This is the draft website for Programming Historian lessons under review. Do not link to these pages.
For the published site, go to https://programminghistorian.org
Contents
- Introduction
- Requirements
- Learning Goals
- Arquivo.pt: the Portuguese web-archive
- Conta-me Histórias (Tell Me Stories)
- Installation
- Conclusions
- Awards
- Bibliography
Introduction
Over the centuries, communication has evolved in parallel with the evolution of mankind. Communication, which used to take place through physical means, is now digital and has an online presence. The “fault” lies with the Web, which since the late 90s of the last century has become the main source of information and communication in the 21st century. However, about 80% of the information available on the web disappears or is changed within just 1 year. This leads to the loss of fundamental information to document the events of the digital age.
The shift to an internet-based communication paradigm has forced a profound change in the way published information is preserved. Web archives assume particular relevance by preserving information published online since the 1990s.
Despite recent advances in preserving archived information from the web, the problem of efficiently exploiting the historical heritage preserved by these archives remains unsolved due to the huge amounts of historical data archived over time and the lack of tools that can automatically process this volume of data. In this context, timelines (automatic temporal summarization systems) emerge as the ideal solution for the automatic production of summaries of events over time and for the analysis of the information published online that document them, as is the case of news.
In this tutorial, we intend to show how to explore Arquivo.pt, the Portuguese web-archive, and how to automatically create summaries of past events from historical web archived content. More specifically, we will demonstrate how to obtain relevant results by combining the use of the Arquivo.pt API with the use of Conta-me Histórias (Tell me Stories), a system that allows the automatic creation of temporal narratives about any news subject. To accomplish this goal we provide a jupyter notebook that users can use to interact with both tools.
In the first part of the tutorial, we will briefly present the search and access functions made available by Arquivo.pt. We will demonstrate how they can be used automatically by invoking the methods made available by the Arquivo.pt API (Application Programming Interface) through simple and practical examples. The automatic search for words in pages archived over time is the base service to rapidly develop innovative computer applications, which allow exploring and taking better advantage of the historical information preserved by Arquivo.pt, as is the case of the project Tell me Stories.
In the second part, we resort to Tell Me Stories to exemplify the process of temporal summarization of an event. In this sense, we will demonstrate how users can obtain summarized historical information on a given topic (Jorge Sampaio, former president of the republic) involving news from the past preserved by Arquivo.pt. Such an infrastructure allows users to access a set of historical information from web pages that most likely no longer exist in what we conventionally refer to as the current web.
Video that summarizes this tutorial
Here is a video that summarizes this tutorial.
Requirements
Participation in this tutorial assumes basic programming knowledge (namely Python) as well as familiarity with python package installation (via git) and API consumption. The code execution presupposes the use of the anaconda jupyter. For an installation of this software we recommend the tutorial Introductions to Jupyter Notebooks or alternatively the use of Google Colab.
Learning Goals
At the end of this tutorial participants should be able to:
- extract relevant information from Arquivo.pt making use of the Arquivo.pt API (Full-text & URL search);
- know how to use the Tell Me Stories package (https://github.com/LIAAD/TemporalSummarizationFramework) in the context of automatic temporal summarization of events from large volumes of data preserved in the Portuguese Web Archive.
Arquivo.pt: the Portuguese web-archive
The Arquivo.pt is a free public service provided by Fundação para a Ciência e a Tecnologia I.P., which allows anyone to search and access historical information preserved on the Web since the 1990s.
About 80% of the information available on the Web disappears or is changed within just 1 year. This leads to the loss of fundamental information for documenting events in the digital age.
This video briefly introduces Arquivo.pt.
Contributions
Arquivo.pt contains billions of files collected over time from multi-lingual websites documenting national and international events.
The search services provided by Arquivo.pt include full text search, image search, version history listing, advanced search and application programming interfaces (API) that facilitate the development of value added applications by third parties.
