This is the draft website for Programming Historian lessons under review. Do not link to these pages.
For the published site, go to https://programminghistorian.org
Contenidos
Contenidos
- Contenidos
- Objetivos
- Introducción a la lección
- Elementos básicos del análisis de redes sociales
- Cómo llevar a cabo el análisis de redes de un texto teatral
- 1. Creación del corpus de análisis
- 2. Conseguir los datos
- 3. Visualización y análisis de grafos con Gephi
- 4. Interpretación de los resultados
- Recapitulación final
- Notas
- Referencias
Objetivos
- Conocer los elementos básicos del análisis de redes sociales y de la teoría de grafos en su aplicación a la literatura
- Aprender a extraer y estructurar los datos necesarios para llevar a cabo un análisis de redes sociales de un texto teatral
- Introducirse en el programa Gephi especializado en visualización y análisis de redes
Introducción a la lección
Dice Miguel Escobar Varela en su reciente libro Theater as Data (2021) que el teatro depende de relaciones (p. 94). Las relaciones entre intérpretes y público dan lugar al hecho teatral como acto comunicativo, las relaciones entre los distintos agentes de producción dan lugar al teatro como espectáculo artístico (directores y directoras, figurinistas, escenógrafos y escenógrafas, etc.) y las relaciones entre los personajes configuran la acción y el drama en su sentido literario. Todas estas relaciones (las ficcionales y las que se dan en espacios de colaboración artística) pueden ser modeladas, representadas y analizadas en forma de red o de grafo.
En esta lección trabajaremos las relaciones entre los personajes de los textos teatrales, las cuales, como planteó Franco Moretti (2011), nos sirven para representar y estudiar la estructura interna del drama a través de su sistema de personajes, capturando en una red lo que en el teatro siempre ocurre en el presente del escenario pero que termina desapareciendo en el pasado. Moretti habló de este proceso como la transformación del tiempo en espacio.
Para poder estudiar así las relaciones entre personajes nos serviremos del análisis de redes sociales (ARS), un campo de estudio interdisciplinario que toma elementos de la sociología, la psicología, la estadística, las matemáticas y las ciencias computacionales[^1]. Gracias al análisis de redes podemos abstraer y representar cualquier sistema formado por elementos relacionados, y también estudiarlo aplicando conceptos y medidas de la teoría de grafos. La informática, la física, la biología o la sociología son disciplinas que tradicionalmente han identificado en sus campos de investigación sistemas susceptibles de estudiarse a través de redes, y más recientemente también lo han hecho las humanidades, especialmente la historia[^2] y los estudios literarios. Del interés de la historia por el análisis de redes dan cuenta las lecciones de Programming Historian Análisis de redes temporal en R o De la hermenéutica a las redes de datos: Extracción de datos y visualización de redes en fuentes históricas; y los estudios literarios (en mayor medida la crítica literaria) han venido utilizado el análisis de redes para el estudio de los sistemas de personajes, de las redes de producción literaria, para representar los resultados del análisis estilométricos de autoría, etc[^3].
El análisis de redes sociales es para la crítica literaria una metodología de distant reading (o lectura distante) en términos de Moretti (2013) o de macroanlysis si preferimos el conceto de Matthew L. Jockers (2013). Es decir, nos permite estudiar grandes cantidades de textos a través de sus formas, relaciones, estructuras y modelos (Moretti, 2005, p. 1), cambiando el foco de atención de las características individuales a las tendencias o patrones de repetidas en un corpus (Jockers, 2013, p. 24). Más recientemente, Escobar Varela (2021) ha investigado las posibilidades de estudiar el teatro a través de datos como parte de lo que denomina computational theater research (p. 13), dedicando el Capítulo 5 de su libro al análisis de redes. Este concepto, computational theater research refiere a los estudios teatrales computacionales en su sentido más amplio, incluyendo los enfoques escénicos además de los literarios. Desde un enfoque puramente textual se está conformando un área dentro de los Computational Literary Studies (CLS) especializada en teatro llamada Computational Drama Analysis, en donde se integra el análisis de redes sociales junto a otras metodologías cuantitativas y computacionales, como la estilometría, el análisis de sentimientos o el modelado de tópicos[^4].
Elementos básicos del análisis de redes sociales
Antes de comenzar, hay algunos elementos y conceptos del ARS que debemos conocer:
Una red o grafo (son términos sinónimos) es, en su forma representada, un grupo de puntos unidos por líneas. A los puntos se les llama nodos o vértices y a las líneas se las conoce como aristas o enlaces. En esta lección preferiremos los términos nodos y aristas, respectivamente, pues son los que comunmente encontramos en la literatura en español.
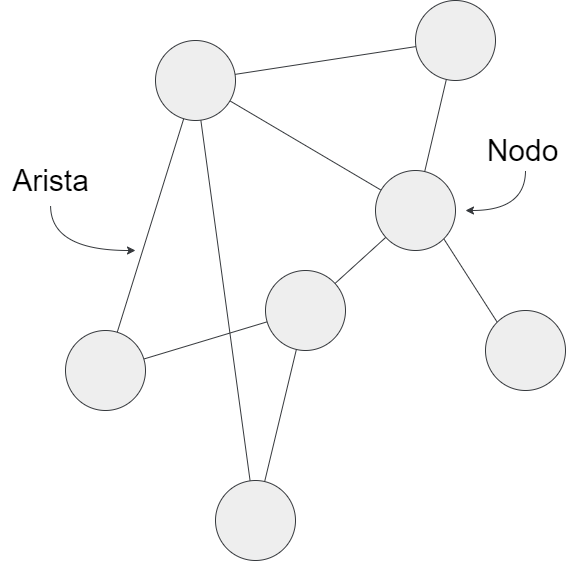
Red o grafo formado por nodos y aristas
Un grafo no es más que la representación de un sistema cualquiera formado por elementos (los nodos) relacionados entre sí (a través de lás aristas). Gracias al ARS podemos estudiar estos sistemas de elementos y relaciones y, aunque no es necesario llegar a crear las representaciones propiamente dichas, la visualización de los datos en redes suele estar siempre presente en estos análisis.
Los grafos pueden ser de dos tipos: no dirigidos, cuando la relación entre dos elementos cualquiera es siempre bidireccional; y dirigidos cuando la relación entre dos elementos es en una sola dirección o en las dos. En este segundo caso, la dirección de las aristas se representa en los grafos a través de flechas o de líneas curvas en el sentido de las agujas del reloj.
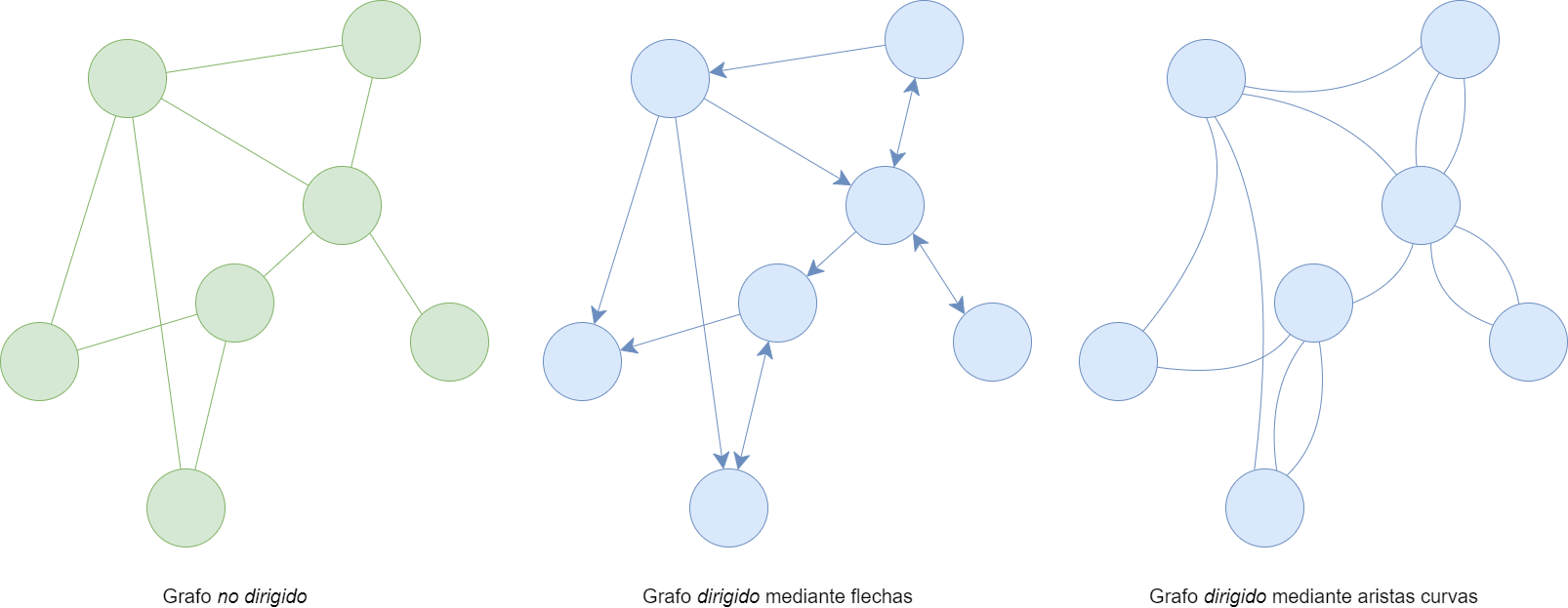
(a) Grafo no dirigido; (b) grafo dirigido mediando flechas; (c) grafo dirigido mediante aristas curvas
En una red social cada nodo se correspondería con una persona (o personaje) del sistema. El número de otros nodos con los que un nodo concreto está conectado se conoce como grado. En el caso de los grafos dirigidos, además del grado tenemos lo que se llama grado de entrada y grado de salida, es decir, para un nodo concreto, serían los nodos que conectan con él y los nodos con los que él conecta (este número puede diferir). Por su parte, las aristas suelen tener un valor numérico asociado que representa la frencuencia de la relación entre los nodos que conecta. Este valor se conoce como peso de la arista y generalmente se representa a través del grosor de las líneas:
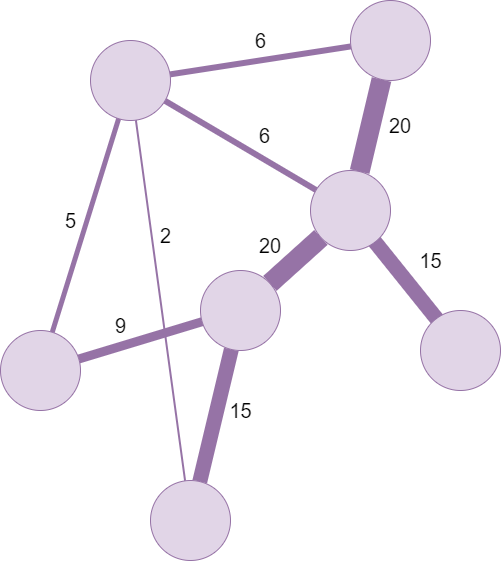
Grafo con las aritas pesadas, indicándose a través de su grosor
Cómo llevar a cabo el análisis de redes de un texto teatral
Para llevar a cabo un análisis de redes sociales de personajes teatrales debemos seguir una serie de pasos consecutivos:
- Creación del corpus de análisis
- Conseguir los datos 2.1. Toma de decisiones para la extracción de datos 2.2. Extracción y estructuración de datos
- Creación de visualizaciones (grafos) y aplicación de medidas
- Interpretación de los resultados
1. Creación del corpus de análisis
El corpus de análisis puede estar formado por un solo texto teatral o por muchos, en caso de que queramos realizar un análisis de redes comparado. En esta lección trabajaremos con una sola obra, la comedia Las bizarrías de Belisa de Lope de Vega. Si quisieras construir un corpus de análisis más grande mi recomendación sería consultar el artículo de José Calvo Tello (2019): Diseño de corpus literario para análisis cuantitativo.
2. Conseguir los datos
2.1. Toma de decisiones: ¿qué datos necesitamos?
Una vez tenemos el texto o textos que queremos analizar lo siguiente es conseguir los datos. Si pensamos un texto teatral como una red de nodos y aristas los nodos serían los personajes y las aristas las relaciones entre estos. ¿Pero qué entendemos por relación entre personajes? ¿Cómo cuantificamos esta relación para poder darle un peso a las aristas?
En los estudios de teatro principalmente se vienen siguiendo dos criterios para cuantificar la relación entre personajes:
- Coaparición de personajes en escena
- Interacción lingüística directa entre personajes
Ambos criterios son perfectamente válidos, y tienen numerosos trabajos que los respaldan, pero cada uno permite construir un tipo de grafo concreto. Por lo tanto, en función de nuestras preguntas y objetivos de investigación deberemos elegiremos un criterio u otro. En esta lección vamos a explicar los dos para que después, cuando trabajes con tus textos, puedas decidirte por uno u otro.
Según el criterio de la coaparición de personajes en escena dos personajes están relacionados si intervienen en una misma escena. Así, cuantificaremos todas las veces que un personaje dado coincide en escena con cada uno de los demás, indepedientemente de si interactúan o no. Por lo tanto, este criterio solo nos permite construir grafos no dirigidos, en los que la relación entre nodos es neceariamente bidireccional.
Según el criterio de la interacción lingüística directa entre personajes dos personajes están relacionados si hablan entre sí, por lo que se anota y cuantifica cada vez que un personaje se dirige a otro. Por lo tanto, este criterio nos permite construir grafos dirigidos, en los que la relación entre nodos es en las dos direcciones o en una sola: el personaje 1 puede dirigirse al personaje 2, pero el personaje 2 puede no responder al 1.
Bien, sabemos quiénes son los nodos (los personajes, que podemos extraer del dramatis personae) y podemos identificar las aristas y su peso (las relaciones entre personajes, según uno u otro criterio de cuantificación, y el número de veces que se relacionan). Estos son los datos mínimos para realizar un análisis de redes sociales. Sin embargo, aún podríamos extraer más datos de un texto teatral en función de nuestros intereses y de cuánto queramos enriquecer el análisis. Tanto los nodos como las aristas pueden tener una serie de atributos, como si fueran metadatos de los personajes y de sus relaciones. Estos atributos son informaciones cualititativas que posteriormente nos pueden servir para enriquecer las visualizaciones y para el análisis de los datos resultantes. Por ejemplo, podría interesarnos recoger el género de los personajes (mujer, hombre, no binario, no aplicable, etc.) y su función dentro de la obra (por ejemplo: dama, galán, criado, etc.); o el tipo de relación entre los personajes (romántica, familiar, etc.). Volveremos sobre ello.
2.2. Extracción y estructuración de datos
¿Cómo estructuramos los datos?
Lo primero que necesitamos recoger son los datos sobre los nodos, y lo haremos en lo que se conoce como lista de nodos. En ella se recogen los nombres de los personajes (label, etiqueta), un identificador (id) numérico individual que le otorgamos a cada personaje y sus atributos (en caso de que quisiésemos registrar metadatos). Así se vería una lista de nodos:
id,label,atributo1,atributo2
1,Nodo1,______,______
2,Nodo2,______,______
3,Nodo3,______,______
Como ves, los datos están estructurados utilizando saltos de línea y comas. Es lo que se conoce como CSV (del inglés Comman Separated Values). CSV es un formato abierto que representa datos tabulados de manera más sencilla, en donde los valores de cada columna se separan por comas y los de cada fila por un salto de línea. Este es el formato que todos los programas de análisis de redes pueden importar, por lo que será el formato final de nuestros datos. Sin embargo, para facilitar el trabajo de extracción y estructuración, vamos a recoger nuestros datos utilizando hojas de cálculo en el programa de tu preferencia (como Microsoft Excel, LibreOffice Calc o Google Sheets). Estos programas trabajan con documentos en los que se estructuran datos usando tablas, con filas y columnas que se intersecan formando una matriz de celdas, y posteriormente nos permiten exportar dichas tablas en el formato CSV que necesitamos.
