujours présentes au niveau du formulaire Tropy photo, qui décrit tecnhiquement le fichier image, et au niveau du titre dans le formulaire de description de la source.
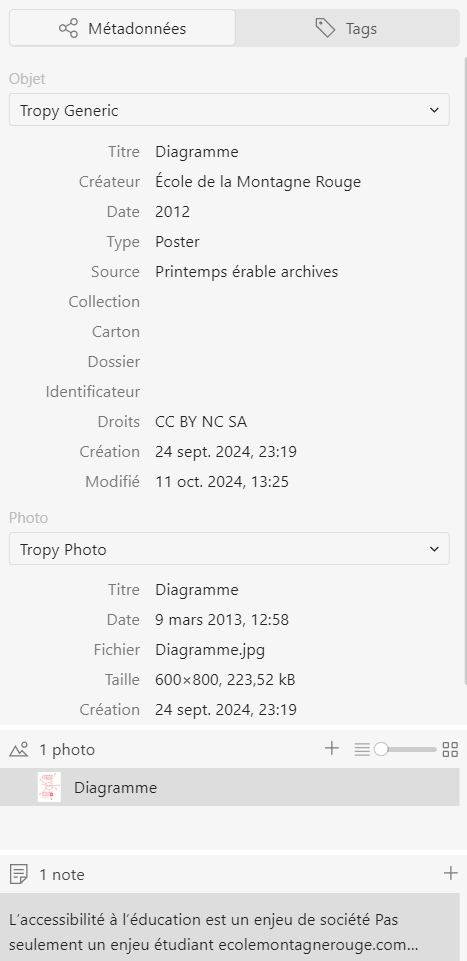
Figure 11. Description d’une affiche du Printemps érable québécois en utilisant le modèle générique de Tropy
Voyons donc comment faire pour attribuer de manière groupée des métadonnées. Depuis l’interface principale du projet, nous nous plaçons au niveau de la zone du milieu avec la vue d’ensemble des objets que nous avons importés. Nous les sélectionnons tous. Ensuite, nous plaçons le curseur au formulaire qui s’affiche dans la partie droite de l’interface sous l’onglet Métadonnées. Nous pouvons utiliser les modèles générique ou correspondance de Tropy qui sont efficaces pour la description de la plupart des sources mobilisées dans les recherches en histoire ou un modèle personnalisé (la démonstration ci-dessous mobilise Tropy Generic). Nous avons identifié au préalable les informations communes à tous les objets de notre corpus : la source, qui est le site web d’où les fichiers images ont été collectés, le type de la création visuelle (affiche), et les droits d’utilisation, où nous respectons la licence déclarée sur le site web d’origine. Nous n’avons plus qu’à renseigner ces champs pour que les métadonnées soient appliquées à tous les objets sélectionnés. De la même manière il est aussi possible d’attribuer des tags pour indexer les objets de manière globale.
Attribuer des métadonnées par objet
Nous allons maintenant travailler au niveau de l’objet. Nous venons d’attribuer massivement des métadonnées qui sont communes à tous nos objets ; à présent, nous souhaitons renseigner plus de métadonnées qui peuvent être spécifiques à un objet, comme par ex. un auteur. Nous pouvons le faire à partir de l’interface du projet, qui offre accès au formulaire de description de l’objet dans sa partie droite, que nous connaissons déjà. Mais nous pouvons aussi explorer à l’occasion la partie de l’interface dédiée à l’objet. Découvrons enfin cette dernière à laquelle il est possible d’accéder en double-cliquant sur l’objet de notre prédilection à partir de la liste ou de sa vignette.
Une fois là, nous pouvons renseigner les champs pertinents à l’aide de la boîte de dialogue en haut à gauche, onglet Métadonnées. Si nous le souhaitons, nous pouvons d’ores et déjà indexer nos objets en insérant des tags pertinents à partir de la boîte de dialogue en haut à gauche, onglet Tags, à droite de celui des métadonnées, ou retourner pour le faire au moment de l’analyse.