Over the years, Arquivo.pt has been used as a resource to support research work in areas such as the Humanities or Social Sciences. Since 2018, Arquivo.pt Awards annually distinguishes innovative works based on the historical information preserved by Arquivo.pt. Researchers and citizens have been made aware of the importance of preserving information published on the web through free training sessions, for example about the use of APIs provided by Arquivo.pt.
All the software developed is available as free open source projects and has been documented through technical and scientific articles since 2008. In the course of its activities, Arquivo.pt generates data that may be useful to support new research work, such as the list of Portuguese Government Pages on social networks or political party websites. These data are available in open access.
This video details the public services provided by Arquivo.pt. You can also access the presentation slides directly. To know more details about the services provided by the Arquivo.pt consult:
- New ways of searching the past (module A) of the “Training about Web preservation” program of Arquivo.pt.
How can I use Arquivo.pt?
The Arquivo.pt service is available from the following links:
- User interfaces in Portuguese and English to access the search service for pages, images and version history
- Information website about the Archive.pt
- Documentation about the APIs of Arquivo.pt
How does the automatic search via API work?
Periodically, Arquivo.pt automatically collects and stores information published on the Web. Arquivo.pt’s hardware infrastructure is housed in its own data center and managed by dedicated full-time staff.
The preservation workflow is performed through a large-scale distributed information system. The stored web information is automatically processed to perform research activities on Big Data through a distributed processing platform for unstructured data (Hadoop), e.g. for automatic web spam detection or to assess web accessibility for people with disabilities.
Search and access services via Application Programming Interfaces (APIs) allow researchers to take advantage of this processing infrastructure and the preserved historical data without having to address the complexity of the system that supports Arquivo.pt. This video presents the Arquivo.pt API (Full-text & URL search). Again, you can also access the presentation slides directly.
In this tutorial we will only cover the use of the Arquivo.pt API. However, Arquivo.pt also provides the following APIs:
- Image Search API v1.1 (beta version)
- CDX-server API (URL search): international standard
- Memento API (URL search): international standard
For details about all APIs provided by Arquivo.pt see the training contents available at:
- Module C: Automatic access and processing of preserved Web information through APIs of the “Training about Web preservation” program of Arquivo.pt.
Usage
Next, we will present examples of how to use the Arquivo.pt API (Full-text & URL search) to automatically search archived web pages between certain time intervals.
As a use case, we will perform searches about Jorge Sampaio (1939-2021) who was Mayor of Lisbon (1990-1995) and President of the Portuguese Republic (1996-2006).
Definition of search parameters
The query parameter defines the words to search for: “Jorge Sampaio”.
To make it easier to read the obtained search results we will limit them to a maximum of 5 through the maxItems parameter.
All available search parameters are defined in the Request Parameters section of the Arquivo.pt API documentation.
import requests
query = "jorge sampaio"
maxItems = 5
payload = {'q': query,'maxItems': maxItems}
r = requests.get('http://arquivo.pt/textsearch', params=payload)
print("GET",r.url)
Browse the obtained results of Arquivo.pt
The following code shows the fetched search results in their original format (JSON):
import pprint
contentsJSon = r.json()
pprint.pprint(contentsJSon)
Summary of the results obtained
You can extract the following information for each result:
- title (
titlefield); - address to the archived content (
linkToArchivefield); - date of archive (
tstampfield) - text extracted from page (
linkToExtractedTextfield)
All the fields obtained as response to available searches are defined in the Response fields of the Arquivo.pt API documentation section.
for item in contentsJSon["response_items"]:
title = item["title"]
url = item["linkToArchive"]
time = item["tstamp"]
print(title)
print(url)
print(time)
page = requests.get(item["linkToExtractedText"])
#note a existencia de decode para garantirmos que o conteudo devolvido pelo Arquivo.pt (no formato ISO-8859-1) e impresso no formato (UTF-8)
content = page.content.decode('utf-8')
print(content)
print("\n")
Define search time interval
One of the assets of Arquivo.pt is to provide access to historical information published on the Web over time.