Entonces, la lista de nodos de arriba se vería así en una hoja de cálculo:
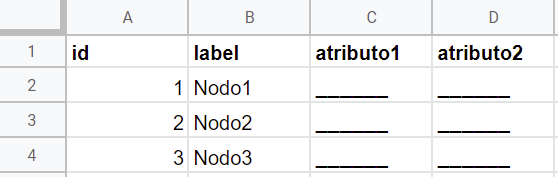
Lista de nodos en una hoja de calculo
Por otro lado, para estructurar los datos relativos a las aristas existen dos métodos distintos:
- Lista de aristas
- Matriz de adyacencia
En una lista de aristas se anota el nodo de origen (source), el nodo de destino (target), el peso de la arista que les une (weight) y el tipo de relación (type), que como hemos visto puede ser dirigida (directed) o no dirigida (undirected). Además, podríamos anotar atributos de las aristas utilizando una etiqueta (label). Una lista de aristas para un grafo no dirigido quedaría de esta forma:
Source,Type,Target,Weight,label
Nodo1,Undirected,Nodo2,7,______
Nodo1,Undirected,Nodo3,3,______
Nodo2,Unidrected,Nodo3,6,______
Si quisiésemos generar un grafo dirigido, en cambio, deberíamos doblar cada relación: una para el Nodo1 hacia el Nodo2 y otra para el Nodo2 hacia el Nodo1. Mira un ejemplo:
Source,Type,Target,Weight,label
Nodo1,Directed,Nodo2,7,______
Nodo2,Directed,Nodo1,6,______
Nodo2,Directed,Nodo3,6,______
Nodo3,Directed,Nodo2,5,______
Nodo1,Directed,Nodo3,8,______
Nodo3,Directed,Nodo1,8,______
De nuevo, estruturamos los datos en formato CSV, pero es más fácil si lo hacemos en una hoja de cálculo que después exportamos. Para ello, utilizamos cada columna para un tipo de dato distinto, indicando en la primera fila de qué dato se trata (source, type, target, weight, label) y en el resto de filas los valores de cada arista:
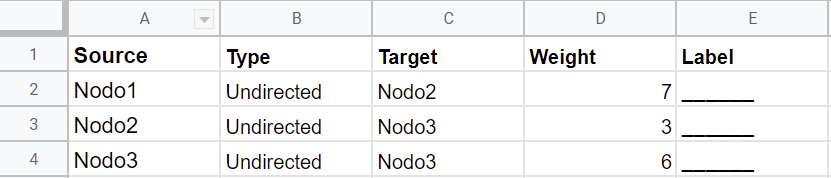
Lista de aristas registrada en una hoja de cálculo
En una matriz de adyacencia recogemos los datos referentes a las aristas en una matriz cuadrada, en donde la primera columna representa los nodos de origen y la primera fila los nodos de destino, siempre numerando cada fila y columna con los identificadores (id) que les otorgamos a los personajes al crear la lista de nodos. En las intersecciones entre columnas y filas anotaríamos el peso de la arista entre nodos, la cuantificación de la relación entre dos personajes. Así se vería una matriz de adyacencia vacía, solo con los id de los personajes (ten en cuenta que las relaciones no existentes deben de tener siempre valor 0):
1 2 3 4 5 6
1 0 0 0 0 0 0
2 0 0 0 0 0 0
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 0 0 0 0 0
6 0 0 0 0 0 0
Si estamos estructurando los datos de un grafo no dirigido (pensemos en la coaparición de escenas), anotaríamos el peso de la relación entre dos personajes tanto en el lugar en el que se interseca el Nodo1 con el Nodo2 como Nodo2 con el Nodo1. Por ejemplo, en esta matriz leemos que 1 y 2 comparten 4 escenas:
1 2 3 4 5 6
1 0 4 0 0 0 0
2 4 0 0 0 0 0
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 0 0 0 0 0
6 0 0 0 0 0 0
En cambio, si vamos a construir un grafo dirigido (pensemos en la interacción lingüística entre personajes), podemos anotar valores distintos en cada intersección. Por ejemplo, en esta matriz leemos que el Nodo1 dirige 9 de sus intervenciones al Nodo2 pero el Nodo2 solo habla 4 veces al Nodo1.
1 2 3 4 5 6
1 0 9 0 0 0 0
2 4 0 0 0 0 0
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 0 0 0 0 0
6 0 0 0 0 0 0
Las matrices de adyacencia también las necesitamos en formato CSV, por lo que cada número debería ir separado por comas, así:
,1,2,3,4,5,6
1,0,9,0,0,0,0
2,4,0,0,0,0,0
3,0,0,0,0,0,0
4,0,0,0,0,0,0
5,0,0,0,0,0,0
6,0,0,0,0,0,0
Una vez más, para facilitar el trabajo de recogida de datos, utilizaremos hojas de cálculo en las que, numerando las filas y columnas, anotamos los pesos de las relaciones en las celdas que se encuentran en las intersecciones. Es muy importante que hagamos coincidir la numeración de la matriz de adyacencia con el id que le hemos asignado a cada personaje en la lista de nodos, de forma que el programa de análisis de redes pueda relacionar a cada nodo con sus relaciones. Así se vería una matriz de adyacencia en una hoja de cálculo:
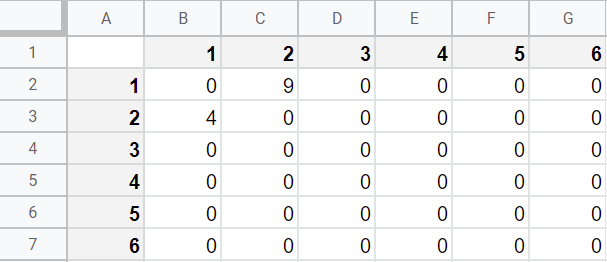
Matriz de adyacencia de un grado no dirigido registrada en una hoja de cálculo
En las matrices de adyacencia no podemos etiquetar (label) las aristas, pero los programas de análisis de redes permiten modificar los datos y añadir dicha información después de la importación.
El proceso de vaciado
Ya sabemos qué datos necesitamos extraer del texto teatral y cómo estructurarlos para poder realizar un análisis de redes. Ahora, pasemos a la práctica. Vamos a analizar Las bizarrías de Belisa basándonos en los dos criterios explicados. Así podremos comprender bien cómo se aplica cada uno y sus diferencias, lo que te ayudará después a decidirte por uno u otro criterio. Para seguir la lección, puedes encontrar este texto en la Biblioteca Digital ARTELOPE[^5].
Los nodos
Vamos a empezar creando la lista de nodos, que nos vale tanto para un ARS basado en la coaparición en escena como para uno basado en las interacciones lingüísticas. Podemos extraer la lista de personajes del dramaties personae, ¡pero recuerda hacer una lectura atenta de la obra para comprobar que no falta ninguno! En nuestro caso, la edición de la obra con la que trabajamos recoge bien todos los personajes, así que no debes preocuparte en este sentido.
Primero, crea una hoja de cálculo en el programa que tú prefieras, o descarga la plantilla que he preparado siguiendo este enlace: https://docs.google.com/spreadsheets/d/1_RCqlJ8epD9S29dCySgYlOCZpOIKaVMzelgv0dyd64g/. Puedes llamar al documento datos_bizarrias.xlsx/gsheet/odf y a la primera hoja “Lista de nodos”. En esta hoja, escribe en la primera fila:
iden la primera colummnalabelen la segunda columnagéneroen la tercera columnafunciónen la cuarta columna
género y función son atributos de los nodos, metadatos de los personajes. Recuerda que puedes anotar todos los que quieras en las siguientes columnas.
Lo siguiente es rellenar las celdas:
- Recoge los nombres de los personajes en la columna
label - Numera las celdas
iddel 1 al 11 (11 personajes interactúan en Las bizarrías de Belisa, dejando deliberadamente fuera a los músicos, criados y lacayos y a los dos hombres. Unos se considera personajes no computables y otros aparecen en escena pero no hablan) - Anota el género (mujer/hombre) de los personajes en la columna correspondiente
- Anota la función de los personajes en la comedia según esta clasificación: dama, galán, criado, criada, figura de autoridad (padre, madre, tía, hermano de la dama, etc.), figura de poder (rey, gobernador, etc.)
Debería quedarte una tabla así:
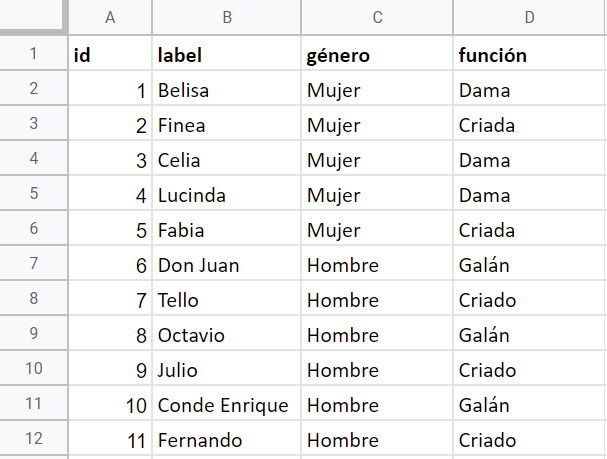
Lista de nodos de Las bizarrías de Belisa
Ahora exporta la hoja en formato CSV y llama al archivo nodos_bizarrias.csv:
- En Google Sheets ve a Archivo>Descargar>Valores separados por comas (.csv)
- En Micrososft Excel ve a Archivo>Guardar como>Tipo>CSV (delimitado por comas) (*.csv) o Exportar>Cambiar el tipo de archivo>CSV (delimitado por comas) (*.csv)
- En LibreOffice Calc ve a Archivo>Guardar como>Tipo>Texto CSV (*.csv)
¡Ya tienes preparada la lista de nodos!
Las aristas
Para extraer los datos de las aristas recuerda que primero debes elegir el criterio de cuantificación, en función de lo que te interese investigar. Para estructurar los datos obtenidos de aplicar ambos criterios a un texto teatral podemos usar tanto el método de la lista de aristas como el de la matriz de adyacencia, aunque en general resulta más cómodo usar la lista de aristas para los grafos no dirigidos y la matriz de adyacencia para los dirigidos. Así lo haremos en esta lección.
Lista de aristas para grafos no dirigidos basados en la coaparición de personajes en escena utilizando Easy Linavis
En el mismo archivo en el que creaste la lista de nodos, datos_bizarrias, crea una nueva hoja y llámala “Lista de aristas”. En esta hoja debes escribir en la primera fila lo siguiente, tal y como está en la plantilla :
Sourceen la primera columnaTypeen la cuarta columnaTargeten la segunda columnaWeigthen la tercera columnaLabelen la quinta columna
Lo siguiente es rellanar las celdas, para cual deberías ir anotando cada vez que un personaje (source) comparte escena con otro (target) y la cantidad de escenas que comparten (weight). Como usaremos la lista para generar un grafo no dirigido, en todas las celdas type escribiremos undirected (no dirigido). Después, anotaríamos el tipo de relación (label) según una clasificación preestablecida.
Como puedes estar imaginando se trata de un proceso tedioso. Pero no te preocupes, utilizaremos una herramienta web de libre acceso que nos va a facilitar mucho el trabajo: Easy Linavis, desarrollada y alojada por el proyecto DraCor (DramaCorpora). Esta herramienta nos permite introduccir cada acto y escena y los nombres de los personajes que en ellas intervienen, y a partir de estos datos nos genera un lista de aristas que podremos descargar en formato CSV. Además, mientras introducimos los datos, Easly Linavis va generando un grafo de la obra que nos ayuda en el proceso.
Puedes acceder a Easy Linavis a través de la web de DraCor (apartado “TOOLS”) o directamente utilizar este enlace: https://ezlinavis.dracor.org/. Una vez dentro (no hace falta registrarse para poder usarla) verás una disposición en tres columnas. En la primera introduciremos los datos, en la segunda se generará la lista de aristas y en la tercera el grafo. Además, en el menú arriba a la izquierda encontrarás un desplegable con ejemplos, tipos de grafos (tres algoritmos de distribución disintos, más adelante veremos qué es esto), y un “about” con información sobre la herramienta y su uso (solo en inglés, pero puedes utilizar una extensión de traducción del navegador para traducirlo automáticamente).
El formato en el que tenemos que introducir los datos es muy sencillo. Puedes hacerlo directamente en la columna correspondiente o escribirlo en un documento aparte y luego copiar y pegar. Mi recomendación es que comiences a escribir en la herramienta, ya que con colores rojo y verde te indica si estás respentando el formato correcto. Una vez aprendas, continúa en un documento aparte que puedas guardar: ¡si se cierra la página o el navegador perderás tu trabajo! Este documento aparte debería ser un arhivo de texto simple sin formato (texto plano) como un TXT, pues así contendrá solamente caracteres y no deberás preocuparte al copiar y pegar del archivo a la herramienta Easy Linavis. Para ello, utiliza el Bloc de notas que viene nativo en Windows, TextEdit en Mac o tu editor de texto (no procesador como Word o Pages) preferido: VS Code, Atom, Sublime Text, NotePad++, etc.
El formato de datos que implementa Easy Linavis es muy sencillo:
- Escribe el título de la obra, su autor y otros datos que te interesen (año de escritura o publicación, edición seguida, tu nombre, etc.) sin dejar saltos de línea en blanco. Esta información no es obligatoria pero puede servirte para identificar cada obra si estás analizando un corpus grande y terminas teniendo muchos archivos
"Las bizarrías de Belisa" (1634) de Lope de Vega Criterio: coaparición de personajes en escena Edición seguida: https://artelope.uv.es/biblioteca/textosAL/AL0525_LasBizarriasDeBelisa.php Responsable: David Merino Recalde Fecha: 12-09-2022 - Seguido, dejando ahora sí un salto de línea, anota la estructura básica de la obra (actos y escenas) utilizando asteriscos para jerarquizar las divisiones: ``` # ACTO 1 ## Escena 1 ## Escena 2 ## Escena 3 etc.
# ACTO 2 ## Escena 1 ## Escena 2 ## Escena 3 etc.
# ACTO 3 ## Escena 1 ## Escena 2 ## Escena 3 etc.
3. Recoge los nombres de los personajes que intervienen (no los que simplemente aparecen) en cada escena bajo el epígrafe correspondiente. ¡Recuerda utilizar siempre el nombre que hayas registrado en la lista de nodos!
# ACTO 1
## Escena 1
Finea
Belisa
## Escena 2
Belisa
Celia
## Escena 3
Don Juan
Tello
etc. ```
Sigamos:
- Si has terminado de recoger la coaparición de personajes en un archivo TXT, copia y pega en Easy Linavis. Una vez tengas el listado en la herramienta, comprueba que hay una línea verde a la izquierda de la columna. Si está de color rojo te está indicando que hay un error en el formato (un salto de línea donde no debe, un asterisco mal situado, etc.). A la derecha te aparecerá un grafo: revisa también que no haya personajes repetidos con nombres distintos (por ejemplo un Conde y un Conde Enrique, o una Lucinda y una Luncinda). Una vez tengas claro que todo está correcto, en la columna del centro, haz clic en
download CSVy guarda el archivo comodatos_bizarrias-easylinavis.csv - Este archivo que has descargado ya podrías importarlo en un programa de análisis de redes, pero queremos introducir un atributo a las relaciones. Ve a la hoja de cálculo en la que hemos estado trabajando y borra la hoja que primero nombramos “Lista de aristas”. Ahora importa el archivo CSV creando una nueva hoja dentro del mismo documento:
- En Google Sheets: Archivo>Importar>Seleccionar el CSV de Google Drive o Subir/Arrastrar>Ubicación de importación:Insertar nuevas hojas>Tipo de separador:Coma>Importar datos
- En Microsoft Excel: Datos>Obtener datos>De un archivo>De texto/CSV>Seleccionar el CSV y Abrir>Delimitador:Coma>Cargar
- En LibreOffice Calca: Hoja>Insertar hoja desde archivo>Seleccionar el CSV y Abrir>Separado por: Coma>Aceptar>Posición:Detrás de la hoja actual/Hoja:Desde Archivo>Aceptar
- Ahora cambia el nombre de la nueva hoja a “Lista de aristas” y añade de nuevo la columna después de
WeightllamadaLabel. Vuelves a tener la misma lista que creamos antes pero con la mayoría de datos completados. Solo te falta clasificar cada relación según esta tipología: amor recíproco, amor no correspondido, rivalidad, amistad, relación efímera, familiar, servidumbre, etc. - Una vez hayas terminado de completar datos, utilizando la opción Buscar y reemplazar, reemplaza los nombres de los personajes por el número
idque les otorgaste en la lista de nodos - Por último, exporta la hoja actual y llama al archivo
aristas-coaparicion_bizarrias.csv.