Personnaliser le modèle de saisie des métadonnées
Tropy fournit trois principaux modèles de saisie de métadonnées : générique (Tropy Generic), description de correspondance (Tropy Correspondence) et de type Dublin Core. Il est possible de les inspecter depuis le menu déroulant du formulaire au point où le titre du modèle est indiqué pour explorer davantage les champs à remplir. Les deux premiers modèles ci-dessus évoqués conviennent à la description de la plupart des sources historiques. Le troisième reproduit un format simple du standard de métadonnées Dublin Core, largement utilisé pour décrire des collections patrimoniales dans des bibliothèques et archives numériques.
Il existe aussi deux modèles supplémentaires dont l’un est destiné à abriter les informations techniques embarquées des fichiers images (Tropy Photo) et l’autre à fournir les métadonnées des sélections qui peuvent être faites à partir d’un fichier image d’un projet, métadonnées qui sont hérités de l’objet dont la sélection émane. Il est rare d’avoir à intervenir sur ce type de modèles.
Mais il est tout à fait envisageable de tailler un modèle sur mesure pour décrire un type spécifique de sources. Voici la démarche à suivre.
Pour personnaliser un modèle de saisie de métadonnées dans Tropy, nul besoin de tout construire à nouveau de fond en comble. Il vaut mieux rester dans l’esprit, ne serait-ce large, des champs déjà fournis dans les modèles générique ou spécifique aux correspondances qui sont intégrés à Tropy, quitte à apporter des adaptations pour renommer ou multiplier / réduire les champs.
À partir du menu principal, aller à Édition > Préférences > Modèle de saisie. Dans le menu déroulant qui s’affiche, choisir puis dupliquer un modèle existant (Generic ou Correspondence) pour servir de base pour créer le nouveau modèle. Si, par exemple, nous souhaitons construire un modèle de saisie spécifique aux correspondances diplomatiques, il vaut mieux partir sur la base du modèle Tropy Correspondence. Si, au contraire, nous souhaitons créer un modèle spécifique aux affiches, il est préférable de dupliquer Tropy Generic qui correspond mieux à la source. Après avoir dupliqué l’original, nommer le modèle créé (par exemple, Correspondance diplomatique ou Affiche ou autre, selon l’objet d’une recherche donnée).
Admettons que je souhaite créer un modèle de saisie spécifique aux correspondances diplomatiques pour le personnaliser de la manière qui suit, comparé au Tropy Correspondence existant :
- Renommer le champ
PublicenDestinataire - Disposer d’un champ
Lieu de créationet d’un champLieu de destinationpour saisir l’endroit géographique de production et de réception de la correspondance - Dans le champ
Typeéliminer l’affichage par défaut de Correspondance pour pouvoir spécifier davantage les types de correspondances que je rencontre dans ma recherche: télégramme, note diplomatique, mémorandum, lettre…
Comme suggéré plus haut, je sélectionne le modèle Tropy Correspondence et je le duplique à l’aide de l’icône à droite du titre du modèle de saisie. Ensuite, je nomme mon modèle : Correspondance diplomatique-test et j’adapte, si je le souhaite, le nom de créateur du modèle et sa description. Le plus important est ce qui suit : des champs qui existent déjà dans le modèle que j’ai copié, nommés ici Propriétés, je fais attention de garder ceux qui me conviennent sans trop de modifications, si possible. De cette manière, je gagne du temps et je suis un modèle conforme à un standard reconnu (les modèles de Tropy s’appuient sur Dublin Core). Si besoin, il existe la possibilité de renommer les champs existants à partir de Label et j’en profite pour insérer ainsi le terme Destinataire qui viendra replacer l’intitulé du champ Public (sans toucher à la propriété, qui essentiellement exprime ce que je cherche). Par ailleurs, parcourir les propriétés qui sont dejà là me permet de supprimer Correspondence en tant que valeur par défaut de la propriété Type. Il ne me reste plus que d’ajouter deux nouveaux champs dans mon formulaire de saisie pour les lieux que je souhaite pouvoir saisir. Il faut donc insérer deux nouvelles propriétés.