In the process of accessing information, users may define the temporal interval of the archived dates of the pages to be searched, by specifying the dates in the from and to API search parameters.
The dates specified must follow the format: year, month, day, hour, minute and second (aaaammdddhhmmss), for example the date March 9, 1996 would be represented by:
- 19960309000000
The following code performs a search for “Jorge Sampaio” over pages archived between March 1996 and March 2006, the period during which Jorge Sampaio was President of the Portuguese Republic.
query = "jorge sampaio"
maxItems = 5
fromDate = 19960309000000
toDate = 20060309000000
payload = {'q': query,'maxItems': maxItems, 'from': fromDate, 'to': toDate}
r = requests.get('http://arquivo.pt/textsearch', params=payload)
print("GET",r.url)
print("\n")
contentsJSon = r.json()
for item in contentsJSon["response_items"]:
title = item["title"]
url = item["linkToArchive"]
time = item["tstamp"]
print(title)
print(url)
print(time)
page = requests.get(item["linkToExtractedText"])
#note a existencia de decode para garantirmos que o conteudo devolvido pelo Arquivo.pt (no formato ISO-8859-1) e impresso no formato (UTF-8)
content = page.content.decode('utf-8')
print(content)
print("\n")
Restrict search to a particular Web site
If users are only interested in the historical information published by a certain website, they can restrict the search by specifying the search parameter of the siteSearch API.
The following code performs a search for “Jorge Sampaio” on pages archived only from the website with the domain “
query = "jorge sampaio"
maxItems = 5
fromDate = 19960309000000
toDate = 20060309000000
siteSearch = "www.presidenciarepublica.pt"
payload = {'q': query,'maxItems': maxItems, 'from': fromDate, 'to': toDate, 'siteSearch': siteSearch}
r = requests.get('http://arquivo.pt/textsearch', params=payload)
print("GET",r.url)
print("\n")
contentsJSon = r.json()
for item in contentsJSon["response_items"]:
title = item["title"]
url = item["linkToArchive"]
time = item["tstamp"]
print(title)
print(url)
print(time)
page = requests.get(item["linkToExtractedText"])
#note a existencia de decode para garantirmos que o conteudo devolvido pelo Arquivo.pt (no formato ISO-8859-1) e impresso no formato (UTF-8)
content = page.content.decode('utf-8')
print(content)
print("\n")
Restrict search to a certain type of file
Besides web pages, Arquivo.pt also preserves other file formats commonly published online, such as PDF documents.
Users can define the type of file to be searched by specifying the API search parameter type.
The following code performs a search for “Jorge Sampaio”:
- on files of type PDF
- archived only from the website with the domain “www.presidenciarepublica.pt”
- between March 1996 and March 2006
and presents the results obtained. When the user opens the address of the archived content provided by the linkToArchive response field, he will have access to the PDF file.
query = "jorge sampaio"
maxItems = 5
fromDate = 19960309000000
toDate = 20060309000000
siteSearch = "www.presidenciarepublica.pt"
fileType = "PDF"
payload = {'q': query,'maxItems': maxItems, 'from': fromDate, 'to': toDate, 'siteSearch': siteSearch, 'type': fileType}
r = requests.get('http://arquivo.pt/textsearch', params=payload)
print("GET",r.url)
print("\n")
contentsJSon = r.json()
for item in contentsJSon["response_items"]:
title = item["title"]
url = item["linkToArchive"]
time = item["tstamp"]
print(title)
print(url)
print(time)
Conta-me Histórias (Tell Me Stories)
The project Tell Me Stories is a project developed by researchers from the Laboratory of Artificial Intelligence and Decision Support (LIAAD - INESCTEC) and affiliated to the institutions University of Beira Interior, Center for Research in Intelligent Cities (CI2) of the Polytechnic of Tomar; University of Porto and University of Innsbruck. The project aims to offer users the possibility to revisit topics from the past through a Google-type interface, which, given a query, returns a temporal summarization of the most relevant news preserved by Arquivo.pt about that topic. A promotional video of the project can be viewed here.