¡Ya tienes preparada la lista de aristas!
Matriz de adyacencia para grafos dirigidos basados en las interacciones lingüísticas entre personajes
Si escoges analizar el texto teatral basándote en las interacciones lingüísticas directas y construir un grafo dirigo lo mejor es utilizar una matriz de adyacencia para estructurar los datos que necesitas extraer. Para ello, crea un nueva página en la hoja de cálculo base en la que estás trabajando y llámala “Matriz de adyacencia”.
En esta nueva página, deberías numerar la primera columna y fila del 1 al 11 dejando libre la primera celda, tal y como vimos en el ejemplo más arriba. Para facilitarnos el trabajo, en vez de utilizar números escribiremos los nombres de los personajes en el mismo orden que en la “Lista de nodos”. Más tarde, simplemente sustituiremos cada nombre por su id como hemos hecho con la lista de aristas.
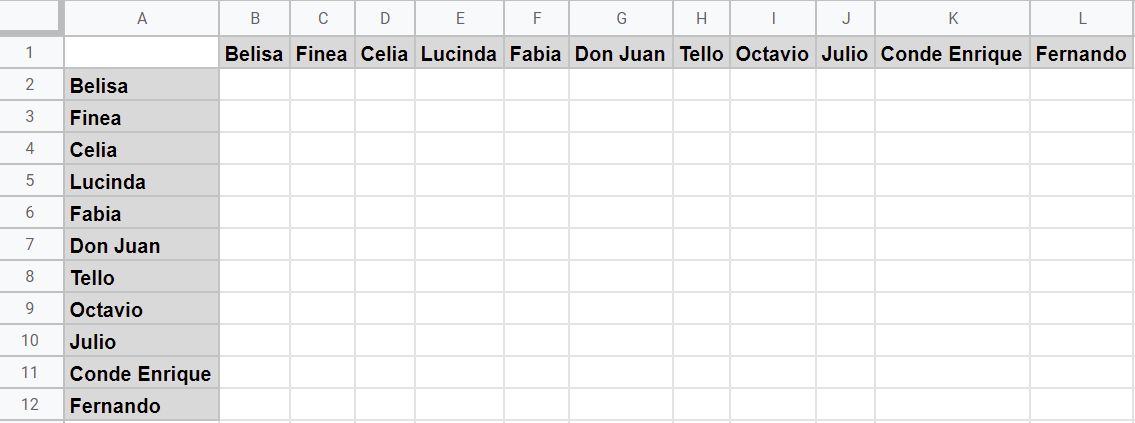
Matriz de adyacencia base de Las bizarrías de Belisa
Una vez tengas la matriz base debes comenzar a recoger los datos contando las interacciones lingüísticas. El criterio básico es el siguiente: si el personaje 1 habla con el personaje 2, sumamos 1 en la celda que se encuentra en la intersección entre la fila de 1 y la columna de 2. Habrá intervenciones muy claras y otras que generen ambigüedad, intervenciones que no van dirigidas necesariamente a ningún personaje (por ejemplo: a sí mismo, al público, un ruego a una divinidad, etc.), intervenciones de un personaje a varios… Por esta razón debemos fijar primero unos criterios de extracción y anotación que tengan en cuenta todas estas posibles situaciones (detectables solo a través de una lectura atenta del texto). La idea es que estos criterios nos guíen en la toma de decisiones y siempre resolvamos de la misma forma las situaciones complejas, posibilitando el análisis comparado de textos que hayan sido analizados siguiendo nuestros criterios de extracción y anotación.
Para esta lección vamos a utilizar los siguientes criterios, diseñados para analizar comedias del siglo Siglo de Oro español como la que estamos utilizando en esta lección:
- Se anotará cada interacción directa de un personaje hacia otro, entendiendo al primero como emisor y al segundo como receptor
- Por norma general, cada intervención marcada en el texto equivale a una interacción, y esta interacción puede tener uno o varios receptores:
- Si A se dirige a B, se anotará 1 de A a B
- Si A se dirige a B y C, se anotará 1 de A a B y 1 de A a C
- Casos especiales:
- Una intervención marcada en el texto puede tener varias partes y, por tanto, contener distintas interacciones si el emisor cambia el personaje a quien se dirige. Así, en una misma intervención, podrían anotarse dos versos de A a B y tres versos de A a C.
- Una interacción interrumpida por otro personaje que continúa tras el corte (versos partidos) se registrará como una interacción, a pesar de estar distribuida en dos intervenciones
- Por norma general, cada intervención marcada en el texto equivale a una interacción, y esta interacción puede tener uno o varios receptores:
- Del criterio anterior, por tanto, se deduce lo siguiente:
- Si un personaje C está en escena pero no es el receptor directo de la intervención que se está registrando de A a B, dicha intervención no se le anotará a C aunque se entienda que necesariamente ha tenido que escuchar esta interacción por estar presente
- Si un personaje habla en escena pero no hay ningún otro personaje receptor, dicha intervención no se registrará. Es el caso de los monólogos que algunos personajes pronuncian al quedarse solos en escena, muchas veces en forma de soneto
- Si un personaje interviene y, a pesar de haber otros personajes en escena, ninguno de ellos es el receptor directo, dicha intervención no se registrará. Es el caso de los apartes a público, pues los apartes entre personajes entran dentro del caso 1.1.1
- Si un personaje se dirige al público para cerrar la comedia, dicha intervención no se registrará, pues el receptor es el público y no otro personaje
Una vez tenemos los criterios claros, comenzamos a leer la obra y a anotar. Por ejemplo, el primer acto comienza así:
FINEA: ¿Así rasgas el papel?
BELISA: Cánsame el Conde, Finea.
Finea dirige su primera intervención a Belisa y esta le responde. Por lo tanto, en nuestra matriz de adyacencia deberíamos anotar 1 de Finea a Belisa y 1 de Belisa a Finea:
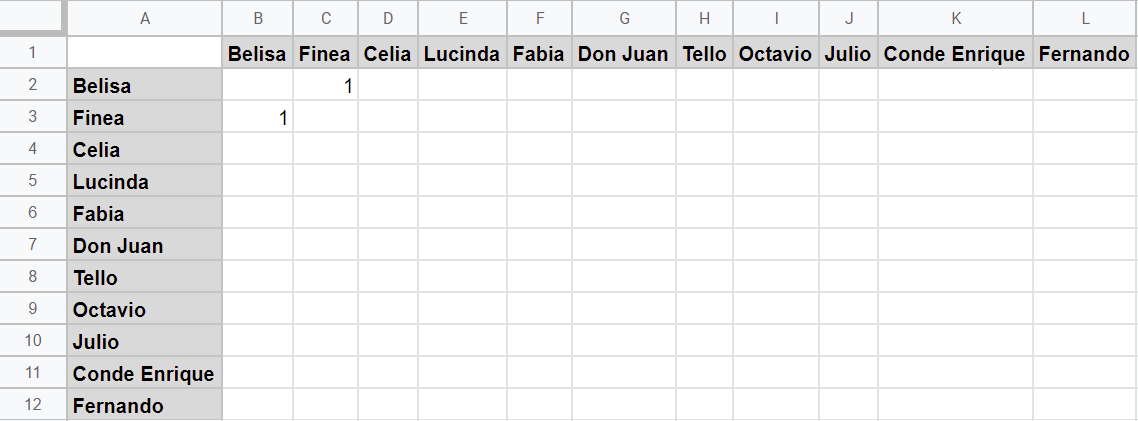
Matriz de adyacencia de Las bizarrías de Belisa tras registrar los dos primeros versos de la comedia
Otro ejemplo, en la escena 13 del acto 3 don Juan dice a Lucinda y al Conde Enrique:
DON JUAN: Huélgome de hallar aquí,
señor, a Vueseñoría,
no para disculpa mía,
si es que anoche le ofendí,
sino porque de Belisa
traigo a los dos un recado.
Esta intervención deberíamos anotarla con doble destinatario, es decir, sumar 1 de don Juan a Lucinda y 1 de don Juan al Conde.
Así continuaríamos haciendo con toda la obra. Mi recomendación es que anotes cada intervención en la que tuviste dudas y cómo la resolviste, por si acaso debes volver atrás en algún momento y revisar tus decisiones.
Una vez termines, intercambia cada nombre de pesonaje de tu matriz con el id que le asignaste en la lista de nodos, tanto en la primera columna como en la primera fila. Para ello puedes utilizar la opción Buscar y reemplazar. Por último, exporta la hoja actual como archivo CSV y llama al archivo resultante aristas-interaccion_bizarrias.csv.
¡Ya tienes tu matriz de adyacencia preparada!
En esta ocasión no hemos podido introducir atributos a las relaciones, pero no te preocupes, lo haremos más adelante.
3. Visualización y análisis de grafos con Gephi
Ahora tenemos tres archivos CSV: por un lado, una lista de nodos; por el otro, la lista de aristas de un grafo no dirigido y la matriz de adyacencia de uno dirigido, según el criterio de la coaparición de personajes en escena y el de interacciones lingüísticas directas entre personajes, respectivamente. El siguiente paso es generar visualizaciones, los grafos propiamente dichos, y analizarlos aplicando lo que se conoce como medidas o métricas de ARS.
Instalación de Gephi y primeros pasos
El programa que vamos a utilizar para llevar a cabo todo esto se llama Gephi[^6]. Se trata de un software libre de código abierto especializado en análisis de redes, muy conocido y utilizado en Humanidades Digitales, bastante intuitivo y que sigue siendo mantenido y actualizado por sus desarrolladores[^7]. Además, disponemos de numerosos pluggins, guías de uso, videotutoriales en español[^8] y una comunidad activa en Twitter y Github a la que consultar nuestras dudas.
Lo primero que debemos hacer es instalar Gephi. En su sitio web, https://gephi.org/, haz clic en “Download FREE”. Está disponible para Windows, Mac OS y Linux. Es posible que la web reconozca tu sistema operativo y te ofrezca lo que necesitas, si no, selecciona en el apartado “All downloads” tu sistema operativo. Si necesitas ayuda con la instalación, puedes visitar https://gephi.org/users/install/ (solo disponible en inglés, pero puedes consultar los videotutoriales en español anteriormente mencionados).
Una vez finalices la instalación, ejecuta Gephi. Se abrirá una ventana de bienvenida con distintas opciones: crear un nuevo proyento, abrir un archivo de grafo ya existente, una columna con proyectos y archivos recientes (si los hubiese) y varios proyectos de ejemplo. Haz clic en “Nuevo proyecto”:
Ventana de bienvenida de Gephi
Ahora estás en la pantalla principal del programa. Gephi funciona mediante proyectos (fíjate que te indicará en la barra superior que estás en el “Proyecto 1”), y dentro de cada proyecto puedes crear distintos espacios de trabajo. Ahora estás en el “Espacio de trabajo 1”. Cada espacio de trabajo funciona como la pestaña de un navegador web y contiene a su vez los tres apartados de Gephi: Vista general, Laboratorio de datos y Previsualización.
En la Vista general se crean las visualizaciones y se aplican los filtros y medidas para analizar los grafos. En el Laboratorio de datos se trabaja con los datos que generan los grafos, pudiéndose importar o introducir directamente, modificar y exportar. En el apartado de Previsualización se realizan los últimos ajustes de visualización antes de exportar los grafos.
Comencemos a trabajar:
- En la barra de opciones superior, haz clic en Espacio de trabajo>Nuevo para crear un nuevo espacio de trabajo
- Renombra los dos espacios creados, denominando al primero “Coaparición en escena” y al segundo “Interacción lingüística”, haciendo clic en Espacio de trabajo>Renombrar desde dentro de cada espacio
- Guarda el proyecto en Archivo>Guardar como, y llámalo
bizarrias.gephi
El “Laboratorio de datos”: importación de aristas y nodos
Ahora vamos a importar nuestros datos. Lo haremos en paralelo con los dos grafos, pues te ayudará a no perderte. Primero las aristas del grafo de coaparición de personajes en escena:
- Estando en el espacio de trabajo Coaparición en escena dirígete al Laboratorio de datos y haz clic en “Importar hoja de cálculo”
- Busca y selecciona el archivo
aristas-coaparicion_bizarrias.csvy haz clic en “Abrir” - Se abrirá una primera ventana de Opciones generales de CSV. Seguramente Gephi ha detectado que se trata de una tabla de aristas, que el separador es la coma y que el formato de codificación de caracterse es UTF-8. Si no, selecciona estas opciones en los desplegables y haz clic en “Siguiente”
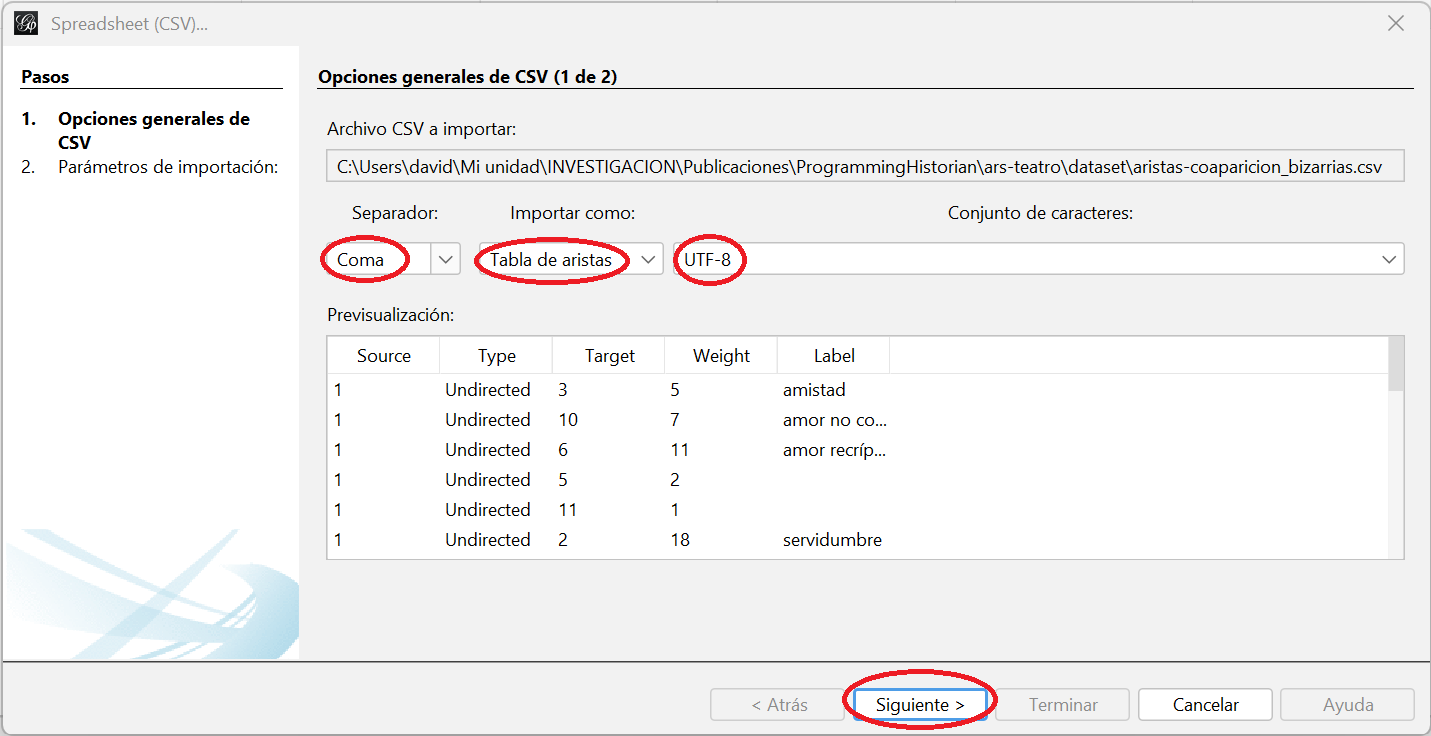
Ventana de importación de hojas de cálculo con las opciones generales para la lista de aristas
- En la siguiente ventana, Parámetros de importación, deja seleccionadas todas las casillas, pues queremos importar nuestras cinco columnas. Gephi reconoce el tipo de datos: double (números) para el peso y string (cadena de caracteres) para las etiquetas. Haz clic en “Terminar”
- Ahora te aparecerá la última ventana del proceso: el Informe de importación. Verás que Gephi ha detectado que se trata de un grafo “no dirigido” con 11 nodos y 42 aristas, y que no encuentra ningún problema en el archivo. Muy importante: cambia la selección de “Nuevo espacio de trabajo” a “Añadir al espacio de trabajo existente”. Queremos que nos importe los datos en el espacio en el que estamos trabajando, “Coaparición en escena”. Cuando lo hagas, haz clic en “Aceptar”
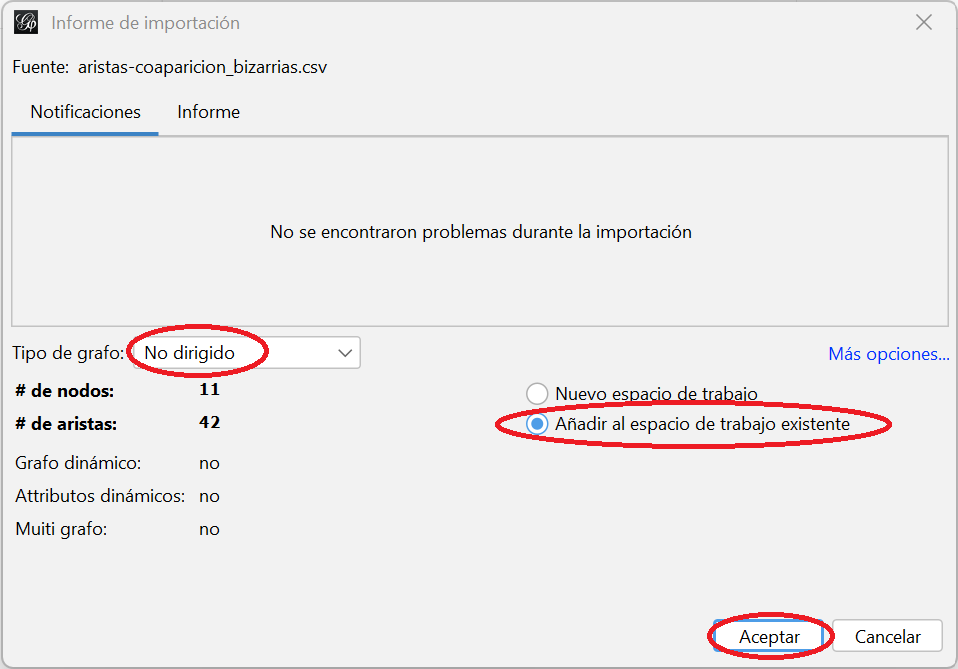
Ventana con el informe de importación de la lista de aristas
Verás que ha aparecido una tabla con los id de los personajes en la pestaña “Nodos” y una tabla con las relaciones en la pestaña “Aristas”. Gephi ha extraido esta información de nuestra lista de aristas, asignando además un id a cada arista.