Les champs que je souhaite insérer dans mon modèle de saisie sont destinés à recueillir des données géographiques concernant le lieu de création et le lieu de réception de la correspondance. Je vais donc placer ces champs à proximité des champs qui informent sur le créateur et sur le destinataire respectivement. Je me place donc sur la propriété Créateur et à l’aide de la petite icône du symbole ajouter (+) à droite de cette propriété, j’ouvre la zone d’une nouvelle propriété juste en dessous. Je ne souhaite pas que mon approche soit idiosyncratique, je souhaite aligner les nouvelles métadonnées à celles qui existent déjà dans la structure du modèle. Comme Tropy utilise Dublin Core, je me dirige aux ressources disponibles en ligne pour voir comment la propriété spatiale est exprimée de manière plus normalisée. C’est donc la propriété Couverture (qui existe déjà dans le modèle mais je soujaite affiner davantage) qui est valable aussi pour déclarer entre autre des informations spatiales. Pour nommer ma propriété, je vais au niveau du menu déroulant qui liste les propriétés disponibles pour chercher celle qui me semble être la bonne, et je choisis Couverture spatiale dcterms: spatial. Comme label d’affichage, j’opte pour Lieu de création. Je crée de la même manière, sous le destinataire, une propriété du même type avec cette fois le label Lieu de destination. Mon formulaire personnalisé est prêt !
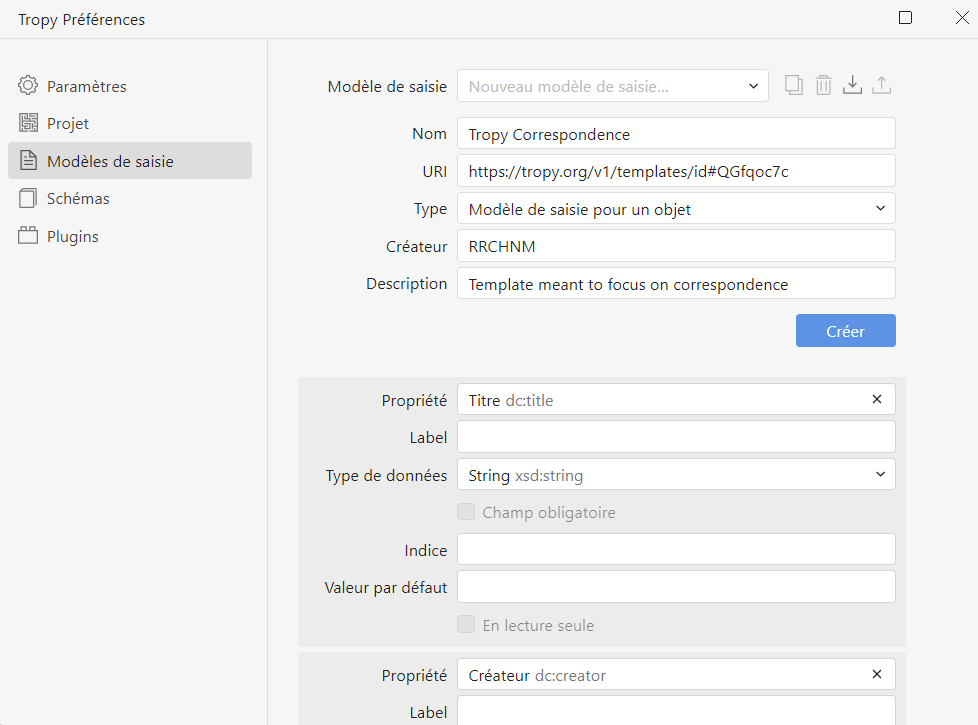
Figure 12. Modèle de saisie Tropy Correspondence qui vient d’être dupliqué afin d’être personnalisé avant d’intégrer de nouveaux champs
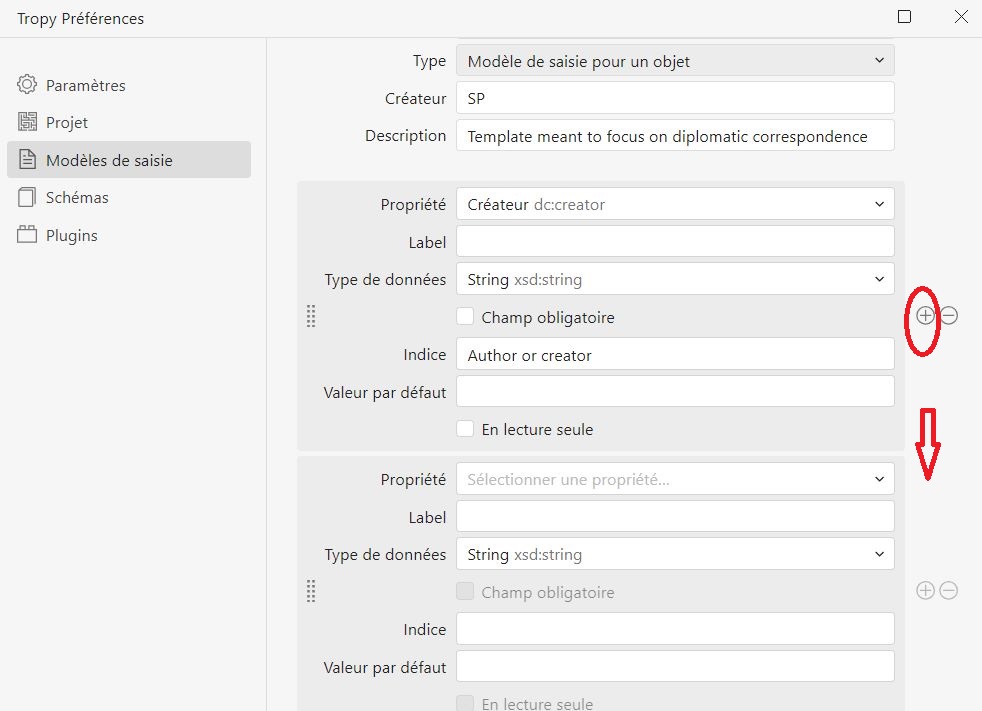
Figure 13. Modèle de saisie en cours de personnalisation avec création d’une nouvelle propriété
Opérations au niveau de l’objet