Contributions
In recent years the increasing availability of online content has posed new challenges to those who want to understand the story of a given event. More recently, phenomena such as media bias, fake news and filter bubbles have further compounded the already existing difficulties in providing transparent access to information. Conta-me Histórias (Tell me Stories) emerges in this context as an important contribution for all those who want to have quick access to a historical overview of a given event by automatically creating summarized narratives from a high volume of data collected in the past. Its availability in 2018, is an important contribution for students, journalists, politicians, researchers, etc, to generate knowledge and verify facts in a quick way, from the consultation of automatically generated timelines but also by resorting to the consultation of web pages typically non-existent in the more conventional web, the web of the present.
Where can I find ContaMeHistorias.pt (Tell me Stories)?
The Tell Me Stories project is available since 2018 from the following pointers:
- ContaMeHistorias.pt User interface in English
- TemporalSummarizationFramework Python library
- ContaMeHistorias.pt front-end
- ContaMeHistorias.pt back-end
More recently, in September 2021, Arquivo.pt started to offer the Narrativa feature by providing an additional button on its interface that redirects users to the Conta-me Histórias website so that from this website users can automatically create temporal narratives on any topic. The Narrative feature is the result of the collaboration between the Conta-me Histórias team, winner of the Arquivo.pt 2018 Award and the Arquivo.pt team.
How does it work?
When a user enters a set of words about a topic in the Arquivo.pt search box and clicks on the Narrative button, they are directed to the Conta-me Histórias (Tell me Stories) service, which in turn automatically analyzes news from 24 websites archived by Arquivo.pt over time and presents the user with a chronology of news related to the searched topic.