Ahora vamos a importar las aristas del grafo de interacciones lingüísticas directas, siguiendo los mismos pasos:
- Dentro del espacio de trabajo “Interacción lingüística” dirígete al Laboratorio de datos y haz clic en “Importar hoja de cálculo”
- Busca y selecciona el archivo
aristas-interaccion_bizarrias.csvy haz clic en “Abrir” - Se abrirá una primera ventana de Opciones generales de CSV. Seguramente Gephi ha detectado que se trata de una matriz, que el separador es la coma y que el formato de codificación de caracterse es UTF-8. Si no, selecciona estas opciones en los desplegables y haz clic en “Siguiente”
- En la siguiente ventana, Parámetros de importación, simplemente haz clic en “Terminar”. Ahora no hay columnas entre las que poder elegir
- Por último te aparecerá la ventana Informe de importación. Verás que Gephi ha detectado que se trata de un grafo dirigido con 11 nodos y 51 aristas, y que no encuentra ningún problema en el archivo. Muy importante: cambia la selección de “Nuevo espacio de trabajo” a “Añadir al espacio de trabajo existente”. Como antes, queremos que nos importe los datos en el espacio en el que estamos trabajando, “Interacción lingüística”. Cuando lo hagas, haz clic en “Aceptar”
Gephi ha importado nuestra matriz y la ha transformado en una lista de aristas con un nodo de origen, otro de destino, un tipo de relación, un peso y un id. Además, ha creado 11 nodos utilizando como etiqueta el id numérico que les asignamos. A esta nueva lista de aristas le faltan los atributos (label, etiqueta), que sí pudimos importar en el caso de la lista de aristas. En la pestaña “Aristas” del Laboratorio de datos, puedes introducir manualmente estas etiquetas. Recuerda que ahora las relaciones están dobladas y también deberás doblar sus etiquetas. Es decir, hay amor correspondido de Belisa a Don Juan y también de Don Juan a Belisa. Y una relación de amistad de Belisa a Celia y otra de Celia a Belisa.
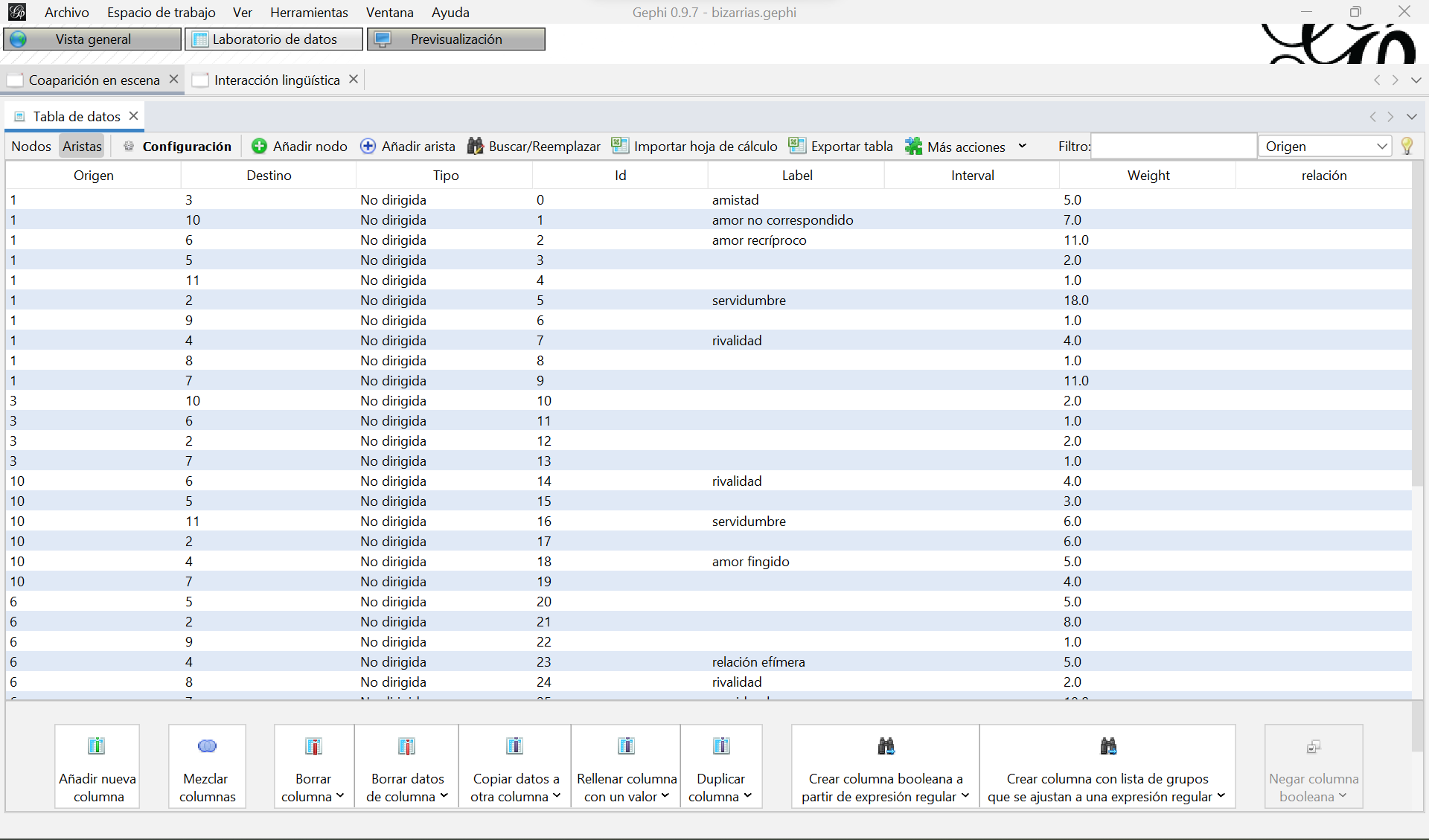
Pestaña de aristas después de introducir manualmente las etiquetas de las relaciones
Una vez finalices el etiquetado de las aristas, vamos a importar los datos referentes a los nodos de los dos grafos. Los pasos ahora son exactamente los mismos para los dos grafos, así que hazlo primero en un espacio de trabajo y luego en el otro:
- Dentro del Laboratorio de datos de cada espacio de trabajo vuelve a hacer clic en “Importar hoja de cálculo”
- Ahora busca y selecciona el archivo
nodos_bizarrias-csvy haz clic en “Abrir” - En esta ocasión Gephi habrá detectado que se trata de una “tabla de nodos”, que nuevamente el separador es la coma y que la codificación de caracteres es UTF-8. Si no, selecciona estas opciones en los desplegables y haz clic en “Siguiente”
- En la ventana Parámetros de importación mantén selecionadas todas las casillas, queremos que importe las 4 columnas. Ahora ha detectado que tanto la columna
génerocomofunciónson cadenas de caracteres (string). Haz clic en “Terminar” - En la última ventana, Informe de importación, cerciórate que de que ha identificado 11 nodos y que no hay problemas en la importación. En el desplegable referente al tipo de grafo, seleciona “No dirigido” o “Dirigido” en función del grafo que estés importando. Importante: cambia una vez más la opción de “Nuevo espacio de trabajo” a “Añadir al espacio de trabajo existente”. Después, haz clic en “Aceptar”
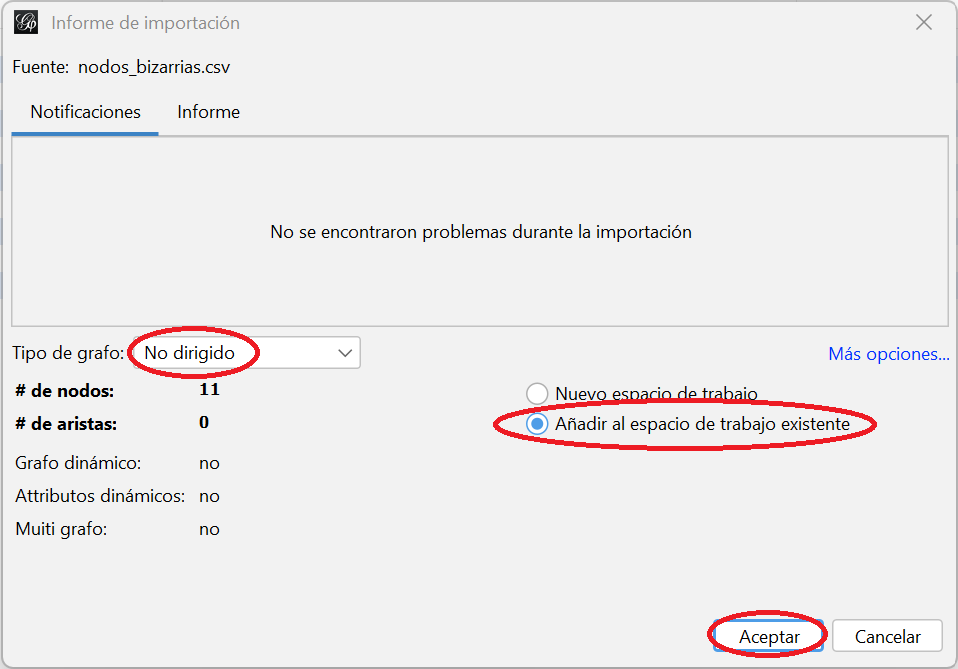
Ventana con el informe de importación de la lista de nodos del grafo de coaparición de personajes en escena
Gephi ha importado la lista de nodos y ha combinado la nueva información con los nodos que creó antes a partir de la lista de aristas o la matriz de adyacencia. Este es el motivo por el que era importante sustituir los nombres de los personaje por su id antes de exportar las hojas de cálculo a CSV. Así, Gephi ha podido identificar quién es quién y fusionar los datos de ambos archivos.
¡Enhorabuena! Hemos terminado la importación de datos de los dos grafos, ahora podemos pasar a trabajar en la pestaña Vista general.