Les opérations ci-dessus décrites se placent dans la temporalité de l’importation des nos fichiers. Lorsque nous en sommes à travailler de plus près avec nos sources, nous avons la possibilité d’effectuer des opérations plus localisées pour préparer leur analyse.
Opérations techniques
Tropy offre des fonctionnalités élémentaires pour améliorer la qualité des photos des sources (régler la luminosité, le contraste, etc.) en se servant du menu qui se trouve en haut de la zone où s’affiche l’image. Il est possible aussi de zoomer sur une image pour mieux lire ou observer, d’inverser les couleurs pour, par exemple, lire plus facilement des microfilms. Ou encore, nous pouvons sélectionner une partie de l’image qui nous intéresse particulièrement et sauvegarder cette sélection, qui reste accessible depuis le menu latéral à gauche, pour y revenir aussi souvent que nécessaire. En outre, une sélection peut être sauvegardée en tant qu’image autonome avec ses propres métadonnées. Cela est possible en cliquant droit sur le nom de la sélection, depuis la zone du menu latéral gauche où elle apparaît, et choisir Exporter la photo dans le menu qui apparaît.
Indexer
Ensuite, nous avons la possibilité d’indexer le contenu de l’objet - de nos sources ! - en ajoutant des tags. Les tags permettent de classer les contenus de nos sources de manière transversale à travers les listes. Ils offrent un moyen très utile pour obtenir un accès latéral à de nos sources selon une thématique spécifique, soit les croiser de manière élémentaire, ce qui facilite largement la rédaction. Il vaut mieux réfléchir en amont sur un système pertinent de mots-clés, selon la nature d’une recherche et sa problématique, et d’établir une liste à utiliser systématiquement. Cette liste peut bien sûr s’étendre au fil d’une recherche, elle permet néanmoins de se fixer sur des termes stables en évitant des formes différentes et des incohérences qui pourraient rendre finalement l’indexation moins efficace.