For example, if we search for Jorge Sampaio and press the Narrative button…

Figure 1. Search for ‘Jorge Sampaio’ using the Narrative component of Arquivo.pt
…we will be directed to Conta-me Histórias (Tell me Stories), where we will automatically get a narrative of archived news. In the following figure it is possible to observe the timeline and the set of identified relevant news.
For the selection of the most relevant news we used YAKE! a relevant word extractor (developed by our research team), which in this context is used to select the most important excerpts of a news story (specifically its headlines) over time.
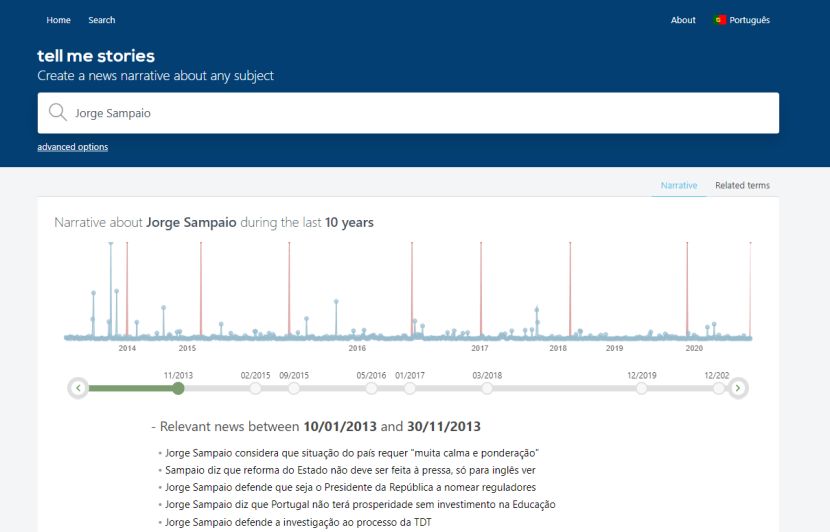
Figure 2. Search results for ‘Jorge Sampaio’ on Conta-me Histórias (Tell me Stories)
An interesting aspect of the application is that it facilitates access to the archived web page that names the title selected as relevant. For example, by clicking on the title “Jorge Sampaio formaliza apoio a Sampaio da Nóvoa” (Jorge Sampaio formalizes support for Sampaio da Nóvoa) the user can view the following web page:
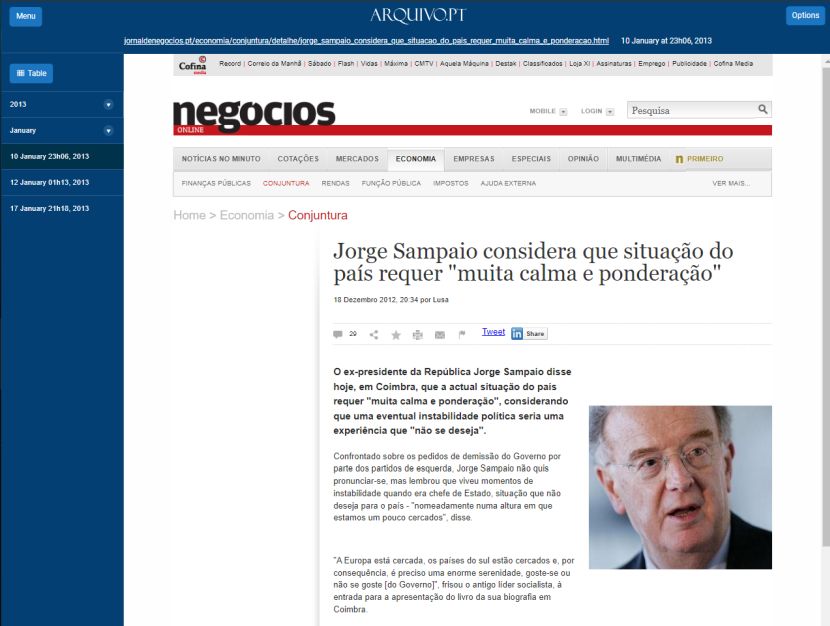
Figure 3. Web-archived news page linked from the Conta-me Histórias search results
At the same time, the user will be able to access a set of related terms with the search topic. In the figure below it is possible to observe, among others, the reference to the former president of the republic Mário Soares and Cavaco Silva, as well as to the former prime ministers Santana Lopes and Durão Barroso.
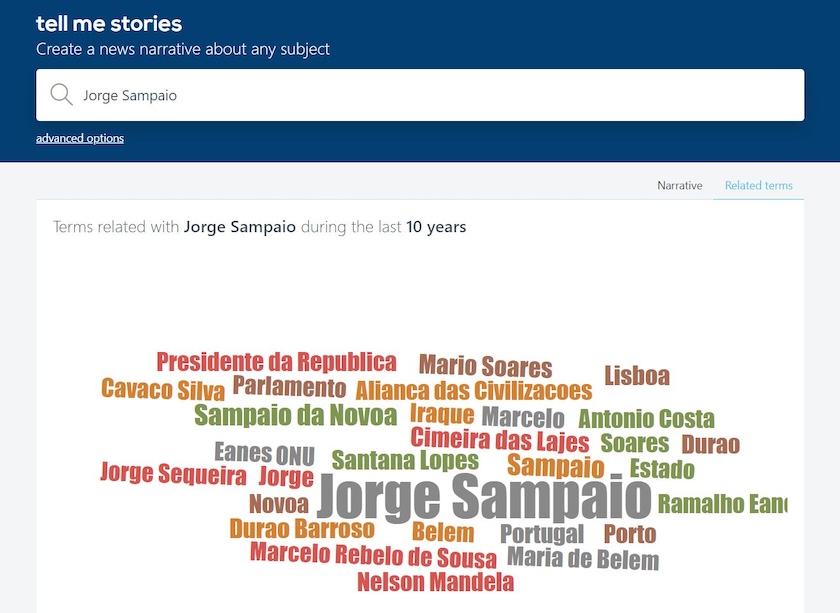
Figure 4. Word cloud with terms related to Jorge Sampaio research over 10 years
Conta-me Histórias (Tell me Stories) searches, analyzes and aggregates thousands of results to generate each narrative about a topic. It is recommended to choose descriptive words about well-defined themes, personalities or events to get good narratives. In the following section we describe how through the Python library users can interact and make use of the data from Tell Me Stories.