La “Vista general”
La Vista general es donde modificaremos la visualización de nuestros grafos y donde aplicaremos las medidas y métricas para analizarlos. A la izquierda tienes las opciones de visualización (los cuadros “Apariciencia” y “Distribución”) y a la derecha un cuadro con información sobre el grafo (“Contexto”) y los cuadros “Filtros” y “Estadísticas” para consultar y analizar el grafo, respectivamente:
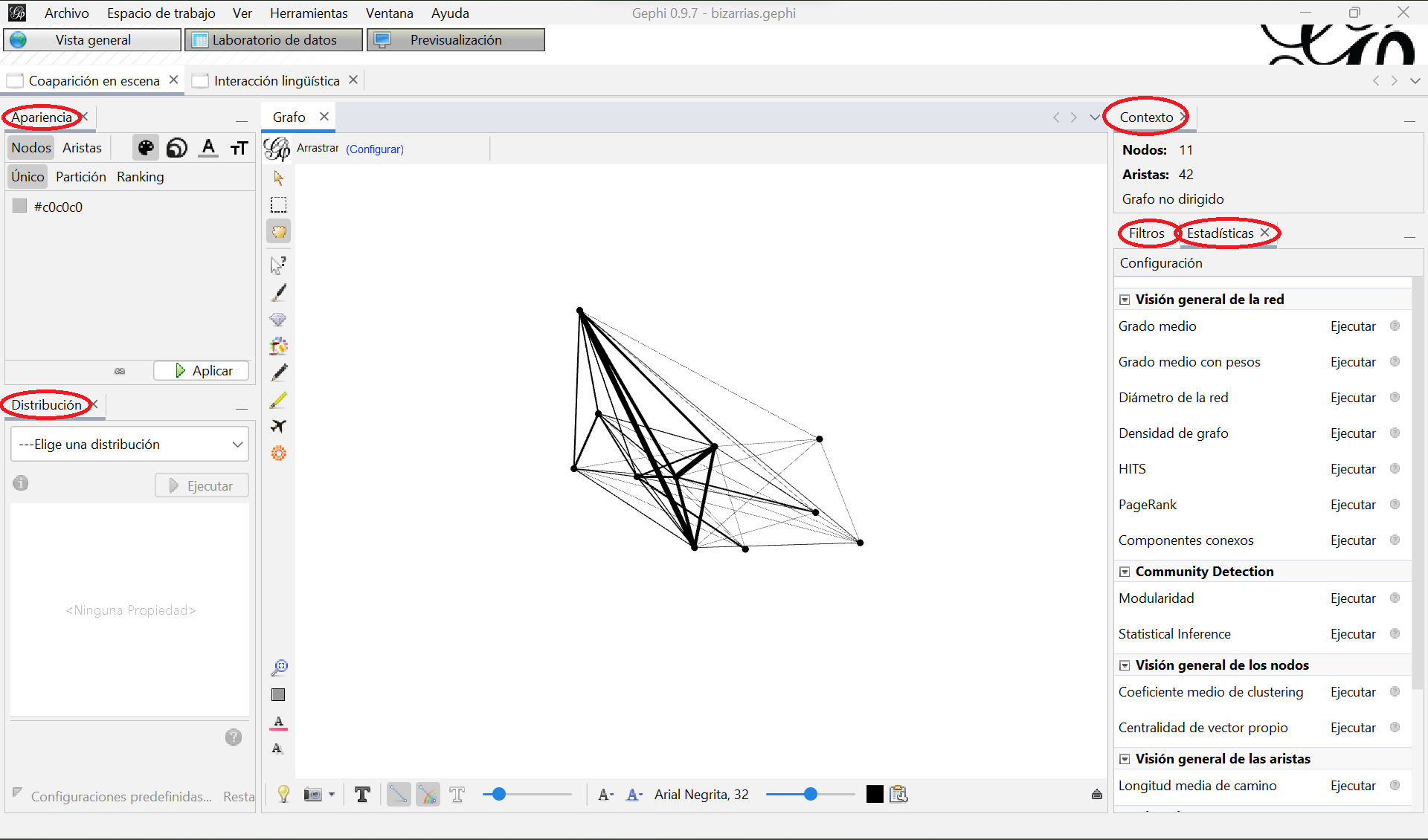
Vista general de nuestro espacio de trabajo
Las opciones de visualización y análisis son muy numerosas y no las cubriremos todas en esta lección, así que para explorar e introducirnos en Gephi vamos a crear una visualización sencilla y a aplicar solo algunas medidas básicas. A partir de ahora, todos los pasos que des en un espacio de trabajo puedes replicarlos en el otro, repetir los mismos pasos dos veces te servirá además para hacerte con el programa. Después, te animo a continuar probando todas las demás opciones y configuraciones por tu cuenta.
Modificar la apariencia y distribución del grafo
En el centro de la Vista general, en el cuadro llamado “Grafo”, nos ha tenido que aparecer una red con nodos y aristas en negro. Seguramente, el grafo de la captura de arriba (es el de coaparición en escena) no es exactamente igual al que te ha aparecido a ti. Es normal, se ha generado con una distribuición de nodos aleatoria. Comencemos a dar forma y color a nuestra red de personajes:
- Para desenmarañar la red empezaremos por aplicar un algoritmo de distribución. En el cuadro de abajo a la izquierda, “Distribución” elige el algoritmo
ForceAtlas 2y modifica estos parámetros: escalado 2500 y activar “Evitar el solapamiento”. Lo demás puedes dejarlo como está por defecto. Haz clic en “Ejecutar” y cuando el grafo se estabilice y deje de moverse en “Parar”. ¿Qué ha ocurrido? Los nodos han comenzado a repelerse (alejarse) entre ellos a la vez que las aristas que los conectan los han intentado atraer. Así, se ha generado un movimiento que ha terminado convergiendo en una posición balanceada para cada nodo en la que aquellos personajes más conectados entre sí han quedado más cerca y los menos conectados más alejados. El objetivo de este algoritmo de distribución no es otro que colocar los nodos de forma que nos ayude a entender e interpretar el grafo mejor[^9]. Existen otros algoritmos, como puedes comprobar en el desplegable, pero este nos ofrece buenos resultados y es uno de los más extendidos - Ahora haz clic en el símbolo “T” negro que se encuentra en la cinta de opciones inferior, a la derecha de la cámara fotográfica, bajo del grafo. Has activado las etiquetas (label) de los nodos, es decir, los nombres de los personajes. Puedes modificar el tamaño, tipografía y color en el resto de opciones de la cinta
- Vamos a modificar ahora el color y el tamaño de los nodos y aristas. Para ello, ve al cuadro “Apariencia” (arriba a la izquierda) y sigue estas indicaciones:
- En Nodos-Color (símbolo de la paleta de pintura), selecciona “Partición” y escoge el atributo “función”. Gephi asigna un color distinto a cada valor del atributo, puedes modificar la paleta de colores o dejar los colores por defecto y hacer clic en “Aplicar”. Los nodos del grafo se han coloreado y también lo han hecho las aristas. Ve a la cinta de opciones inferior y deselecciona la opción “Las aristas tienen el color del nodo de origen”, su símbolo es una línea con un arcoiris. Ahora las aristas serán todas de un mismo color gris
- En Nodos-Tamaño (símbolo de los círculos), selecciona “Ranking” y escoge el atributo “Grado” (Gephi calcula automáticamente el grado de los nodos). Cambia el tamaño mínimo a 10 y el máximo a 40 y haz clic en “Aplicar”. Ahora los nodos tienen un tamaño relativo a su grado, es decir, a la cantidad de nodos con los que están relacionados. A mayor número de personajes con los que comparte escena un personaje -> mayor grado -> mayor diámetro
- En Aristas-Color (símbolo de la paleta de pintura), selecciona “Ranking” y escoge el atributo “Peso”. Te aparecerá un gradiente de color. Puedes cambiar la paleta de colores o dejarlo en verde y hacer clic en “Aplicar”. Ahora el color de las aristas está más o menos intenso en función de su peso, es decir, del número de escenas que comparten dos los personajes o de sus interacciones lingüísticas. Si las ves muy finas, puedes cambiar el tamaño de las aristas en la cinta de opciones inferior, están por defecto más o menos gruesas también según el peso
Seguramente te ha quedado algo muy similar esto en el caso del grafo de coaparición de personajes en escena:
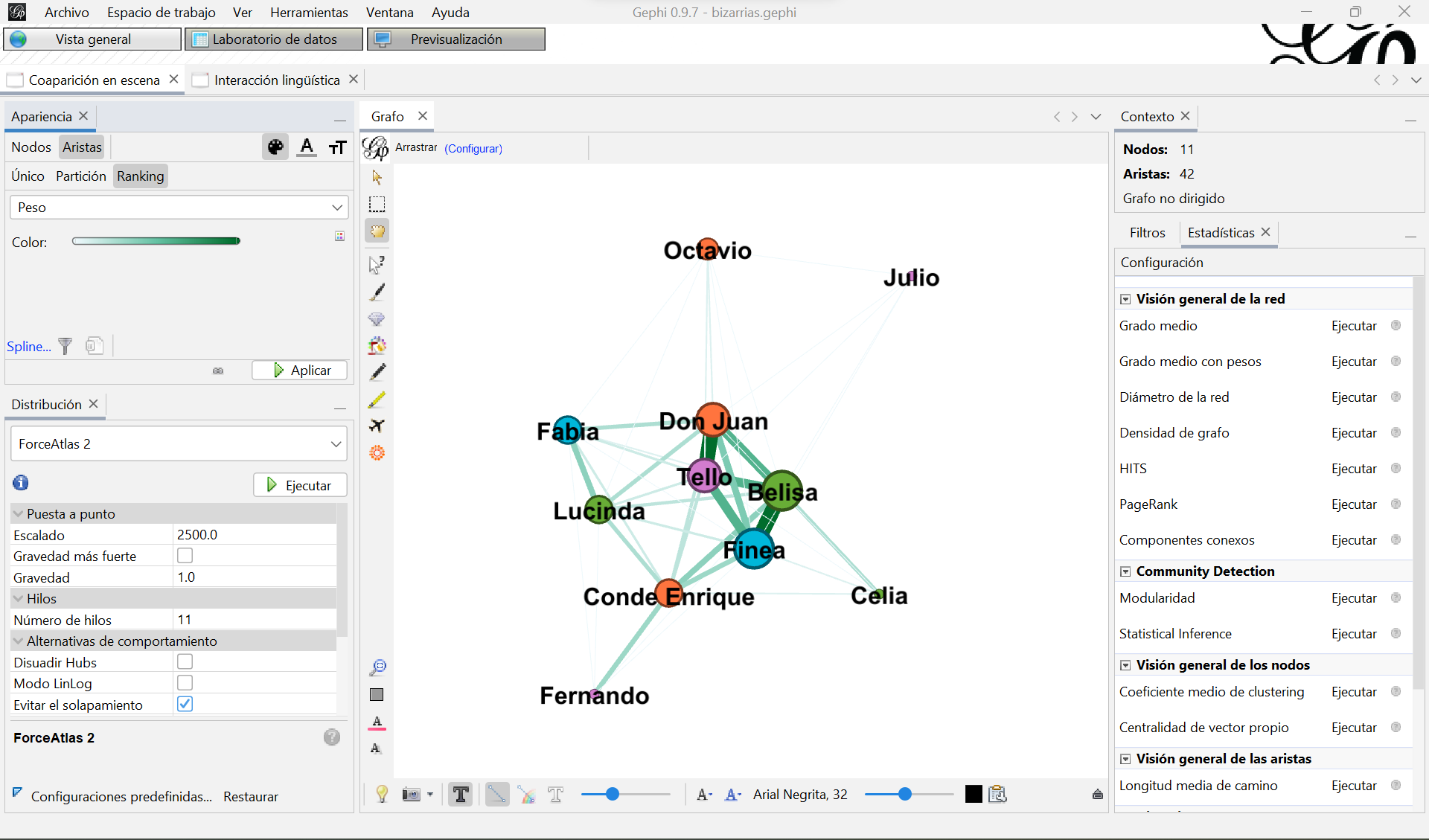
Visualización del grafo de coaparición de personajes en escena, resultado de aplicar los parámetros indicados
¡Enhorabuena! Ahora puedes ver cuáles son los personajes más relacionados (grado) por el tamaño de los nodos, la función de estos personajes por el color de los nodos y la cantidad de veces que dos personajes coinciden en escena o interactúan entre ellos (peso) por el grosor y la intensidad de color de sus aristas. Si comparas la captura con tu vista del grafo de coaparición en escena puede que tu grafo tenga otra disposición. En realidad tus nodos y los míos están colocados en el mismo sitio y a la misma distancia, solo que están rotados en otro sentido. En el cuadro de “Distribución” puedes utilizar la opción “Rotar” y buscar una disposición que te guste más. No cambiará la distribución que creó el algoritmo ForceAtlas 2. Otras opciones que puedes explorar son “Contracción” y “Expansión”, o “Ajuste de etiquetas” si alguna está superpuesta.
Una vez repitas los pasos también en el espacio de trabajo del grafo de interacciones lingüísticas y hayas modificado su apariencia verás que en este caso las aristas tienen flechas que nos indican la dirección de las relaciones, se trata de un grafo dirigido:
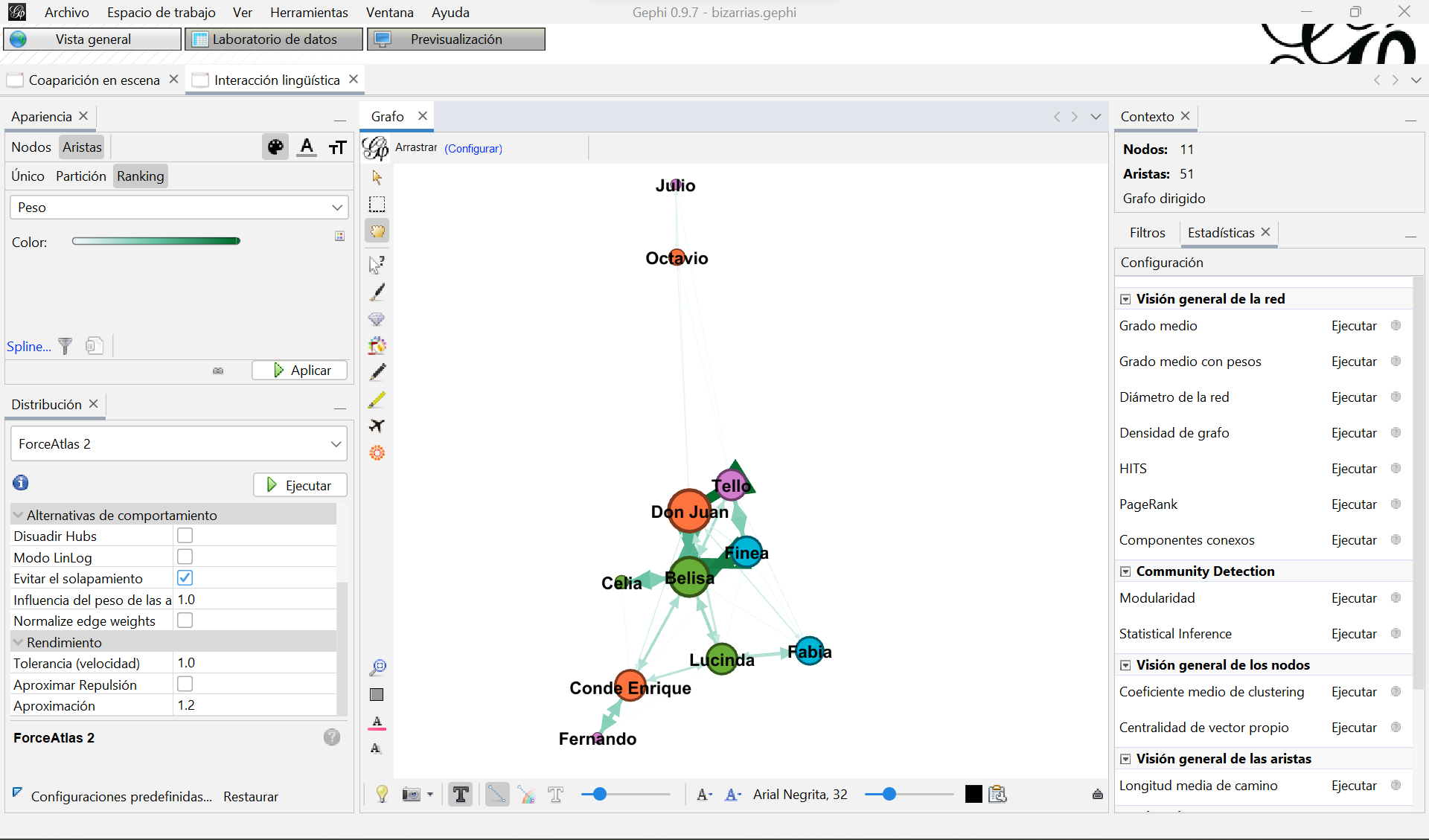
Visualización del grafo de interacciones lingüísticas entre personajes, resultado de aplicar los parámetros indicados
También puedes activar las etiquetas de las aristas, haciendo clic en la “T” blanca en la cinta de opciones de debajo del grafo. El color de las etiquetas y su tamaño deberás modificarlo en “Apariencia”, en la pestaña “Aristas-A subrayada” (color) y en la pestaña “Aristas-tT” (tamaño):
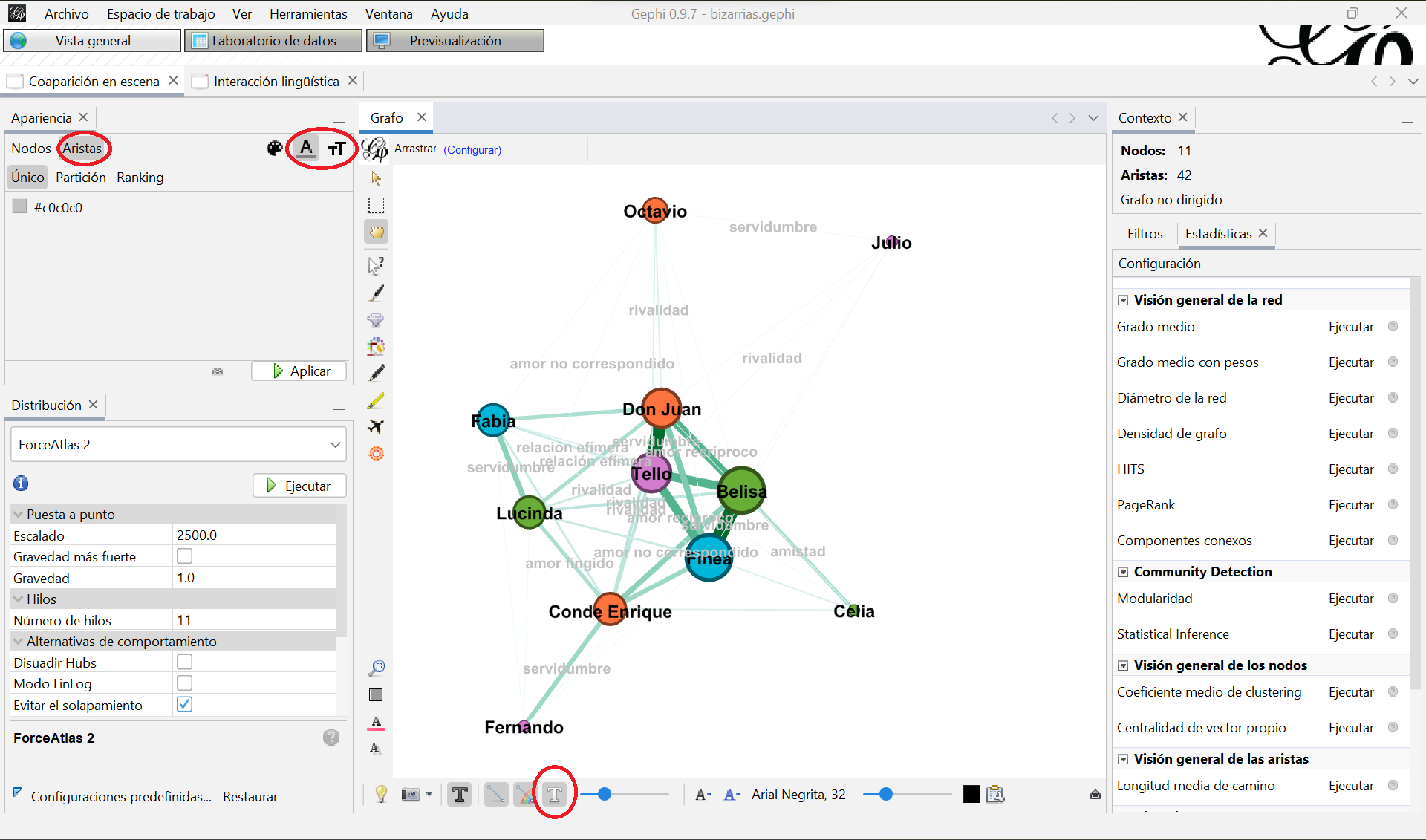
Visualización del grafo de coaparición de personajes en escena con las etiqutas de las aristas activadas
El contexto y los filtros
Nos quedan por explorar los cuadros de configuración de la derecha. El de “Contexto” nos da información sobre grafo en pantalla. Por ejemplo, en el de interacciones lingüísticas nos dice que se trata de un grafo dirigido con 11 nodos y 51 aristas.