Transcrire et prendre des notes
Au dessous de la zone de l’image de l’objet, un éditeur de texte permet la prise de notes. Il est possible de créer autant de notes que souhaité, celles-ci apparaissent ensuite sous forme de liste tout en bas à gauche dans la zone du menu objet. La transcription du contenu d’une image, si celle-ci représente un texte, est aussi possible à faire sous forme de note. Tropy ne dispose pas de logiciel de reconnaissance optique de caractères intégré, par conséquent l’exportation automatique de texte à partir des images du projet n’est pas possible.
Si l’objet Tropy a émané d’une fusion de plusieurs fichiers images, les notes peuvent néanmoins s’insérer séparément pour chaque fichier. Les notes sont exportables soit via un export global du projet Tropy soit séparément en cliquant droit dessus et en choisissant de les exporter dans le menu qui s’affiche.

Figure 14. Interface d’objet d’une affiche du Printemps érable avec les métadonnées renseignées et transcription du contenu en note
Figure 15. Onglet de tags de l’interface d’objet d’une affiche du Printemps érable
Extensions d’un projet Tropy
Il est possible d’exporter un projet Tropy à l’aide du menu principal en format JSON-LD ou PDF.
Par ailleurs, une série de plugins sont disponibles à l’installation à l’aide du menu des préférences, ce qui permet d’exporter un projet aussi en format CSV. Si ce n’est pas l’objet de cette leçon, il mérite néanmoins d’évoquer la possibilité d’installer un plugin Omeka S qui permet d’exporter un projet pour le publier à l’aide d’un site web Omeka. Si nécessaire de se familiariser avec le dispositif Omeka, Programming Historian en français propose une leçon d’initiation.
Bibliographie
Les références bibliographiques rassemblées dans cette section sont principalement en français.
Généralités
Mourlon-Druol, Emmanuel. « Déstructuration et restructuration de l’archive à l’ère numérique ». Billet de blog. Site web d’Emmanuel Mourlon-Druol https://www.e-mourlon-druol.com/. 7 novembre 2019. URL: https://www.e-mourlon-druol.com/destructuration-et-restructuration-de-larchive-a-lere-numerique/, date de consultation 15 août 2024.
Gandanger, Aliénor et Valentine Gandanger. « Gazengel - Ooooh Tropy ! ». Site web Luxembourg Centre for Contemporary and Digital History (C²DH). 22 février 2024 https://www.uni.lu/c2dh-fr/news/gazengel-ooooh-tropy/
Denoyelle, Martine et Johanna Daniel. Guide pratique pour la recherche et la réutilisation des images d’œuvres d’art 2021. Institut national d’histoire de l’art. https://hal.science/hal-03267948
Tutoriels et ressources éducatives
Arènes, Cécile, Meriç Akdogan, & Aurélien Moisan. Tropy , un outil pour gérer les corpus iconographiques. Love Data Week Sorbonne Université. Zenodo. 17 février 2023 https://doi.org/10.5281/zenodo.7656554
Gérer ses photos de recherche avec Tropy. Tutoriel de l’atelier de formation de la Bibliothèque universitaire de l’université Rennes 2. Date de dernière mise à jour: 18 juillet 2024. https://tutos.bu.univ-rennes2.fr/c.php?g=702342
Laillier, Benjamin. Tutoriel Tropy (version 4), août 2019 http://doi.org/10.5281/zenodo.3381981
Valmalle, Delphine. « Utiliser Tropy pour la gestion de ses photos d’archives ». YouTube, Geneatech, 22 février 2021, https://youtu.be/AiPqbdwP67E
Notes de fin
-
Ministère de la Culture, Département des études, de la prospective, des statistiques et de la documentation (DEPS). « Chiffres clés. Statistiques de la culture et de la communication 2022 », p. 177-178. URL. ↩
-
Frédéric Clavert, « Introduction » in Frédéric Clavert & Caroline Muller (dir.), Le goût de l’archive numérique, 2017, https://gout-numerique.net/. ↩
-
Arlette Farge, Le goût de l’archive, Paris, Éditions du Seuil, 1989, 10. ↩
-
Sean Takats, « Tropy », billet de blog, Quintessence of Ham, 26 octobre 2017, http://quintessenceofham.org/2017/10/26/tropy. Date de consultation 1er septembre 2023. ↩