Installation
For the installation of the Tell Me Stories library you need to have git installed. Once git is installed run the following code:
!pip install -U git+https://github.com/LIAAD/TemporalSummarizationFramework
Usage
Definition of the search parameters
In the next code the user is asked to define the set of search parameters. The variable domains lists the set of 24 websites to be searched. An interesting aspect of this variable is the possibility for the user to define their own list of news sources. An interesting exercise is to define a set of media with a more regional scope, as opposed to the national media listed there.
The parameters from and to allow to establish the temporal spectrum of search. Finally, in the query variable, the user is invited to define the search topic (e.g. Jorge Sampaio) for which he wants to build a temporal narrative. Once the code is executed, the system starts the search process with Arquivo.pt. To do so, it uses the Arquivo.pt API (Full-text & URL search).
from contamehistorias.datasources.webarchive import ArquivoPT
from datetime import datetime
# Specify website and time frame to restrict your query
domains = [ 'http://publico.pt/', 'http://www.dn.pt/', 'http://dnoticias.pt/', 'http://www.rtp.pt/', 'http://www.cmjornal.pt/', 'http://www.iol.pt/', 'http://www.tvi24.iol.pt/', 'http://noticias.sapo.pt/', 'http://www.sapo.pt/', 'http://expresso.sapo.pt/', 'http://sol.sapo.pt/', 'http://www.jornaldenegocios.pt/', 'http://abola.pt/', 'http://www.jn.pt/', 'http://sicnoticias.sapo.pt/', 'http://www.lux.iol.pt/', 'http://www.ionline.pt/', 'http://news.google.pt/', 'http://www.dinheirovivo.pt/', 'http://www.aeiou.pt/', 'http://www.tsf.pt/', 'http://meiosepublicidade.pt/', 'http://www.sabado.pt/', 'http://economico.sapo.pt/']
params = { 'domains':domains, 'from':datetime(year=2011, month=1, day=1), 'to':datetime(year=2021, month=12, day=31) }
query = 'Jorge Sampaio'
apt = ArquivoPT()
search_result = apt.getResult(query=query, **params)
Browse the results from Arquivo.pt
The search_result object returns the total number of results obtained from the call to the Arquivo.pt API. The total number of results easily exceeds 10,000 entries. Such a volume of data is practically impossible to process by any user who wants to derive timely knowledge from it.
len(search_result)
Beyond the total number of results, the search_result object gathers extremely useful information for the next step of the algorithm, i.e., the selection of the most relevant news over time. Specifically, this object allows access to:
datetime: date of collection of the resource;domain: news source;headline: title of the news item;url: original url of the news item.
by executing the following code:
for x in search_result:
print(x.datetime)
print(x.domain)
print(x.headline)
print(x.url)
print()
Determination of important dates and selection of relevant keywords/headings
In the next step, the system uses the Tell Me Stories algorithm to create a summary of the most important news from the set of documents obtained from Arquivo.pt. Each time block determined as relevant by the system gathers a total of 20 news items. The various time blocks determined automatically by the system offer the user a narrative over time.
from contamehistorias import engine
language = "pt"
cont = engine.TemporalSummarizationEngine()
summ_result = cont.build_intervals(search_result, language, query)
cont.pprint(summ_result)
Search statistics
The following code gives access to a set of global statistics, namely the total number of documents, domains, as well as the total execution time of the algorithm.