Vamos a probar los filtros, por ejemplo, filtrando cualquiera de los grafos según el género de los personajes:
- En el cuadro “Filtros”, despliega las carpetas “Atributos” y “Partición” (dentro de la primera)
- Selecciona el atributo “género (Nodo)” y arrástralo al cuadro de “Consultas”
- Haz clic en “Mujer (45,45 %)” y en “Filtrar”
Verás algo similar a esto, un grafo solo con los personajes clasificados por ti como “Mujer”:
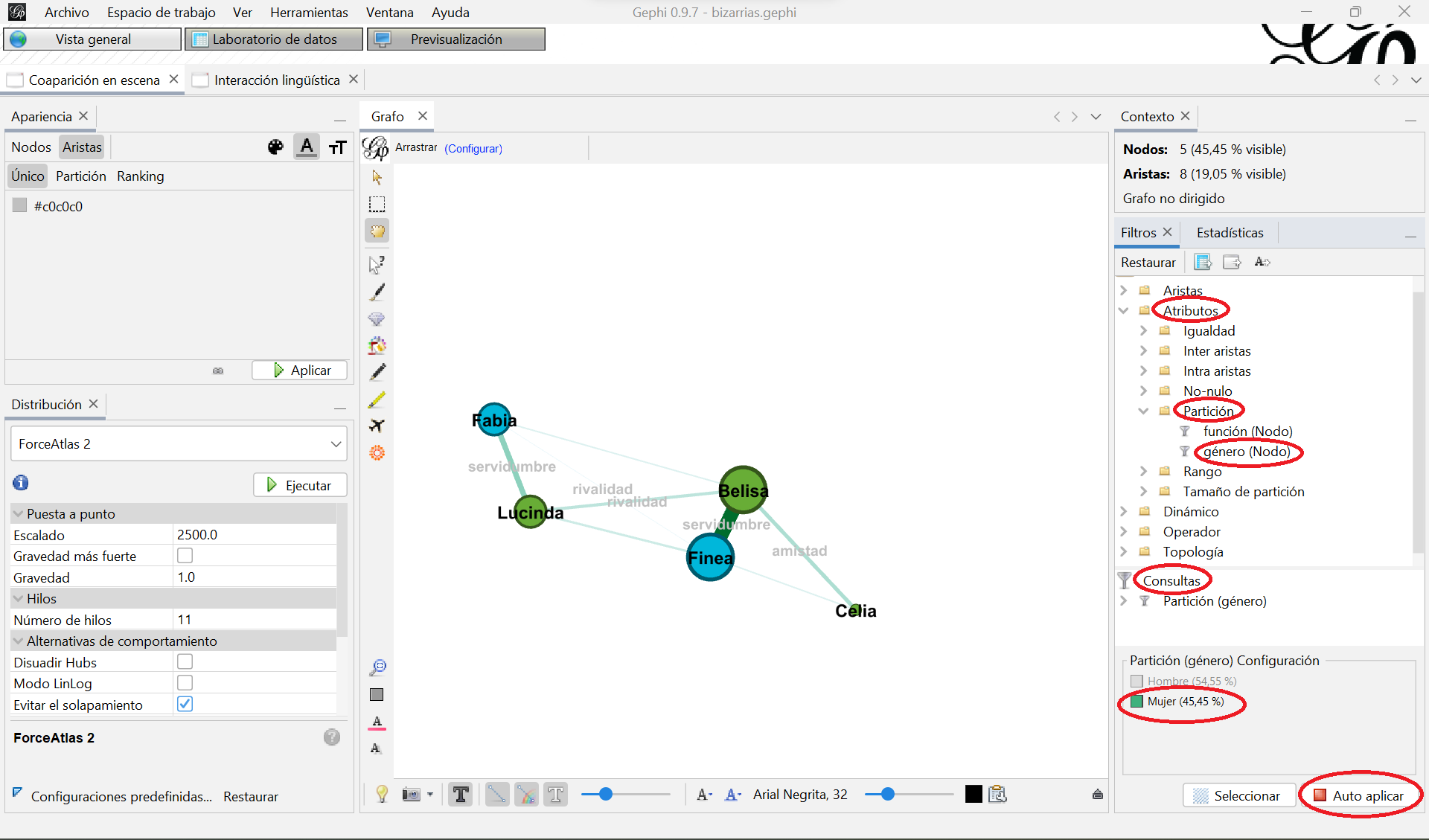{kind=link}
Grafo resultante de filtrar por el atributo “Mujer”
Puedes hacer lo mismo con los personajes “Hombre” o utilizar otro atributo para el filtrado, como la función de los personajes. Con cada filtro que apliques verás que la información del “Contexto” cambia. Para volver atrás, elimina el filtro con el botón derecho>Suprimir sobre el filtro o haciendo clic en “Restaurar”.
Medidas, métricas y algoritmos de análisis
Ahora vamos a aplicar algunas medidas en el cuadro “Estadísticas”. Te dejaré explicaciones de cada una. Gephi ha simplificado al máximo el análisis de los grafos, pues es tan fácil como hacer clic en “Ejecutar” en la medida o algoritmo que queramos implementar. Algunas de estas medidas abriran una ventana emergente al ejecutarlas, un pequeño informe que podemos descargar o opciones de configuración. Otras, simplemente añadirán columnas en nuestra tabla de nodos del Laboratorio de datos. Estos nuevos datos, generados gracias a la aplicación de medidas, nos dan más información sobre nuestro grafo, nos permiten modificar la visualización en base a ellos (son como nuevos atributos) y exportándolos podremos procesarlos en otra herramienta o programa. En esta lección no nos adentraremos ahí, pero quiero que sepas que a partir de aquí las posibilidades se multiplican.
En el apartado “Visión general de la red” lo primero que encontramos es el “Grado medio”, es decir, la media de los grados de todos los nodos del grafo. Recordemos que el grado es el número de nodos con los que un nodo está conectado. En el caso de los grafos dirigidos, obtendremos además el grado medio de entrada y el grado medio de salida. Después, el “Grado medio con pesos”, que tiene en cuenta el peso de las aristas conectadas a un nodo y no simplemente la cantidad nodos con los que se conecta. De nuevo, habrá un grado medio con pesos de entrada y un grado medio con pesos de salida. Al ejecutar estas dos estadísticas, se añadirán dos columnas nuevas en la tabla de nodos del Laboratorio de datos con los valores de grado y grado con peso de cada nodo:
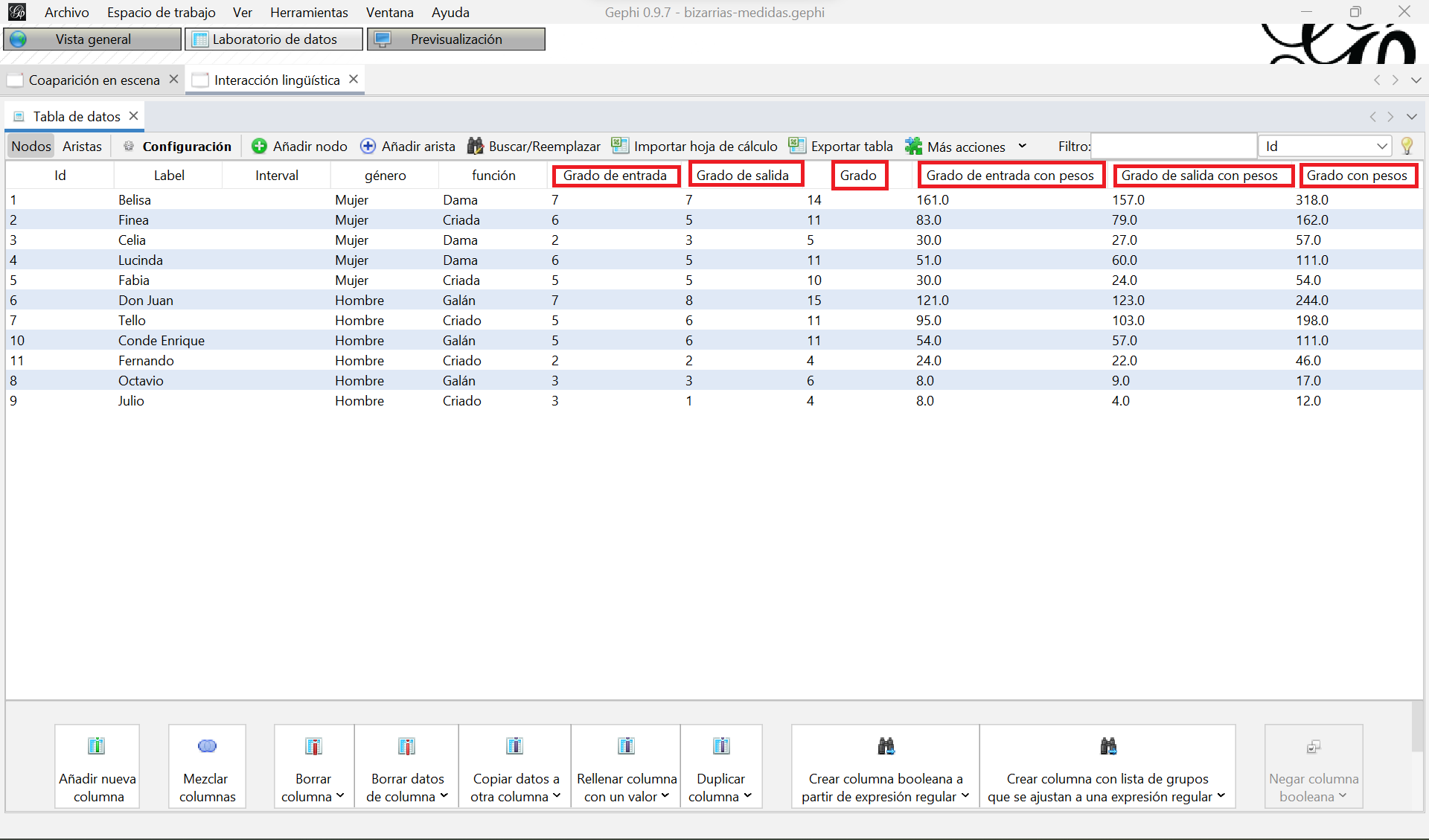
Laboratorio de datos del grafo de interacciones lingüísticas con las nuevas columnas de grado
El “Diámetro de la red” es una de las medidas de tamaño o distancia. Para entenderlo, primero has de saber que en análisis de redes se entiende por camino una secuencia de nodos conectados por aristas. Esta noción de camino nos permite calcular las métricas de distancia y tamaño de la red. Por otro lado, se entiende por distancia o longitud de un camino el número de aristas (no de nodos) que deben cruzarse para ir de un nodo a otro (siempre por el camino más corto). El diámetro.%20El-,di%C3%A1metro,-de%20un%20grafo) es, entonces, la distancia entre los nodos más alejados de una red:
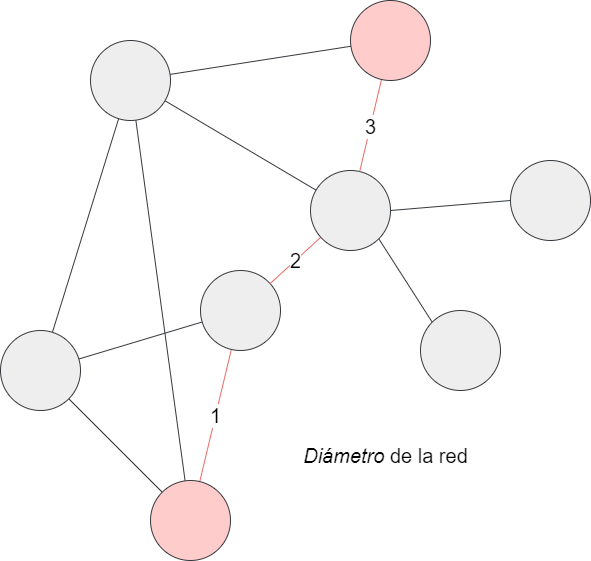
Ejemplo del diámetro de una red
Haz clic en “Ejecutar” el diámetro:
- En la ventana que se ha abierto encontrarás definiciones de las métricas de distancia: distancia media, diámetro y las medidas de centralidad de intermediación, cercanía y excentricidad. Al ejecutar esta función, no solo se calcula el diámetro sino todas esas métricas relacionadas con la distancia
- Gephi te permite normalizar las centralidades (ahora veremos lo que son) en un rango [0,1], lo que facilita después la comparación de grafos de obras distintas. Marca esta opción y haz clic en “Aceptar”
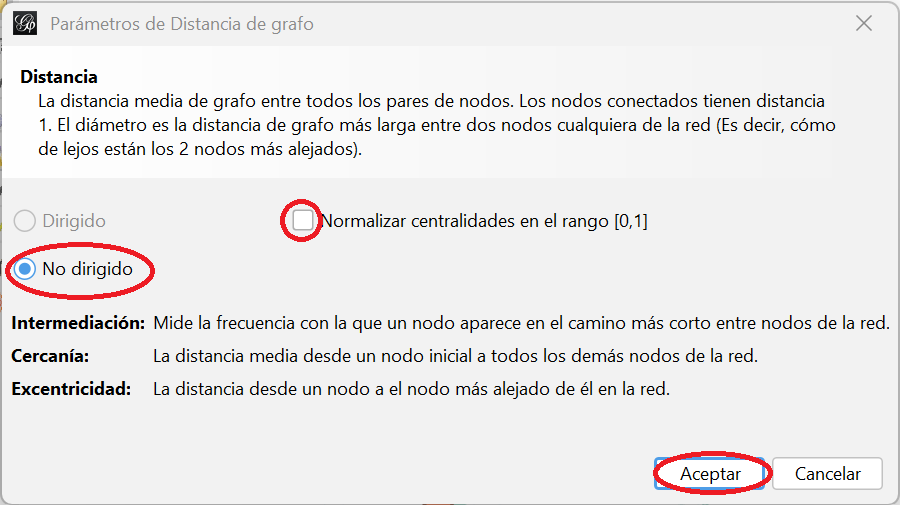
Ventana de parámetros de distancia del grafo de coaparición de personajes en escena
Si comparas el diámetro de los dos grafos verás que hay diferencias: en uno es 2 y en el otro 4. Es normal la diferencia, nos habla de que hay personajes que comparten escena pero que no interactúan entre ellos.
Si te diriges al Laboratorio de datos, verás que se han añadido varias columnas más en la tabla de nodos, ahora con los resultados de las medidas de centralidad. La centralidad en ARS tiene que ver con el lugar que ocupan los nodos en el conjunto de una red y nos ayudan a entender la importancia de los nodos dentro del sistema que analizamos[^10]. Estas son algunas de las medidas de centralidad, pero hay unas cuantas más:
- El grado o el grado con pesos pueden ser medidas de centralidad, pues valores más altos indican mayor conectividad. En ese caso, nos referimos a ellas como centraliad de grado (degree centrality) y centralidad de grado con pesos (weighted degree centrality)
- La centralidad de cercanía (closeness centrality) de un nodo se obtiene midiendo la distancia media que guarda dicho nodo con todos los demás del grafo. Dicho de otra forma, nos ayuda a encontrar el nodo más cercano a todos los demás, que no tiene por qué ser el de mayor grado (el más conectado)
- La centralidad de intermediación (betweenness centrality) de un nodo se halla calculando la cantidad de veces que dicho nodo se encuentra en el camino más corto entre todos los otros nodos. La importancia de los nodos depende, en este caso, de su labor de intermediación, de puente conector entre nodos separados. Si faltan estos nodos, la estructura de un grafo suele verse muy afectada
Por ejemplo, en la comedia con la que estamos trabajando, Las bizarrías de Belisa, ningún personaje tiene una una centralidad de intermediación normalizada demadiado alta. No hay ningún nodo que eliminándolo provoque un grafo disconexo, es decir que ciertos nodos quedan desconectados del núcleo principal.
Siguiendo en el cuadro de “Estadísticas” nos encontramos la “Densidad”. La densidad mide el nivel de conectividad total de los nodos del grafo: cuán cerca está de que todos los nodos conecten con todos los nodos. La densidad calcula la proporción de aristas que tiene una red frente al total de aristas posibles, y expresa el resultado en un rango [0,1]: cerca de 1 se dice que es un grafo denso; cerca de 0 se habla de un grafo disperso. Haz clic en “Ejecutar”:
- Se abrirá una ventana que nos permite elegir seleccionar si nuestro grafo es dirigido o no dirigido
- Selecciona tu opción haz clic en “Aceptar”
Nuevamente, hay diferencia entre la densidad del grafo de coaparición en escena y la del grafo de interacciones lingüísticas por el mismo motivo: hay personajes que comparten escena pero que no intercambian palabra.
Vamos a saltar ahora al apartado “Community Detection”. En ARS se entiende por comunidad un grupo de nodos que están densamente interconectados entre sí y que a su vez están poco conectados con los nodos de otra comunidad:
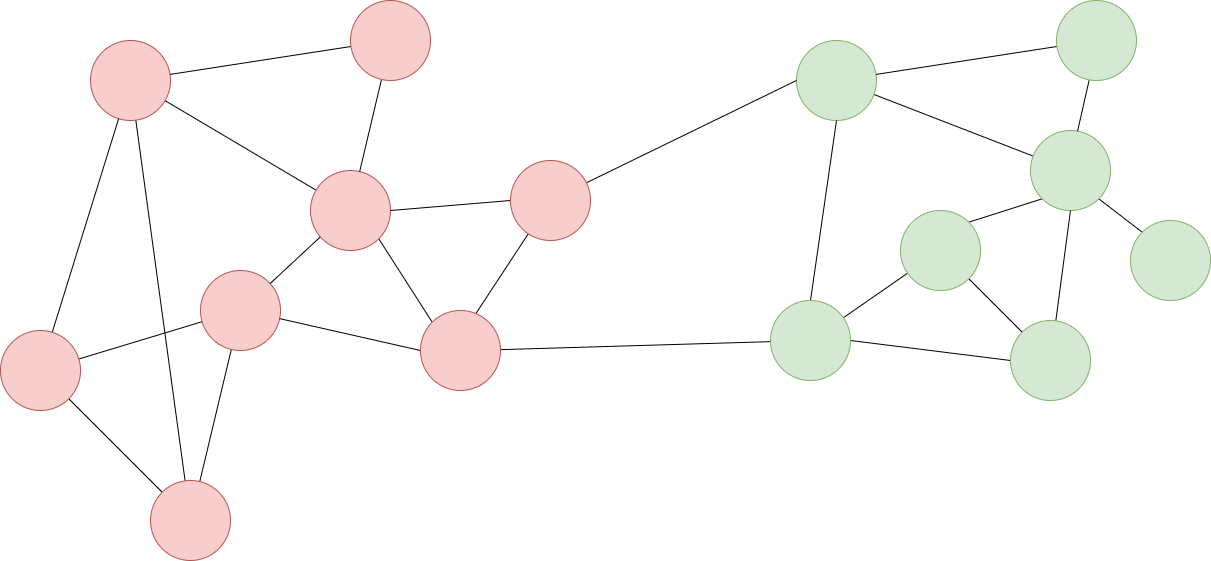
Ejemplo de grafo con comunidades coloreadas en dos colores distintos
Las distintas comunidades de un grafo se hayan implementando un algoritmo de modularidad que Gephi incorpora, que podemos utilizar simplemente haciendo clic en “Ejecutar”.
- Se abrirá una ventana de Parámetro de Modularidad. No es necesario que modifiques nada: utiliza la opción de aleatoriedad y de incorporar los pesos de las aristas, y deja la resolución en 1 (modularidad estándar)
- El algoritmo va a numerar las comunidades a partir del 0, pero si quieres que comience a contar en 1, simplemente cambia la opción “Classes start at”: 1 y dale a “Aceptar”
Si implementas el algoritmo de modularidad en el grafo de interacciones lingüísticas directas comprobarás que se detectan 3 comunidades de nodos. Puedes ver qué comunidad ha sido asignada a cada nodo en la nueva columna del Laboratorio de datos. Para visualizar las comunidades en el grafo, ve al cuadro “Apariencia” de la Vista general y cambia el color de los nodos eligiendo la partición “Modularity Class”, haciendo clic en “Aplicar” con los colores por defecto o modificándolos. Debería quedarte un grafo similar a este:
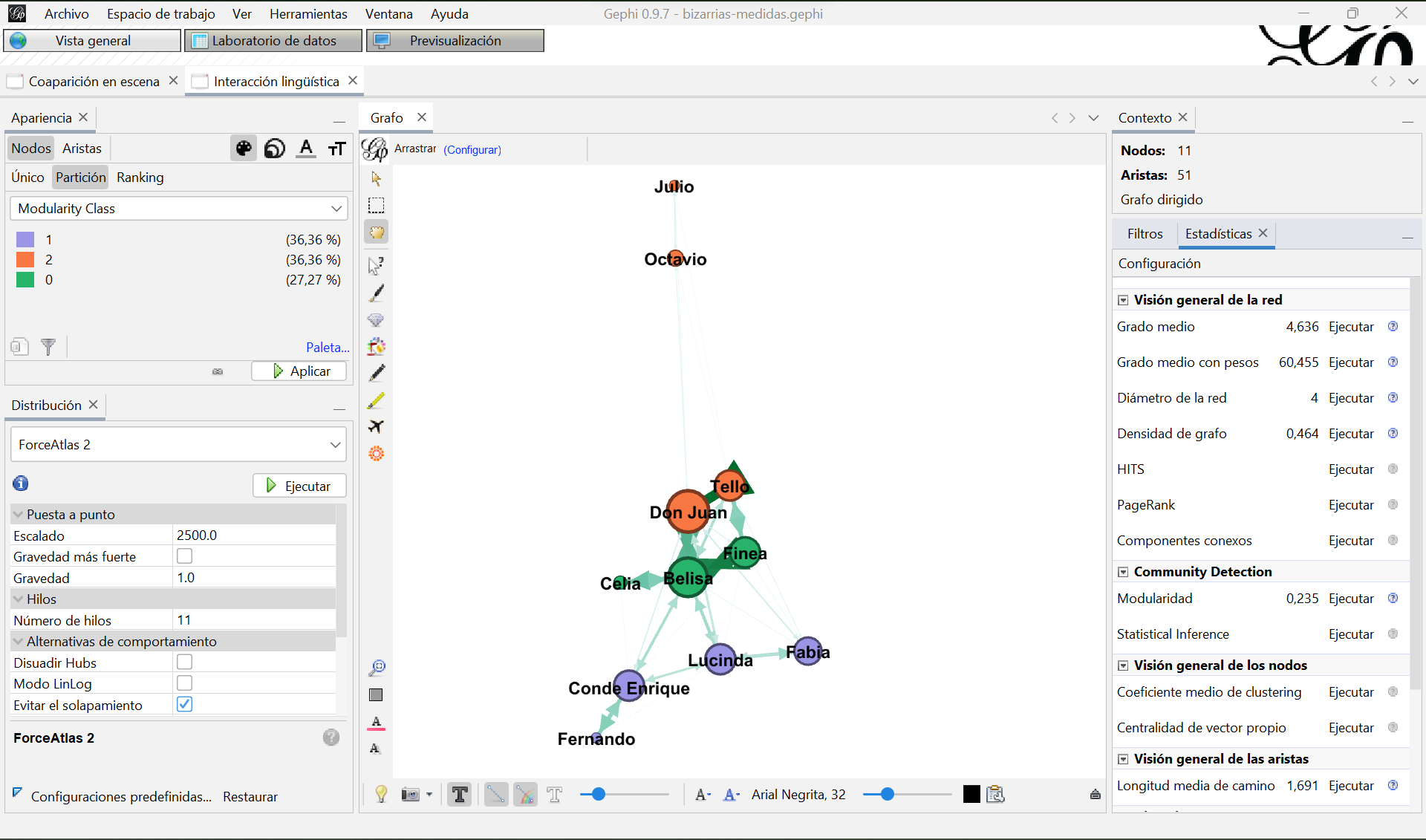
Grafo de interacciones lingüísticas con los nodos coloreados según la comunidad a la que pertenecen, detectadas gracias al algoritmo de modiularidad
Cuando has desplegado el menú de “Partición” en el color de los nodos habrás visto que han aparecido muchas más opciones de las que teníamos al principio, y es que puedes utilizar los resultados de las medidas que has ido implementando para colorear y dar tamaño a los nodos y aristas. Por ejemplo, utilizando la opción “Ranking” puedes poner el diámetro de los nodos en función de su centralidad de intermediación y el color graduado en intensidad según su grado. Esto te permitiría a golpe de vista comparar la diferencia entre ambas medidas para cada nodo. ¿Ves cómo las opciones se multiplican?
La “Previsualización”: últimos ajustes y exportación de visualizaciones
Para finalizar con el trabajo en Gephi, vamos a exportar alguna visualización en la pestaña de Previsualización. Al entrar, verás un cuadro grande en gris vacío: es donde aparecerá el grafo una vez introduzcas los parámetros en el cuadro de configuración de la izquierda. Haz una prueba: entra a la previsualización del espacio de trabajo “Coaparición en escena”, haz clic en “Refrescar” y mira cómo se ve tu grafo con los parámetros que vienen por defecto. Estarás viendo el mismo grafo de la Vista genera pero con algunos ajustes de visualización. Ahora modifica estos parámetros y deja el resto como están por defecto:
- Nodos:
- Ancho de borde: 0.0
- Etiquetas de nodos:
- Mostrar etiqueta: activado
- Fuente: Arial 24 Sin Formato
- Tamaño proporcional: desactivado
- Aristas:
- Grosor: 20
- Reescalar pesos: activado
- Color: original (es decir, el gradiente que pusimos en la vista general)
- Etiquetas de aristas
- Mostrar etiquetas: activado
- Fuente: Arial 14 Sin Formato
- Color: específico: #000000
Haz clic en “Refrescar” de nuevo y debería aparecerte un grafo similar a este, quizá con otra rotación:
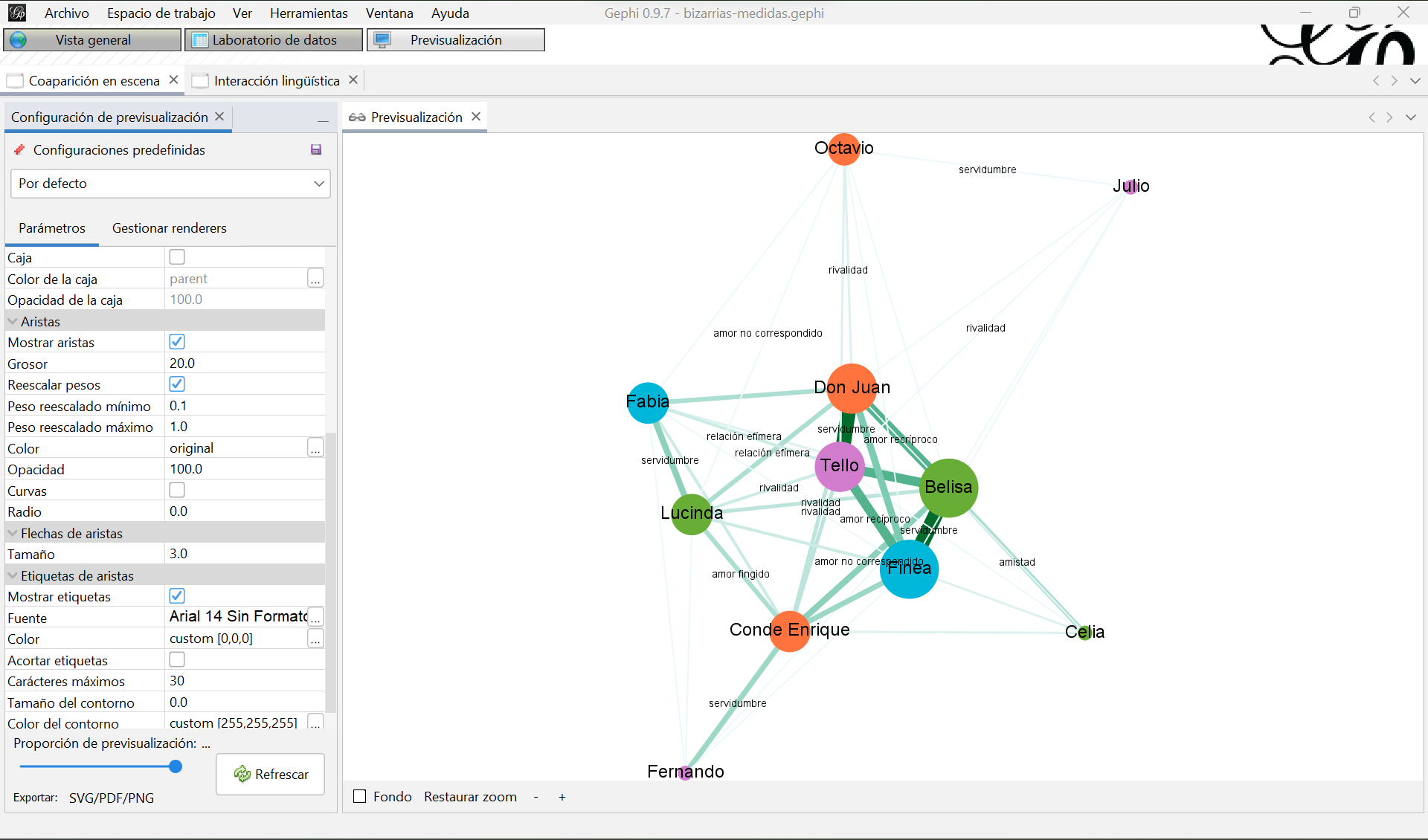
Visualización final del grafo de coaparición de personajes en escena
Ahora puedes exportar la visualización hacienco clic en “Exportar SVG/PDF/PNG” abajo a la izquierda. Como bien deduces, esos son los tres formatos que permite exportar Gephi. PNG es un buen formato de imagen, pero Gephi exporta en baja resolución y no se ven demadiado claros los grafos. Mi recomendación es que exportes los grafos en SVG, los abras con un programa que lea imágenes vectoriales (por ejemplo los programas de código abierto Inkscape o LibreOffice Draw) y los vuelvas a exportar en PNG con buena resolución. Los navegadores también leen SVG, depende del uso que vayas a darle a tus grafos puede que te convenga mantenerlos en formato vectorial.