print(f"Número total de documentos: {summ_result['stats']['n_docs']}")
print(f"Número total de domínios: {summ_result['stats']['n_domains']}")
print(f"Tempo total de execução: {summ_result['stats']['time']}")
To list all domains run the following code:
for domain in summ_result["domains"]:
print(domain)
Search results for Narrative
Finally, the following code uses the variable summ_result ["results"] to display the results generated with the information necessary to produce a timeline, namely, the time period of each news block, the news itself (a set of 20 relevant news per time block), the date of collection, the news source, the url (link to the original web page) and the full title of the news.
for period in summ_result["results"]:
print("--------------------------------")
print(period["from"],"until",period["to"])
# selected headlines
keyphrases = period["keyphrases"]
for keyphrase in keyphrases:
print("headline = " + keyphrase.kw)
# sources
for headline in keyphrase.headlines:
print("Date", headline.info.datetime)
print("Source", headline.info.domain)
print("Url", headline.info.url)
print("Headline completa = ", headline.info.headline)
print()
Conclusions
The web is now considered an essential communication tool. Web archives emerge in this context as an important resource for the preservation of content published there. Although their use is dominated by researchers, historians or journalists, the large volume of data available on our past makes this type of infrastructure a highly valuable and extremely useful resource for ordinary users. However, widespread access to this type of infrastructure requires other tools to meet the information needs of the user, while reducing the constraints associated with the exploitation of high volumes of data by non-specialist users.
In this tutorial, we exemplified how to automatically create temporal summaries from events collected in the past using data obtained from Arquivo.pt and the application of the temporal summarization library Conta-me Histórias (Tell me Stories) . The tutorial presented here is a first step in an attempt to show those interested in the subject how any user can, with minimal programming concepts, make use of existing APIs and libraries to extract knowledge from a large volume of data in a short time.
Awards
The Conta-me Histórias project was the winner of the Arquivo.pt Award 2018 and the winner of the Best Demo Presentation at the 39th European Conference on Information Retrieval (ECIR’19).
Bibliography
-
Campos, R., Pasquali, A., Jatowt, A., Mangaravite, V., Jorge, A. (2021). Automatic Generation of Timelines for Past-Web Events. In Gomes, D., Demidova, E., Winters, J., Risse, T. (Eds.), The Past Web: Exploring Web Archives (pp. 225-242). pdf
-
Campos, R., Mangaravite, V., Pasquali, A., Jorge, A., Nunes, C. and Jatowt, A. (2020). YAKE! Keyword Extraction from Single Documents using Multiple Local Features. In Information Sciences Journal. Elsevier, Vol 509, pp 257-289, ISSN 0020-0255. pdf
-
Pasquali, A., Mangaravite, V., Campos, R., Jorge, A., and Jatowt, A. (2019). Interactive System for Automatically Generating Temporal Narratives. In: Azzopardi L., Stein B., Fuhr N., Mayr P., Hauff C., Hiemstra D. (eds), Advances in Information Retrieval. ECIR’19 (Cologne, Germany. April 14 – 18). Lecture Notes in Computer Science, vol 11438, pp. 251 - 255. Springer. pdf
-
Gomes, D., Web archives as research infrastructure for digital societies: the case study of Arquivo.pt, Archeion 123 , 2022. pdf
-
Gomes, D., Demidova, E., Winters, J., Risse, T. (Eds.), The Past Web: Exploring Web Archives, Springer 2021. pdf
-
Gomes, D., and Costa M., The Importance of Web Archives for Humanities, International Journal of Humanities and Arts Computing, April 2014. pdf.
-
Sawood Alam, Michele C. Weigle, Michael L. Nelson, Fernando Melo, Daniel Bicho, Daniel Gomes, MementoMap Framework for Flexible and Adaptive Web Archive Profiling In Proceedings of Joint Conference on Digital Libraries 2019, Urbana-Champaign, Illinois, US, June 2019. pdf.
-
Costa M., Information Search in Web Archives, PhD thesis, Universidade de Lisboa, December 2014. pdf
-
Mourão A., Gomes D., The Anatomy of a Web Archive Image Search Engine. Technical Report, Arquivo.pt. Lisboa, Portugal, dezembro 2021. pdf