Si repites lo mismo con el grafo de interacción lingüística directa ahora podrás seleccionar si quieres aristas curvas (que marcan la dirección en el sentido de las agujas de un reloj) o rectas con flechas. Por ejemplo, reutiliza los parámetros anteriores y modifica estos:
- Aristas:
- Curvas: desactivado
- Flechas de aristas:
- Tamaño: 3.0
- Etiquetas de aristas:
- Mostrar etiquetas: desactivado
Haz clic en “Refrescar” y verás algo así, con los nodos coloreados según su comunidad si antes aplicaste este cambio en la vista general:
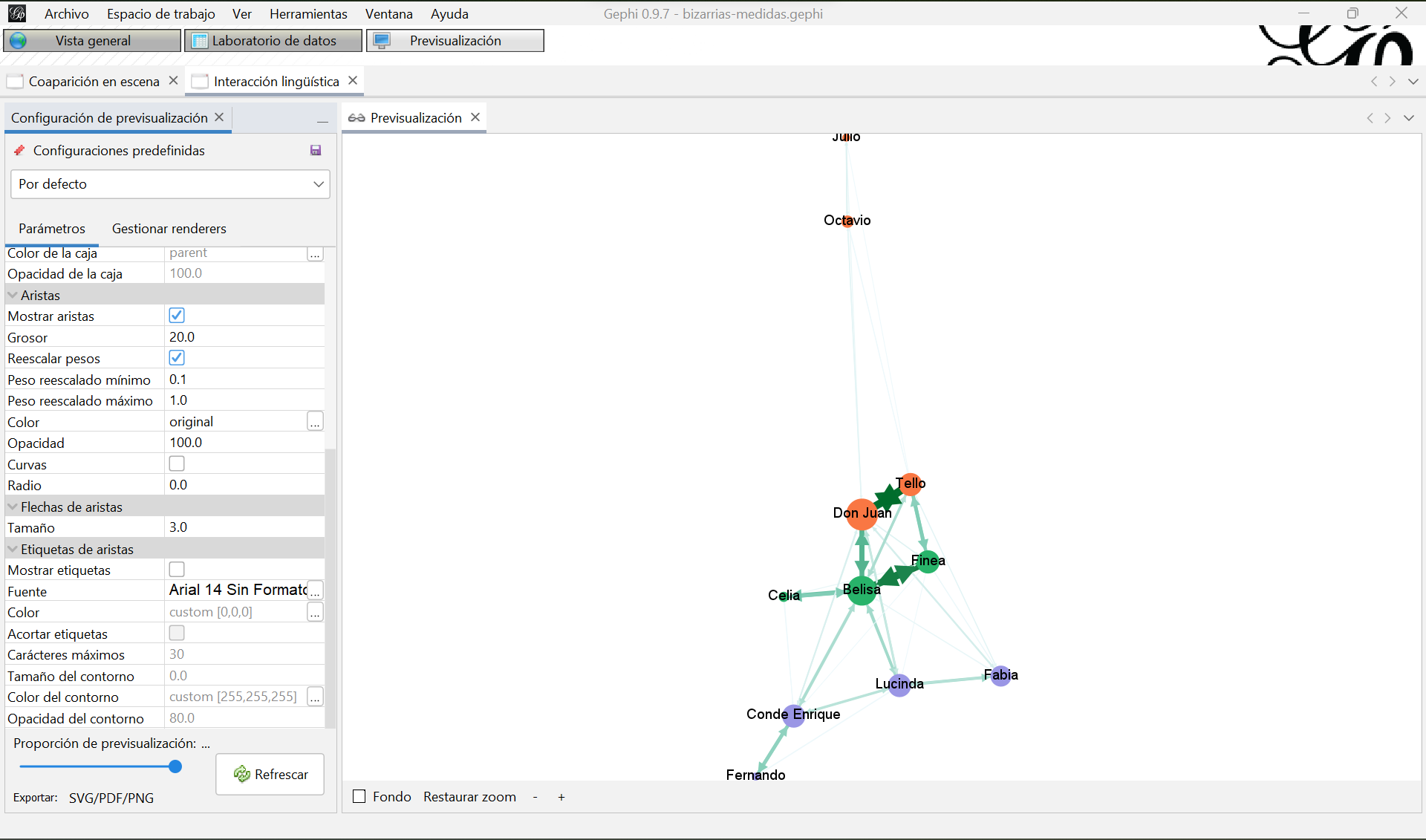
Visualización final del grafo de interacciones lingüísticas entre personjes
4. Interpretación de los resultados
Hemos generado visualizaciones y aplicado medidas a los grafos construidos gracias a los datos que primero extrajimos de Las bizarrías de Belisa. Las visualizaciones ya nos pueden ayudar en el análisis de una obra e ilustrar un análisis más tradicional, pero si has llegado hasta aquí seguramente te interesa tener en consideración los datos obtenidos de la aplicación de medidas, métricas y algoritmos.
En esta lección no vamos a explorar la interpretación de los datos de este texto en concreto, pero creo que es importante anotar que deben analizarse cuidadosamente y no utilizarse para confirmar hipótesis sin una valoración estadítica crítica. En realidad, todo el proceso que has llevado a cabo, desde la elección del corpus hasta la creación de visualizaciones, debe considerarse parte del proceso crítico de investigación. Piensa, por ejemplo, en la tediosa extracción de datos y todas las decisiones interpretativas que has tomado. ¡Cualquier otra decisión variaría los resultados! Es por ello que debes insistir en ser consistente con el procedimiento y criterios de análisis que elijas, y comunicarlos con detalle para contextualizar tus resultados.
De cara al análisis de resultados de las medidas y métricas, mi recomendación es que, después de aplicar las estadísticas que te interesen, vayas al Laboratorio de datos y hagas clic en “Exportar tabla”. Podrás exportar tu tabla de nodos con las nuevas columnas en formato CSV. Este archivo podrás analizarlo y procesar sus datos con herramientas como, por ejemplo, el lenguaje de progamación R (enfocado al análisis estadístico) o un programa de hojas de cálculo. Esto te será especialmente útil si llevas a cabo un análisis de redes sociales comparado de un corpus de dos o más obras.
Mira por ejemplo un gráfico en el que se compara el grado con pesos normalizado de los primeros galanes y primeras damas de ocho comedias del Siglo de Oro español, entre las que se incluye la que hemos utilizado en esta lección:
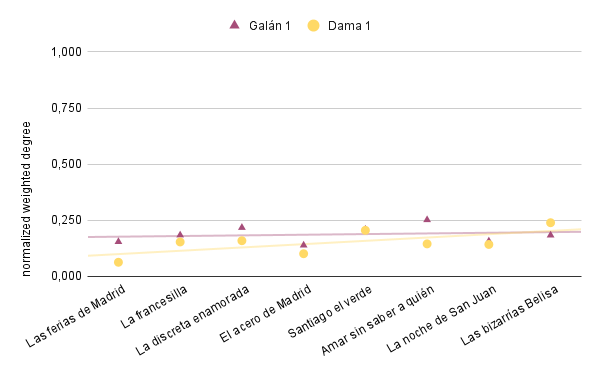
Gráfico comparativo del grado con pesos normalizado de los primeros galanes y primeras damas de ocho comedias del siglo de oro (Merino Reacalde, 2022
Recapitulación final
Terminemos esta lección anotando las cuestiones elementales que deberás tener en cuenta cuando realices un análisis de redes sociales de textos teatrales:
- Divide el proceso en cuatro partes diferenciadas:
- Creación del corpus
- Extracción y estructuración de datos
- Visualizaciones y análisis
- Interpretación de los resultados (datos y grafos)
- Documenta el proceso y la toma de decisiones. Sé consistente en ello. Procura basarte siempre en criterios prestablecidos, provenientes de otras investigaciones o diseñados por ti en función de tus objetivos y del corpus de análisis. Me refiero, por ejemplo, a los criterios de anotación de interaciones lingüísticas entre personajes, a las categorías concretras y cerradas para los atributos de los nodos y las aristas, etc.
- Procura guardar tus datos finales en formatos abiertos que garanticen el acceso a los datos a largo plazo, como el CSV. Si únicamente guardas tus datos en formato excel (
.xlxs) o en la extensión del propio Gephi (.gephi) puede que tu archivo termine corrompiéndose o fallando. Un CSV tiene una vida más larga, es más fácil de preservar y rápidamente puedes importarlo, transformarlo y volver sobre tus datos para reconstruir tus grafos y análisis - Cuando generes visualizaciones anota los parámetros que utilizaste (tamaño de los nodos, colores, algoritmo de distribución, etc.). Es importante que acompañes tus resultados de esta información, pues ayuda a entender y contextualizar las representaciones
Y sobre todo, especialmente en relación al uso de Gephi, no tengas miedo de probar y explorar todas las posibilidades que ofrece el análisis de redes a la hora de estudiar la literatura teatral.
Notas
[^1] En realidad se conoce como análisis de redes al campo de estudio general, pero lo apellidamos sociales cuando los elementos que se estudian son personas y se implementan conceptos y teorías que provienen de la sociología.
[^2] Sobre el uso del ARS en historia ver Rodríguez Treviño, Julio César. «Cómo utilizar el Análisis de Redes Sociales para temas de historia». Signos Históricos 29 (2013): 102-41.
[^3] En mi Trabajo de Fin de Máster (origen de esta lección) puede consultarse una revisión exahustiva de los trabajos en literatura que han implementado el análisis de redes: Merino Recalde, David. «El sistema de personajes de las comedias urbanas de Lope de Vega. Propuesta metodológica y posibilidades del análisis de redes sociales para el estudio del teatro del Siglo de Oro». Trabajo de Fin de Máster, Universidad Nacional de Educación a Distancia, 2022. http://e-spacio.uned.es/fez/view/bibliuned:master-Filologia-FILTCE-Dmerino.
[^4] Cabe mencionar, por ejemplo, el trabajo del grupo QuaDramA de la Universität zu Köln y de la Universität Stuttgart. En 2022 organizaron un workshop bajo el título “Computational Drama Analysis: Achievements and Opportunities”, en cuyo call for papers destacaban al ARS como una de las metodologías de su interés (ver https://quadrama.github.io/blog/2022/03/14/comp-drama-analysis-workshop).
[^5] Si no conoces la obra, quizás te ayude consultar su ficha de la Base de datos ARTELOPE, en donde encontrarás un resumen, anotaciones pragmáticas sobre la obra, caracterizaciones de personajes y espacios, etc. Está disponible en la siguiente direción: https://artelope.uv.es/basededatos/browserecord.php?-action=browse&-recid=53#bibliograficos.
[^6] Existen otros programas y herramientas de análisis de redes que podemos mencionar. Por ejemplo, Cytoscape es otro programa de código abierto y libre descarga, muy utilizado en bioinformática. También hay aplicaciones web: Palladio, desarrollada por el Humanities+Design Research Lab de la Standford University y pensada para la investigación histórica; o ONODO, una aplicación muy sencilla que permite crear redes e implementar medidas fácilmente.
[^7] Esta lección se ha preparado con la versión 0.9.7 de Gephi. En 2022 (hasta octubre), y tras cinco años sin actualizaciones, se han publicado 5 versiones nuevas corrigiendo errores (bug fixes) y añadiendo mejoras. Por ejemplo, desde la versión 0.9.3 ya no es necesario instalar Java para que Gephi funcione en Windows y Linux, lo que causaba numerosos problemas en Windows. Puedes leer más acerca de las actualizaciones de Gephi en https://gephi.wordpress.com/2022/05/11/transition-to-semantic-versioning/ y en https://github.com/gephi/gephi/releases.
[^8] Por ejemplo, este estupendo videotutorial en 5 partes de Salvador Sánchez, disponible en YouTube: https://www.youtube.com/playlist?list=PLIvIcfwy1T6IDiW3K10TplK3rvdwMLOb2. O la introducción rápida a Gephi de José Manuel Galán, también en Youtube: https://www.youtube.com/watch?v=sX5XYec4tWo
[^9] Si te interse conocer más sobre cómo funciona ForceAtlas 2, te recomiendo este artículo de sus desarrolladores: Jacomy, Mathieu, Tommaso Venturini, Sebastien Heymann, y Mathieu Bastian. «ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software». PLoS ONE 9, n.º 6 (2014): e98679. https://doi.org/10.1371/journal.pone.0098679.
[^10] Importancia es un concepto algo complejo. Debemos diferenciar la importancia de los nodos según su centralidad (una importancia cuantitativa derivada del ARS) y la importancia que le otorgamos a los personajes (una importancia cualitativa, por ejemplo: protagonista, secundario, terciario, etc.). La correlación entre estos dos tipos de importancia no siempre se da, como demuestran Santa María Fernández et al. en un estudio de 2020. Te recomiendo este artículo para explorar en profundidad las implicaciones de las medidas de centralidad: Santa María Fernández, Teresa, José Calvo Tello, y Concepción María Jiménez Fernández. «¿Existe correlación entre importancia y centralidad? Evaluación de personajes con redes sociales en obras teatrales de la Edad de Plata». Digital Scholarship in the Humanities 36, n.º June (2020): i81-i88. https://doi.org/10.1093/llc/fqaa015.
Referencias
Escobar Varela, Miguel. Theater as Data: Computational Journeys into Theater Research. Ann Arbor, MI: University of Michigan Press, 2021. https://doi.org/10.3998/mpub.11667458.
Jockers, Matthew Lee. Macroanalysis: Digital Methods and Literary History. University of Illinois Press, 2013.
Merino Recalde, David. «El sistema de personajes de las comedias urbanas de Lope de Vega. Propuesta metodológica y posibilidades del análisis de redes sociales para el estudio del teatro del Siglo de Oro». Trabajo de Fin de Máster, Universidad Nacional de Educación a Distancia, 2022. http://e-spacio.uned.es/fez/view/bibliuned:master-Filologia-FILTCE-Dmerino.
Moretti, Franco. Distant Reading. London - New York: Verso, 2013.
———. Graphs, Maps, Trees: Abstract Models for a Literary History. London: Verso, 2005.
———. «Network Theory, Plot Analysis». Stanford Literary Lab Pamphlets 2 (2011): 1-11.